低成本复刻别人的AI?什么是大模型蒸馏技术?
原创
低成本复刻别人的AI?什么是大模型蒸馏技术?
原创
fanstuck
修改于 2026-06-05 09:26:33
修改于 2026-06-05 09:26:33

引言
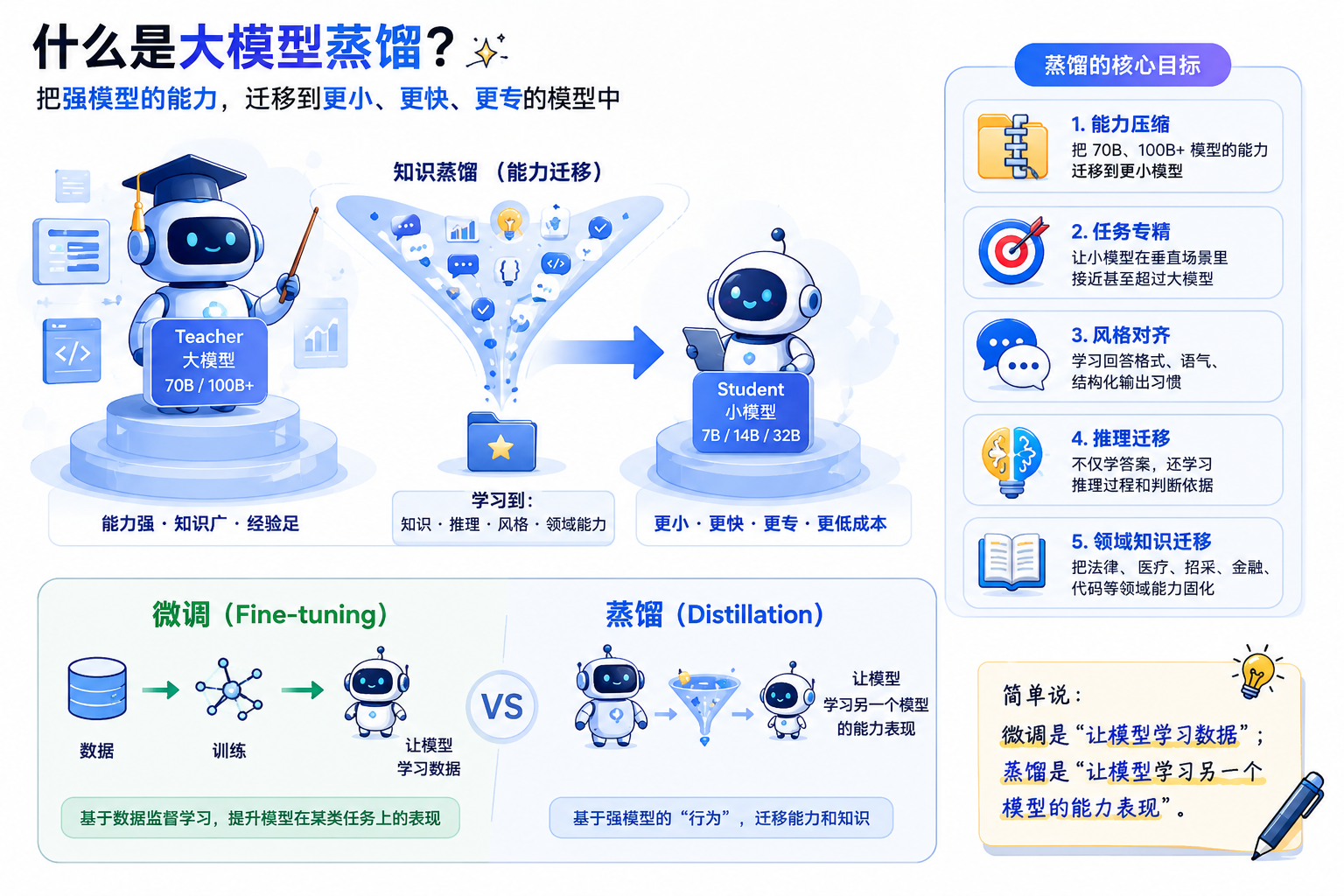
“大模型蒸馏”可以把它理解为:用一个能力更强、更贵、更慢的大模型当老师,让一个更小、更便宜、更可控的模型学习它的回答方式、任务能力、推理风格和领域知识。
但这里要先提醒一句:问到“如何蒸馏别人的 AI 问答”,技术上确实存在,但合规边界非常重要。可以做的是:基于授权模型、公开许可数据、自己业务数据、用户授权问答、企业内部沉淀问答来做蒸馏。需要谨慎甚至不能做的是:批量抓取第三方商业 AI 输出、绕过限制、用对方输出训练竞争模型。例如 OpenAI 的使用条款明确限制使用其输出开发与 OpenAI 竞争的模型,也禁止绕过限速或保护措施。
我是 Fanstuck,一位长期活跃在 AI 大模型、知识图谱、智能体(Agent)与数据工程 领域的探索者和实践者。我的写作不止于讲解技术,更关注 如何让复杂的技术知识真正“被理解、被应用”。因此,你会在我的文章里看到不仅有代码与实验,还有贴近行业场景的实战案例和趋势解读。致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。如果你对大模型的创新应用、AI技术发展以及实际落地实践感兴趣的话,敬请关注。
一、什么是大模型蒸馏?
传统知识蒸馏最早是模型压缩技术:有一个大模型 Teacher,一个小模型 Student。Teacher 输出结果,Student 学习 Teacher 的行为。
到了大模型时代,蒸馏不只是“压缩模型”,而是变成了一套能力迁移方法。现在的大模型蒸馏通常包括几类目标:
- 能力压缩:把 70B、100B+ 模型的能力迁移到 7B、14B、32B 模型。
- 任务专精:让小模型在某个垂直场景里接近甚至超过通用大模型。
- 风格对齐:学习某种回答格式、语气、结构化输出习惯。
- 推理迁移:不仅学答案,还学推理过程、解题步骤、判断依据。
- 领域知识迁移:把法律、医疗、招采、金融、代码等领域能力固化到学生模型中。
2024 年的 LLM 知识蒸馏综述把大模型蒸馏总结为三个核心方向:算法、能力、垂直化应用,并强调蒸馏已经成为把强模型能力迁移到开源模型、压缩模型、自我提升的重要方法。
简单说:微调是“让模型学习数据”; 蒸馏是“让模型学习另一个模型的能力表现”。
二、蒸馏和普通微调有什么区别?
很多人会把 SFT 微调和蒸馏混在一起。它们确实经常一起出现,但重点不同。
对比项 | 普通监督微调 SFT | 大模型蒸馏 |
|---|---|---|
数据来源 | 人工标注、业务数据、已有问答 | Teacher 模型生成的问答、解释、偏好、推理 |
学习目标 | 学习标准答案 | 学习 Teacher 的能力、风格、判断路径 |
典型形式 | instruction → answer | instruction → teacher answer / rationale / preference |
成本 | 人工标注成本高 | 调用 Teacher 成本高,但标注成本低 |
风险 | 数据质量不足 | Teacher 错误、幻觉、偏见会被复制 |
适合场景 | 任务边界明确 | 想迁移复杂能力或快速构造训练集 |
举个法规问答的例子:
普通 SFT 数据可能是:
{
"instruction": "服务费预算不足100万元的咨询服务是否属于政府采购?",
"output": "需要结合采购主体、资金来源、采购目录和限额标准判断。"
}蒸馏数据则可能是:
{
"instruction": "服务费预算不足100万元的咨询服务是否属于政府采购?",
"teacher_answer": "结论:不能仅凭预算金额判断是否属于政府采购。需要先判断采购主体是否为国家机关、事业单位或团体组织,再判断资金来源是否为财政性资金,最后结合集中采购目录和采购限额标准……",
"rationale": "判断路径:主体 → 资金 → 目录/限额 → 采购方式适用条件。",
"student_target": "按结论、依据、推理、风险提示四段式回答。"
}后者学到的不只是“答案”,还包括判断框架和输出范式。
三、大模型蒸馏主要有哪些技术路线?
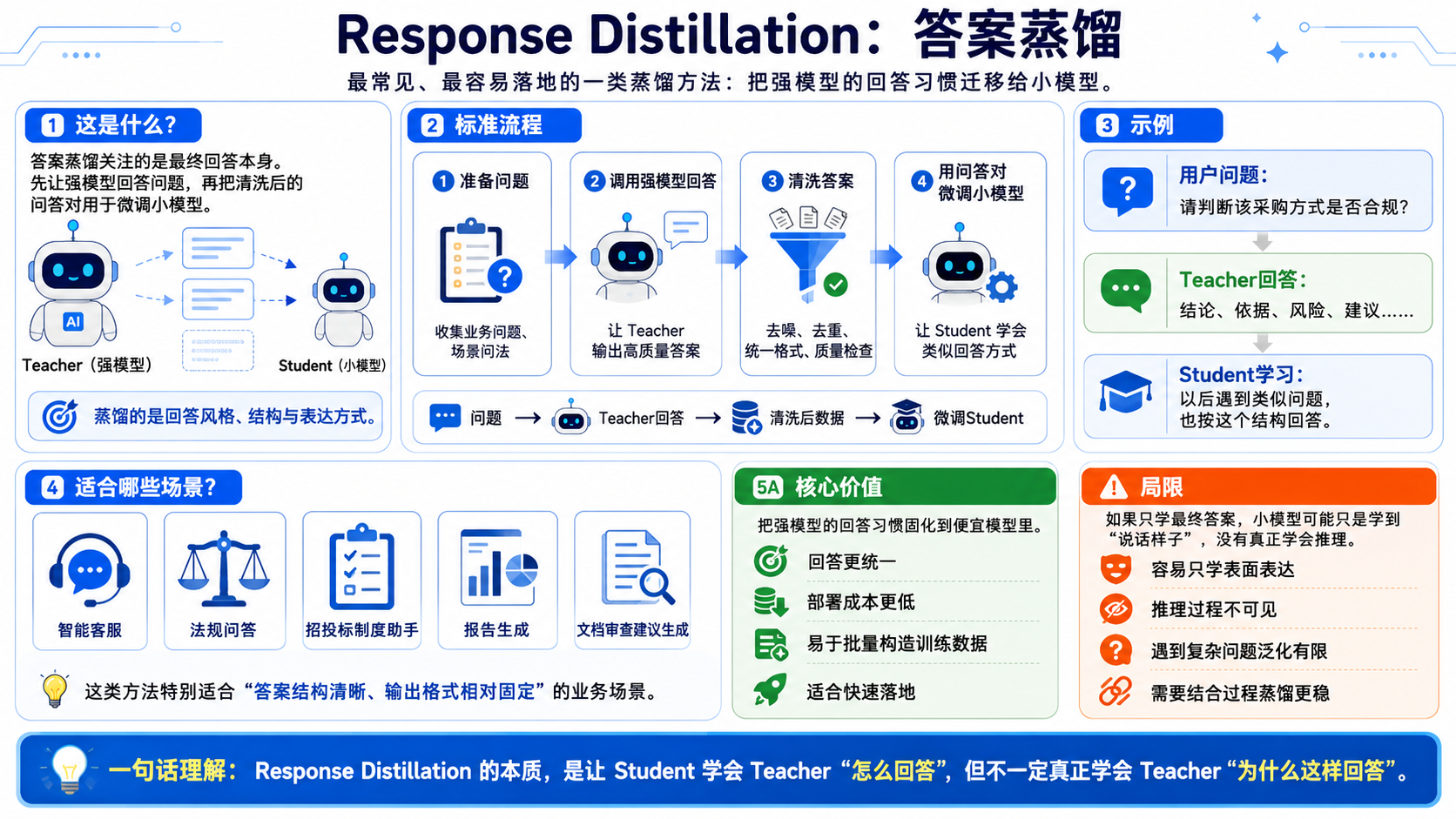
3.1. Response Distillation:答案蒸馏
这是最常见、最容易落地的一类。
流程是: 准备问题 → 调用强模型回答 → 清洗答案 → 用问答对微调小模型
例如:
用户问题:请判断该采购方式是否合规? Teacher回答:结论、依据、风险、建议…… Student学习:以后遇到类似问题也按这个结构回答。
这种方法适合做:智能客服、法规问答、招投标制度助手、报告生成、文档审查建议生成。
它的核心价值是:把强模型的回答习惯固化到便宜模型里。
但缺点也明显:如果只学最终答案,小模型可能只是学到“说话样子”,没有真正学会推理。
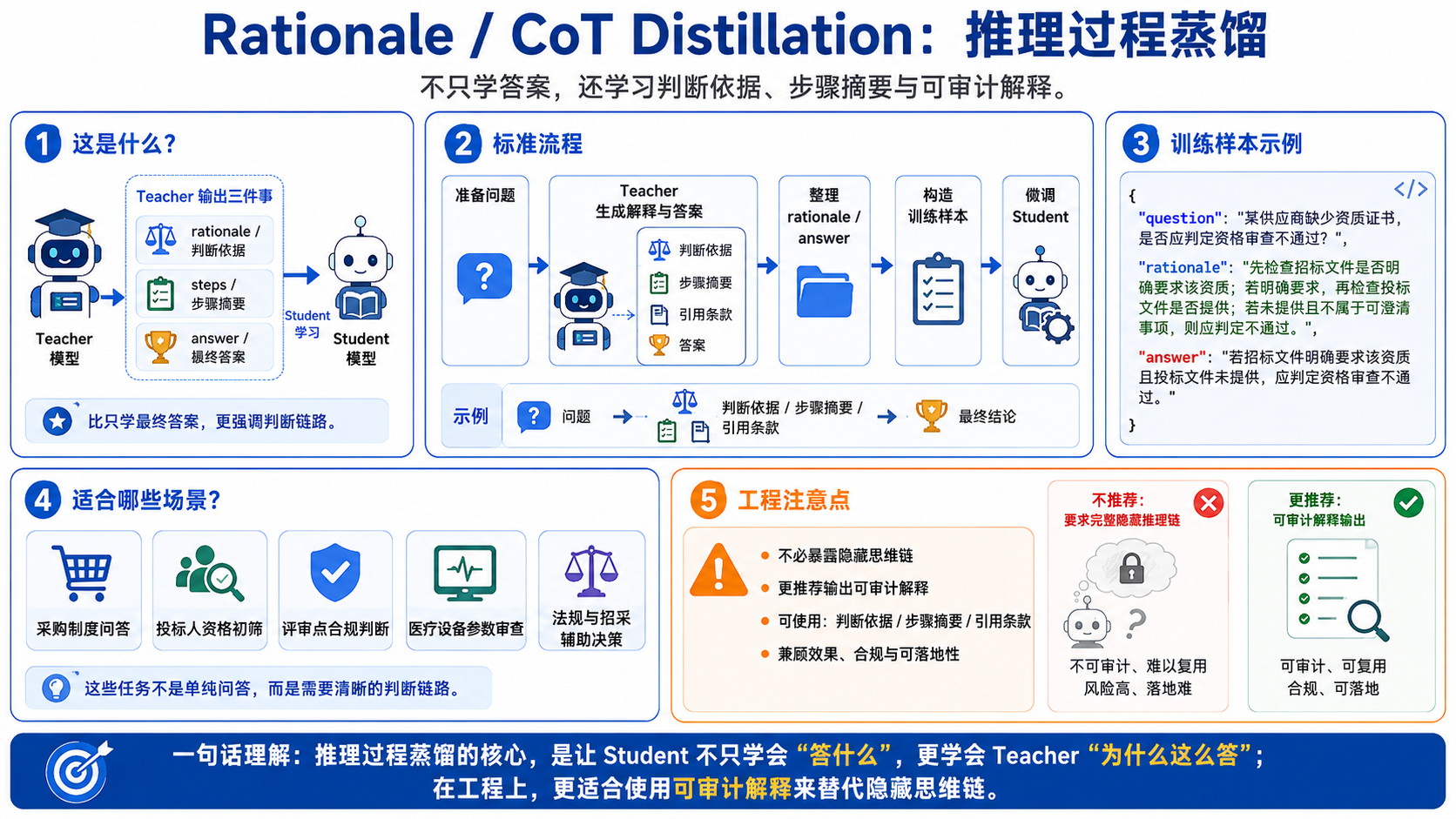
3.2. Rationale / CoT Distillation:推理过程蒸馏
这类方法不只让 Teacher 给答案,还让 Teacher 给出解释、判断依据、步骤。Google 的 “Distilling step-by-step” 研究就提出:利用大模型生成的 rationales 作为额外监督,可以让更小的模型用更少数据取得更好表现。
形式大概是:
{
"question": "某供应商缺少资质证书,是否应判定资格审查不通过?",
"rationale": "先检查招标文件是否明确要求该资质;若明确要求,再检查投标文件是否提供;若未提供且不属于可澄清事项,则应判定不通过。",
"answer": "若招标文件明确要求该资质且投标文件未提供,应判定资格审查不通过。"
}比如:采购制度问答、投标人资格初筛评、审点合规判断、医疗设备参数审查。因为这些任务不是单纯问答,而是要有判断链路。
不过这里要注意:很多商业模型不会允许你拿完整隐藏推理链做训练。工程上更推荐让 Teacher 输出可审计解释,例如“判断依据”“步骤摘要”“引用条款”,而不是要求暴露内部思维过程。
3.3.Logits Distillation:软标签蒸馏
传统蒸馏里,Teacher 不只给最终答案,还会给每个 token 的概率分布,也就是 logits。Student 学习这些“软标签”。
比如 Teacher 认为下一个词:
合规:0.72 不合规:0.18 待复核:0.10
这种概率信息比单纯答案更丰富。
但在大模型应用里,logits 蒸馏有两个问题:
- 很多闭源 API 不提供完整 logits。
- 长文本生成任务里 token-level 蒸馏成本很高。
所以在真实业务里,问答蒸馏、解释蒸馏、偏好蒸馏更常见。
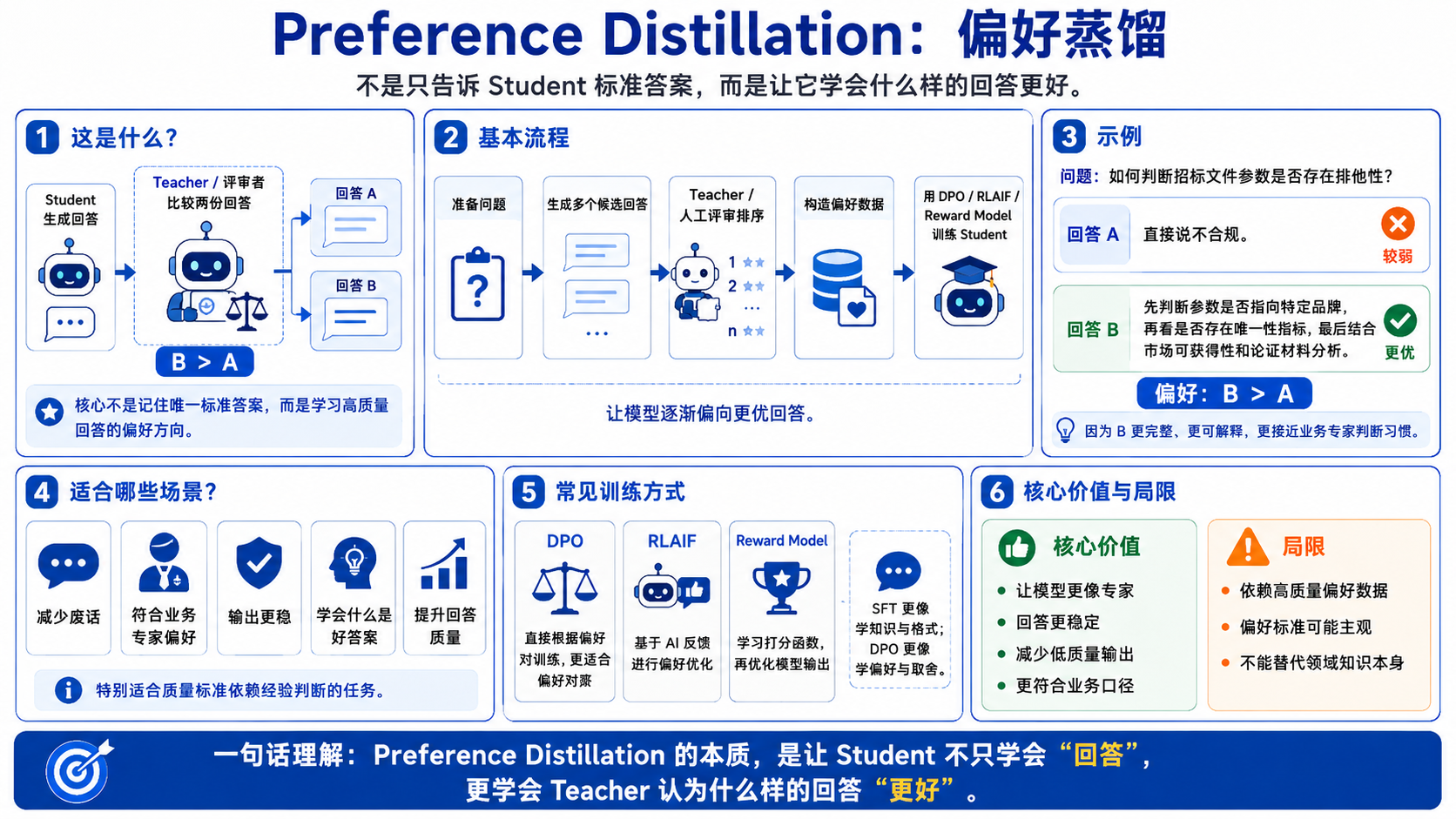
3.4.Preference Distillation:偏好蒸馏
这类方法不是只告诉 Student “标准答案是什么”,而是告诉它:A 回答比 B 回答更好。
例如同一个问题,Teacher 或人工评审给出排序:
问题:如何判断招标文件参数是否存在排他性? 回答A:直接说不合规。 回答B:先判断参数是否指向特定品牌,再看是否存在唯一性指标,最后结合市场可获得性和论证材料分析。 偏好:B > A
然后用 DPO、RLAIF、Reward Model 等方式训练模型,让它更偏向高质量答案。
适合场景:让模型减少废话、让模型更符合业务专家偏好、让模型输出更稳、让模型学会“什么是好答案”。
OpenAI 的开发文档也把 SFT、DPO 等微调方式区分为不同用途,DPO 更适合偏好对齐类任务,而不是简单记忆知识。
3.5.Self-Instruct:自指令生成蒸馏
Self-Instruct 是大模型蒸馏里非常经典的一条路线。它的核心思路是:让强模型自己生成大量任务指令、输入和输出样本,用来训练另一个模型。Self-Instruct 论文展示了这种近乎无需人工标注的指令生成方法,可以显著提升模型的指令遵循能力。
流程是:
少量种子任务→ Teacher 扩展生成更多任务→ Teacher 为任务生成答案→ 去重、过滤、质量检查→ 微调 Student
斯坦福 Alpaca 就是一个经典案例:它基于 LLaMA 7B,用 text-davinci-003 按 Self-Instruct 风格生成了 52K 条 instruction-following 数据进行训练。
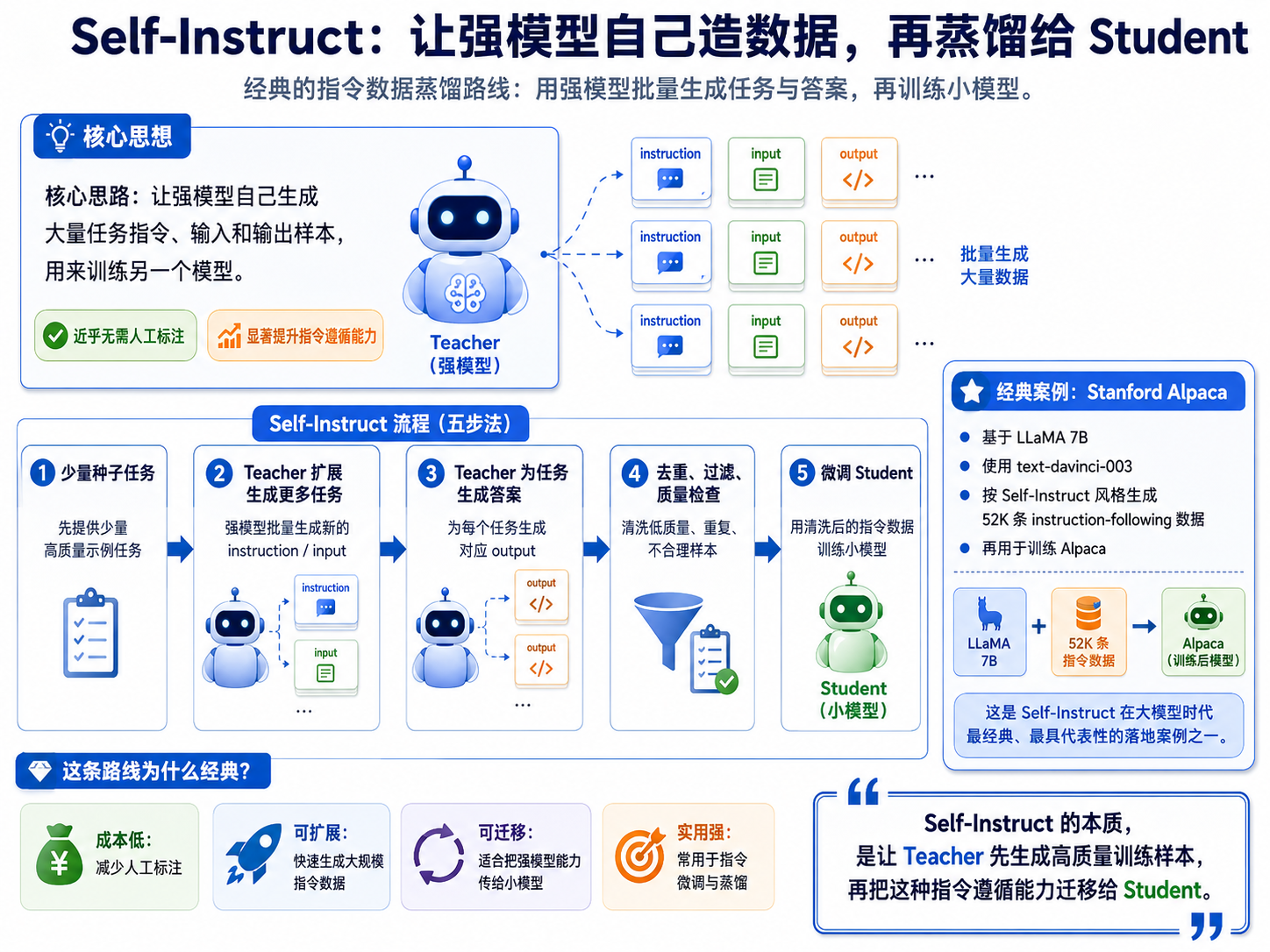
这条路线对企业很有吸引力,因为很多企业没有大量标注数据,可以先用高质量种子样本扩展训练集。
比如你做“招标文件解读助手”,可以准备 100 条高质量种子问题:
3.6.Tool / Agent Behavior Distillation:工具调用与 Agent 行为蒸馏
这是现在企业应用里越来越重要的一类。不是只蒸馏回答,而是蒸馏 Agent 的行为轨迹:
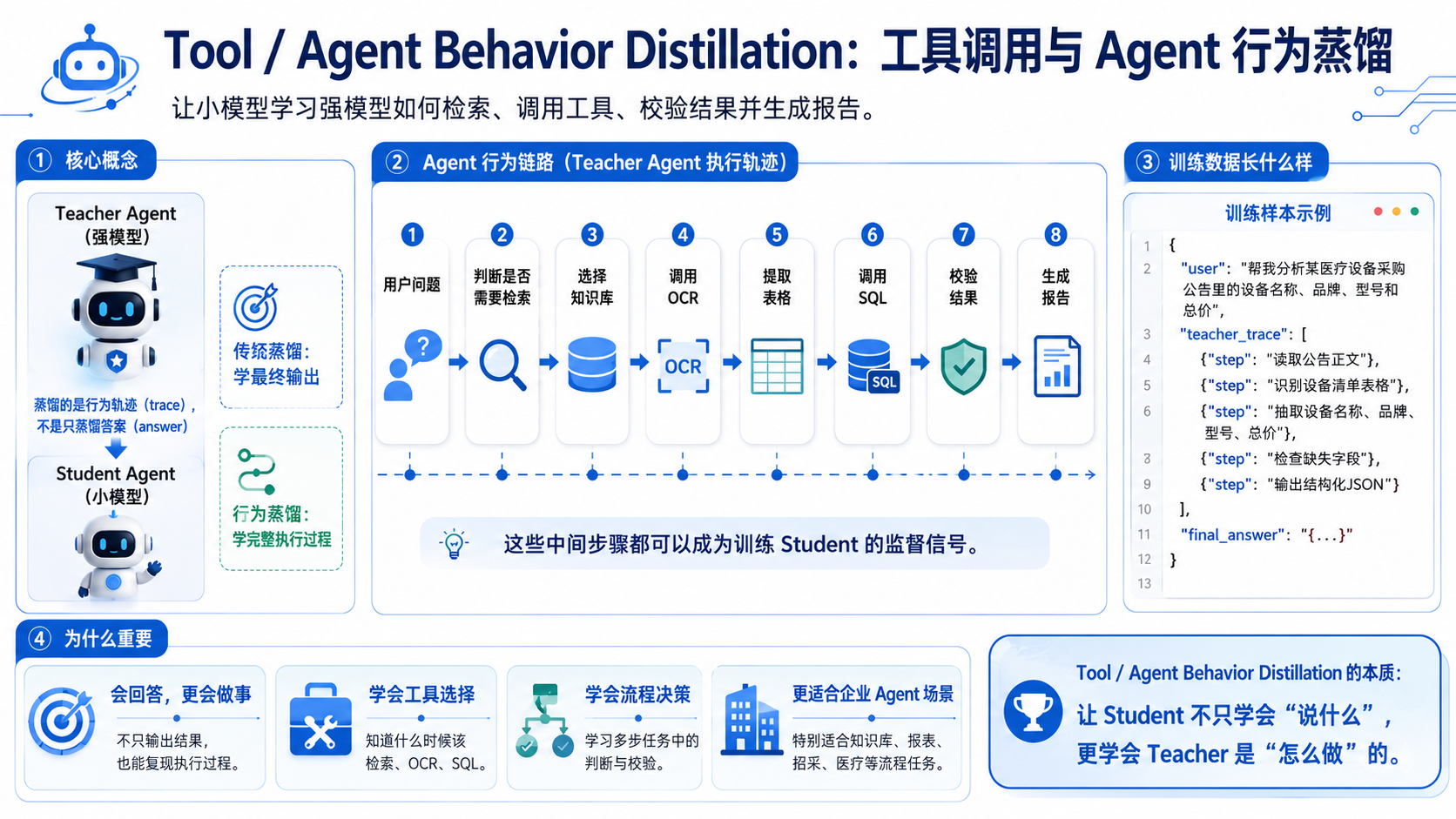
它蒸馏的不是“知识”,而是工作流能力。
四、如何蒸馏“AI ”?
这里分两种:合规做法和高风险做法。
4.1合规做法:蒸馏你有权使用的问答
比较稳妥的数据来源包括:
- 企业内部历史客服问答
- 自己系统产生的问答日志,且用户授权用于训练
- 专家标注问答
- 开源许可允许训练的数据集
- 自己调用模型生成的数据,但符合服务条款
- 自己部署的开源 Teacher 模型输出
- 企业采购的模型服务,合同允许用于训练/微调
- 自己业务文档 + Teacher 生成的解释性样本
工程流程通常是:
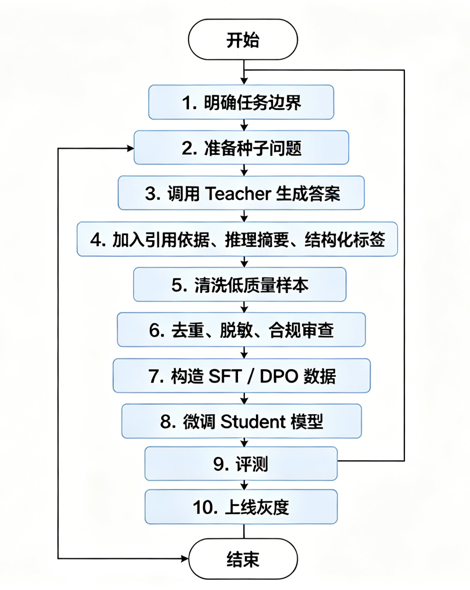
4.2高风险做法:批量蒸馏第三方商业 AI 输出
技术上,有些人会通过批量提问第三方 AI,收集回答,再训练自己的模型。这就是说的“蒸馏别人的 AI 问答”。从纯技术上看,会有设计大量问题→ 调用第三方 AI→ 收集回答→ 清洗格式→ 训练本地模型。
但这通常存在明显风险,比如违反平台服务条款、侵犯数据/IP 权益、绕过限速或保护机制、商业化时存在法律风险。还是建议不要想着“偷别人的模型能力”,而是“用合规 Teacher + 自有业务数据,蒸馏自己的业务能力”。这在企业里更可持续。
五、常见蒸馏数据格式
5.1. 普通 SFT 问答格式
适合大多数开源模型微调。
{
"instruction": "请判断该采购公告是否属于医疗设备成交公告。",
"input": "公告正文:……",
"output": "判断结果:是。理由:正文中出现设备名称、品牌、型号规格和成交金额……"
}5.2. ChatML 多轮格式
适合训练对话模型。
{
"messages": [
{
"role": "system",
"content": "你是采购公告分析助手,擅长识别医疗设备成交公告。"
},
{
"role": "user",
"content": "请判断以下公告是否为医疗设备成交公告:……"
},
{
"role": "assistant",
"content": "是。该公告包含设备名称、品牌、型号规格和总价,符合医疗设备成交公告的可提取标准。"
}
]
}5.3. 带推理摘要的蒸馏格式
适合复杂判断任务。
{
"instruction": "判断某供应商资格是否通过。",
"input": "招标文件要求:投标人须具备医疗器械经营许可证。投标文件内容:未提供该证书。",
"rationale": "招标文件明确要求该证书,投标文件未提供,且该材料属于资格性证明材料。",
"output": "不通过。原因:投标人未提供招标文件明确要求的医疗器械经营许可证。"
}5.4. 偏好数据格式
适合 DPO。
{
"prompt": "请判断该技术参数是否具有排他性。",
"chosen": "该参数存在较高排他性风险。判断依据包括:参数组合过于唯一、指向特定品牌、缺少充分论证材料……",
"rejected": "这个参数可能不太合适。"
}六、哪些场景特别适合大模型蒸馏?
6.1垂直行业问答
比如:政府采购法规问答、企业制度问答、金融风控解释、法务合同审查。
这些任务特点是:问题类型稳定,回答结构稳定,知识边界相对明确。
这类场景很适合蒸馏,因为你可以把专家经验沉淀成固定回答范式。
6.2结构化信息抽取
这类任务很适合蒸馏到小模型,因为它追求的是稳定、低成本、批量处理,不一定需要每次都调用最强模型。
尤其是 OCR 后的 Markdown、网页正文、公告正文、PDF 资料参数表,都可以构造成蒸馏样本。
6.3固定格式报告生成
比如:项目可研咨询报告、法规依据分析报告等。
这类任务的核心不是“模型要多聪明”,而是“格式要稳定、逻辑要完整、表达要专业”。
蒸馏后,小模型可以非常稳定地输出:一、结论,二、依据,三、分析过程,四、风险提示,五、建议
。
6.4分类与路由
比如多 Agent 系统里的意图识别:
价格咨询 → price-agent 市场分析 → market-agent 法律合规 → legal-agent 技术论证 → tech-agent 融资分析 → investment-agent
这种任务很适合用蒸馏小模型替代大模型,原因是任务简单、调用频繁、对延迟敏感。甚至可以不用大语言模型,用 BERT、RoBERTa、Qwen embedding + 分类头也可以。
大模型蒸馏真正适合的不是“复制一个通用大模型”,而是把大模型在某个业务链路里的高质量行为,压缩成一个更便宜、更稳定、更可控的专用模型。对于企业落地来说,它的价值不在炫技,而在降成本、提速度、稳格式、固化专家经验。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号