逆强化学习(IRL:模仿学习)的原理和步骤


IRL = 外层迭代反推 reward + 内层跑 RL 求状态分布,核心是"专家做对了的事 reward 高,做错了 reward 低",但内外双层循环导致计算代价极高。
PART 01
核心原理
IRL 的核心问题是 从专家轨迹反推 reward 函数 ,再基于反推的 reward 训练 RL 策略。与 GAIL 相比,IRL 学到的是 可解释的 reward 函数 ,而 GAIL 学到的是隐式的判别器信号。
核心假设 (最大熵 IRL):
专家轨迹的概率正比于累计 reward 的指数:
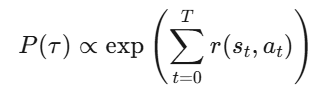
通过最大化专家轨迹的似然,反推每个 $(s,a)$ 的 reward 权重。
PART 02
具体步骤(以 MaxEnt IRL 为例)
算法:MaxEnt IRL
输入:专家轨迹 {τ_expert},特征函数 Φ(s,a)
输出:Reward 权重 w,策略 π
1. 初始化:
- w = 0(reward 权重向量)
- r(s,a) = w · Φ(s,a) # 线性 reward 函数
2. while w 未收敛: # IRL 外循环
# --- 步骤1:求期望特征 ---
# 计算专家轨迹的平均特征
μ_expert = E[Φ(s,a)]_expert
# --- 步骤2:求状态分布(需用 RL)---
# 在当前 reward r 下运行 RL,得到最优策略 π_w
π_w = run_RL(r, env) # 通常用价值迭代或策略梯度
μ_π = E[Φ(s,a)]_π_w # 策略访问状态的平均特征
# --- 步骤3:更新 reward 权重 ---
# 梯度方向:让专家特征高于策略特征
gradient = μ_expert - μ_π
w = w + α * gradient # α 是学习率
3. 用最终 w 构建 reward:r(s,a) = w · Φ(s,a)
在该 reward 上重新训练 RL 策略
4. 返回 w, π为什么需要内外两层循环
这是 IRL 最贵的部分:
循环 | 内容 | 作用 |
|---|---|---|
外层(IRL) | 更新 reward 权重 w | 拟合专家分布 |
内层(RL) | 求当前 reward 下的最优策略和状态分布 | 计算梯度方向 |
内层每次都要跑 RL(价值迭代或策略梯度),代价极高——这就是为什么 MaxEnt IRL 在大规模问题上是不可行的。
IRL 内层循环:
核心目标
给定当前 reward 函数 $r(s,a)$,求出 在该 reward 下最优的策略 $\piw$, 以及策略访问状态分布 $\mu\pi = E{\piw}[\Phi(s,a)]$。
两种实现路径
- 路径一:基于价值的迭代(适合离散、小状态空间)
原理:用动态规划求最优 Q 函数,再导出策略。
算法:内层 RL(基于价值迭代)
输入:reward 函数 r(s,a),状态转移 P,环境
输出:最优策略 π,最优状态访问分布 μ_π
1. 初始化:
Q(s,a) = 0,V(s) = 0 for all s,a
μ_π(s,a) = 0 for all s,a # 状态访问计数
2. 迭代求最优 Q 函数(策略评估 + 策略提升):
for iter = 1 to MAX_ITER:
# 策略评估:求 V(s) = max_a Q(s,a)
for each (s,a):
Q(s,a) = r(s,a) + γ * Σ_s' P(s'|s,a) * V(s')
V(s) = max_a Q(s,a)
# 提取贪心策略
π(a|s) = 1 if a = argmax_a Q(s,a) else 0
3. 求状态访问分布 μ_π(关键步骤):
# 方法:求稳态分布 or 访问频率
d_0(s) = 初始状态分布
for t = 1 to T: # 向前仿真 T 步
for each (s,a):
d_t(s') += d_{t-1}(s) * P(s'|s,a) * π(a|s)
# 累计访问
μ_π(s,a) += d_t(s) * π(a|s)
4. 返回 π, μ_π- 路径二:基于策略的采样(适合连续、大状态空间)
原理:用 PPO/SAC 等策略梯度算法采样轨迹,直接估计 $\mu_\pi$。
两种路径对比
价值迭代 | 策略梯度 | |
|---|---|---|
适用场景 | 离散/小规模状态空间 | 连续/大规模状态空间 |
精度 | 精确(动态规划) | 近似(采样估计) |
计算成本 | 高(需遍历所有状态) | 中(采样 + NN 训练) |
是否能在线 | 离线 | 可在线 |
IRL 方法族对比
方法 | reward 形式 | 内层优化 | 复杂度 |
|---|---|---|---|
MaxEnt IRL(Ziebart 2008) | 线性 w⋅Φ(s,a) | 需跑完整 RL | O(T2)O(T2) |
IRL with NN(Finn 2016) | 神经网络 r(s,a) | 需跑 RL | 极高 |
最大边际 IRL(Ng & Russell 2000) | 线性 w⋅Φ | 线性规划 | 中等 |
博弈论 IRL(Abbeel & Ng 2004) | 线性 w⋅Φ | 策略迭代 | 中等 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号