周三头条|从 Claude 案例看 Coding Agent 的计划层设计
原创
周三头条|从 Claude 案例看 Coding Agent 的计划层设计
原创
七牛开发者
发布于 2026-06-03 15:56:04
发布于 2026-06-03 15:56:04
大家用 Coding Agent 的时候,可能会遇到一种情况:代码能跑,测试也能过,但最后做出来的东西,和你真正想要的结果有偏差。
Anthropic 最近发了一篇 CodeRabbit 的案例,刚好把这个问题讲得很具体。
CodeRabbit 背景
CodeRabbit 是一家 AI Code Review 平台。现在每周会 Review 超过 200 万个 PR,覆盖 15,000 多个客户。正是这个面对大量 AI 生成代码的场景,让 CodeRabbit 观察到一个现象:很多程序的失败并不发生在“代码写不出来”,而是发生在更上游的需求理解阶段。
需求解析和实现设计
很多时候,我们在给 Coding Agent 下任务时,会下意识地默认很多上下文是“大家都懂的”,不需要再单独交代。比如这个功能为什么要做,面向谁用,边界条件是什么,哪些东西不能改,哪些地方只是临时方案。这些信息如果没有写进需求里,Agent 就只能自己补。
补得对,代码看起来很顺。补错了,后面可能就要返工。
CodeRabbit VP of AI David Loker 举了一个例子:做 Memory System 时,他告诉 Agent 这个系统要有“用户”的概念,也就是不同用户应该有各自的记忆。但他没有说清楚:用户要怎么登录、怎么进入系统。Agent 是把底层功能做出来了,但使用方式却是“调用时传入 user token”。问题是,产品里没有登录页,也没有获取 token 的入口。系统看起来能跑,但真实用户根本不知道从哪里开始用。
上面这个问题的重点不在代码能力,而在计划阶段漏掉了关键假设。
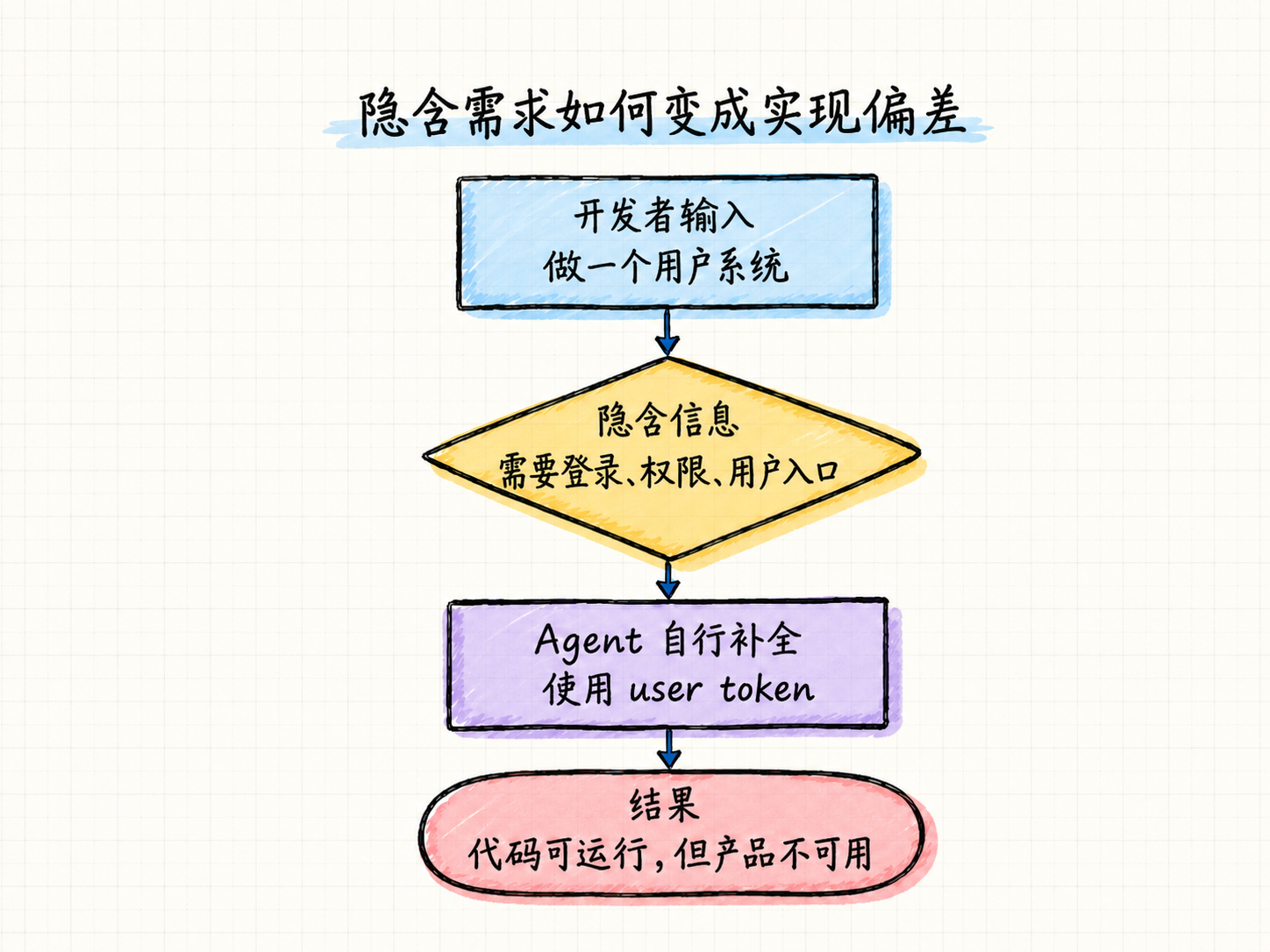
所以 CodeRabbit 的做法,是在真正生成代码之前,先加一层“计划层”。
这层系统会先分析需求,暴露隐含假设,整理约束,再生成一个结构化的 coding plan。这个计划会先交给团队 Review,确认方向、边界和验收标准都没有问题,再让 Claude Code 继续生成更细的实现计划。
你可以把它理解成一份面向 Agent 的协作式 PRD。
它不只是告诉 Agent “做什么”,还要说清楚“为什么做”“做到什么程度”“有哪些限制”“哪些地方需要团队确认”。
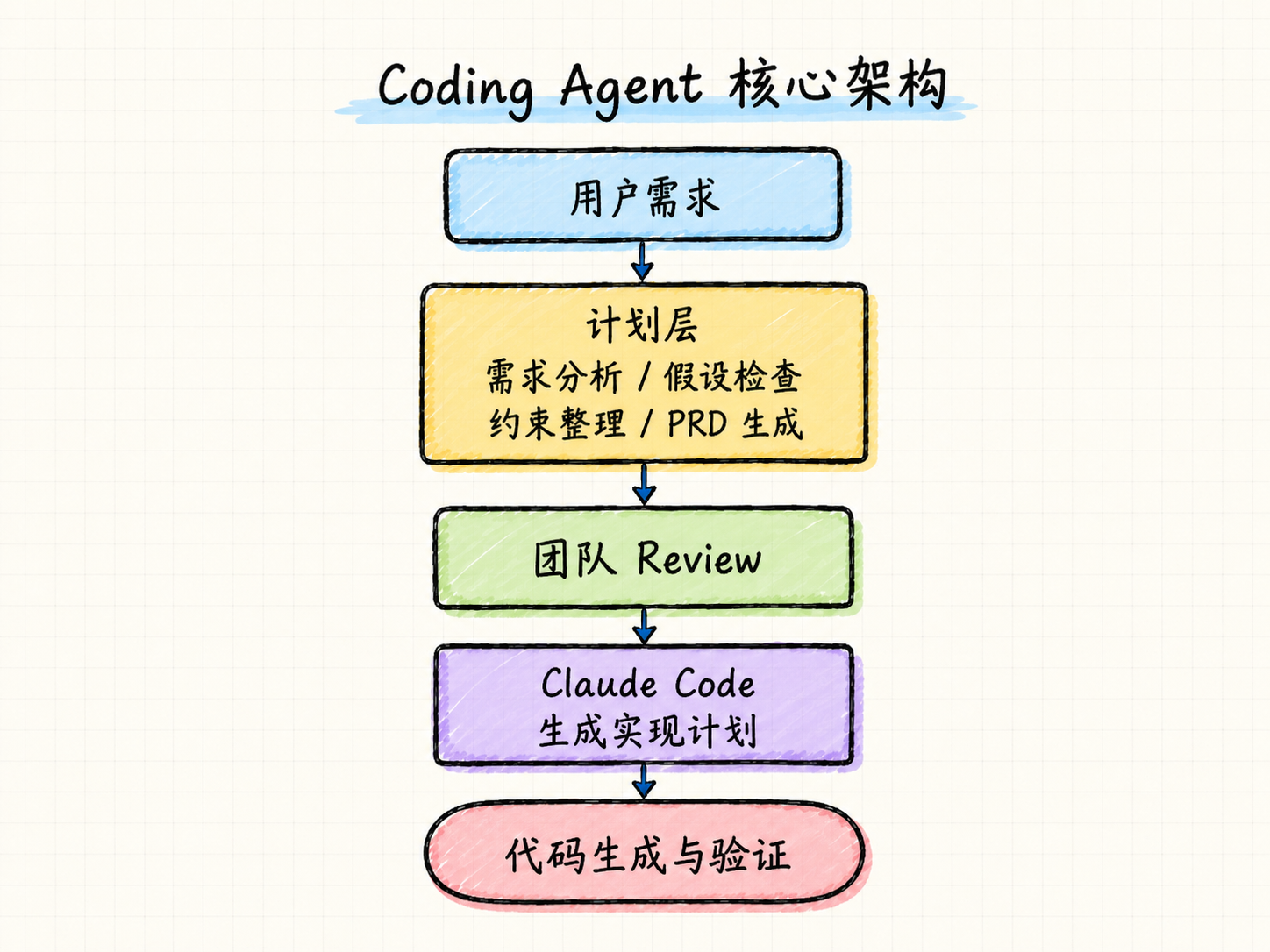
计划层把控质量
这个设计最关键的地方,是把计划本身变成了一个质量检查点。
在传统开发流程里,很多决策和问题在 Code Review 阶段才会暴露。但在 AI-native coding 流程里,一部分原本要到代码审查时才会被讨论的东西,会被提前放到计划层进行处理。团队不会等 Agent 把代码写完之后才判断方向对不对,而是在代码生成开始之前,先 Review 这份计划。
Loker 对这套系统的说法很明确:基于 Claude 生态构建,是一个团队级的规划系统。计划本身会成为质量门。如果一开始就能保证计划质量足够好,下游效果会非常明显,最终生成的代码质量也会更好。
这类质量门主要检查几个问题:
- 需求是否完整;
- 边界条件是否清楚;
- Agent 有没有做额外扩展;
- 哪些地方只是模型自行推断;
- 最终结果该如何验收。
CodeRabbit 也明确指出,这套规划系统并不是 Claude Code Plan Mode 的替代品。这个计划层的位置更靠前,是发生在 Claude Code 之前的高层编排,用来把方向收窄,把该显式说明的东西尽量说明白。
这也是 Coding Agent 系统里很容易被忽略的一点:Agent 写代码之前,需要先知道什么才算“写对”。
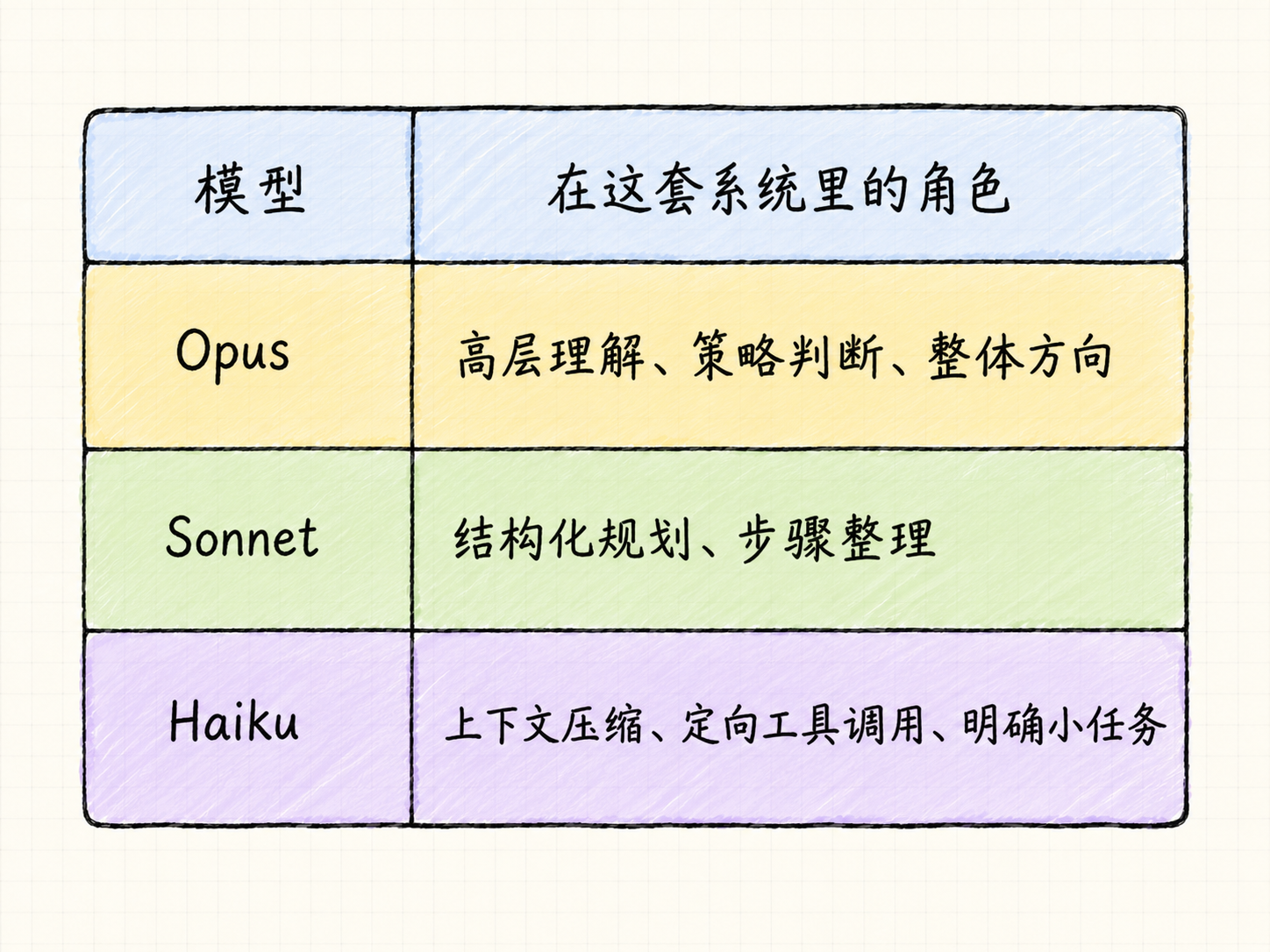
模型分工
在 CodeRabbit 工程实践中,Opus 模型会负责更高层的策略理解和方向判断;Sonnet 模型负责把结果整理成结构化计划;Haiku 模型处理更窄、更明确的任务,比如上下文压缩和定向工具调用。
它们的原则也很工程化:如果 Haiku 在某个任务上能达到 Sonnet 的效果,就用 Haiku;如果评估发现给 Opus 更多空间能提高计划质量,就让 Opus 处理更复杂的部分。
计划层的质量评估
CodeRabbit 原本就有比较成熟的代码评估体系,但计划本身的质量该怎么评估,是它们后来单独补上的一个模块。
一开始 CodeRabbit 依赖人工样例和人工检查,随后构建了一组 LLM judge,用来评价计划质量的不同维度。同时,因为计划最终会进入代码生成环节,它们还可以继续观察生成代码是否可用、是否出现额外范围、消耗了多少 token,并通过“有计划层”和“无计划层”的对比,判断计划层到底有没有带来收益。
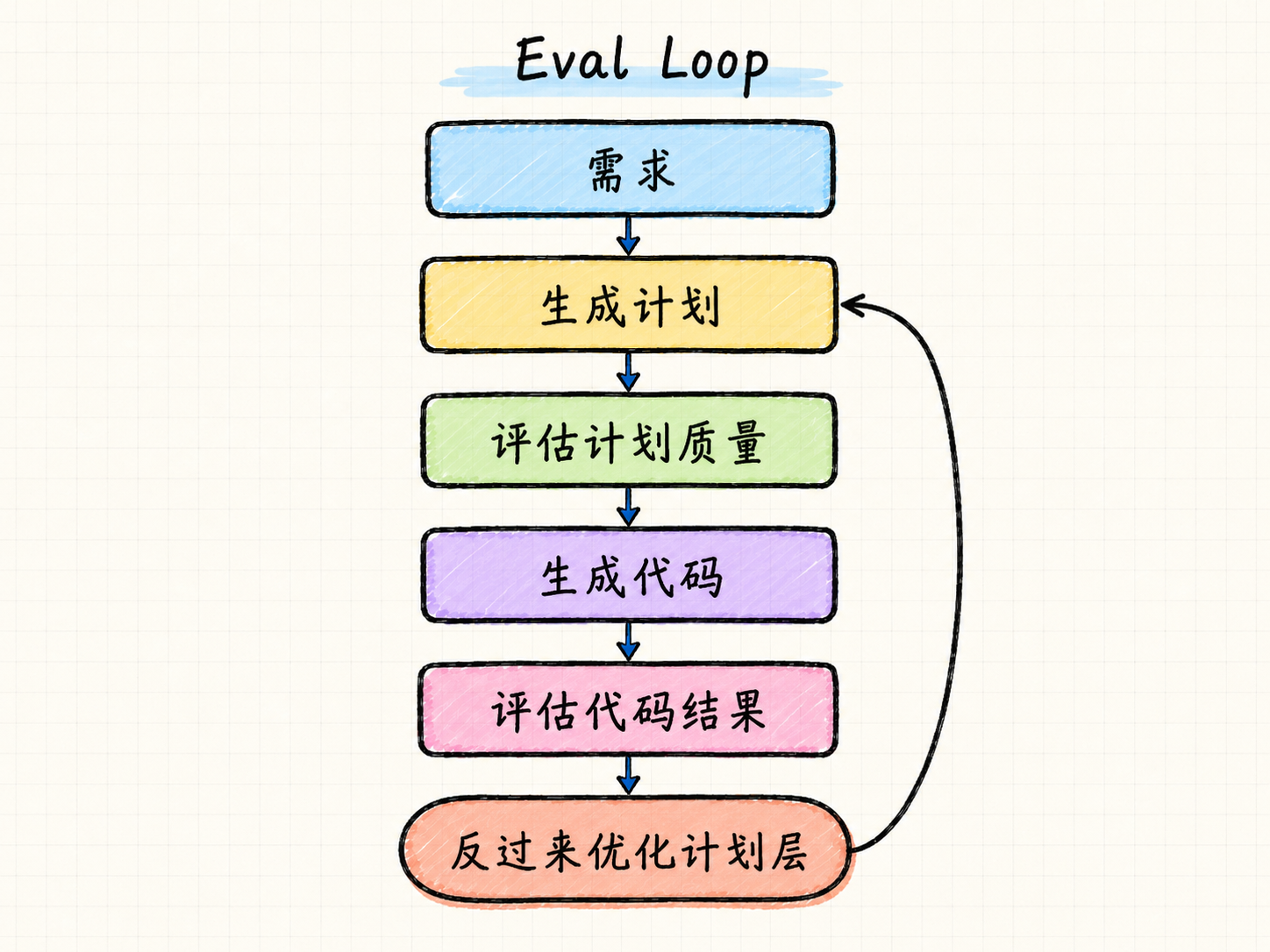
这里有一个需要解决的问题,那就是计划到底要写多细?
写得太细,代码库一变化,计划很快过期;写得太粗,又会给 Agent 留下太多自行补全的空间。CodeRabbit 的经验是,这个“合适的抽象层级”很难一次定准,需要靠持续评估和迭代慢慢找出来。
换句话说,计划层真正难的地方,不是把需求写得越完整越好,而是要判断哪些信息必须提前说清楚,哪些信息可以交给 Agent 在执行过程中处理。
从这个角度看,计划层更像是在做 Agent 执行前的信息压缩:把目标、边界、约束、验收方式这些会影响实现方向的关键变量提前挑出来,避免模型在关键问题上自行推断。
最佳实践
CodeRabbit 给了几个比较实用的检查问题:
第一,你到底想创造什么结果,又准备用什么方式衡量?这里不只是给 AI 写规格说明,还要定义你想要的 MPP,也就是 maximum possible product,可以理解成这个产品在理想情况下应该达到的上限。
第二,还有哪些假设没有被明确说出来?可以直接让 Claude 检查:这个计划里缺了什么?有没有哪些内容其实是隐含假设,但还没有变成明确规格?
第三,有哪些工作流或边缘情况容易被忽略?这类问题很适合交给 Claude 先做一轮检查,让它帮你找出那些你可能没有考虑到的场景。
第四,在正式交付之前,怎么判断输出结果确实符合最初意图?CodeRabbit 的建议是留下工作记录,把规划过程中产生的文档、决策和计划沉淀下来,后续可以复用,也可以作为回看和评估的依据。
这些问题如果留到代码生成之后再处理,成本就会高很多。毕竟真到了那个时候,Agent 可能已经沿着一个错误假设,把接口、数据结构、交互流程都写出来了。
小结
回到 CodeRabbit 这个案例,它真正值得借鉴的地方,是把 Coding Agent 的质量控制前移了。
过去我们更习惯在代码生成之后做 Review,看代码能不能跑、有没有 bug、是否符合规范。但在 Agent 参与开发之后,很多问题已经提前发生在计划阶段:目标理解偏了,假设补错了,边界没对齐,验收标准没写清楚。
当代码生成成本越来越低,真正贵的可能是朝错误方向快速推进。
计划层的意义,就是在 Agent 动手之前,先把这些会决定实现方向的信息处理干净。这样后面的代码生成,才更有可能变成有效产出。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号