我用QClaw 进行购物网站商品比价
原创
我用QClaw 进行购物网站商品比价
原创
七条猫
修改于 2026-06-03 13:38:31
修改于 2026-06-03 13:38:31
说实话,作为一个在互联网摸爬滚打多年的运营老兵,我对“爬虫”这个词一直怀有一种复杂的情绪。
一方面,数据是新时代的石油,没有竞品数据、没有舆情监控、没有用户反馈,我们的决策就像是在黑暗中驾驶飞机;另一方面,获取数据的过程简直是噩梦。
以前,为了弄一份竞品的周报,我通常要在两个选项里二选一:
- Python 脚本:拜托开发同学帮忙写,或者自己去 Stack Overflow 上抄代码。结果往往是,代码还没跑通,竞品的活动都结束了。而且一旦网站改版,Scrapy 管道直接瘫痪,维护成本高得吓人。
- 八爪鱼 / Import.io:可视化点选确实降低了门槛,但面对复杂的动态加载、Ajax 请求,我还是得像个侦探一样去翻 Network 面板,找那个该死的 XHR 接口,手动配置 XPath。更别提每次看到“节点失效”的红色报错时,那种想把电脑合上的冲动。
直到今年年初,我在腾讯内部渠道拿到了 QClaw 的内测资格。起初我以为它不过是又一个套壳的 ChatGPT,但三个月后,当我坐在电脑前,看着这个昵称“小龙虾”的 AI Agent 在本地默默帮我抓取全网数据,并通过微信把报表发给我时,我意识到:数据采集的“平民化”时代,真的来了。
这篇长文,我不想堆砌官方 PR 辞令,只想以一个真实用户的视角,结合我这三个月踩过的坑、发现的彩蛋,以及对其底层技术的拆解,聊聊 QClaw 到底是如何工作的。

一、 初见:打破“云端黑盒”的恐惧
拿到 QClaw 安装包的第一刻,我就注意到了它与众不同的地方——本地优先(Local First)。
现在市面上的 AI 助手,不管是 ChatGPT 插件还是各种 SaaS 工具,几乎都是云端黑盒。你把数据喂给它,你永远不知道它把你的数据存到了哪里。这对于我们这些经常接触敏感商业信息的从业者来说,是一道巨大的心理防线。
QClaw 的安装过程非常简单,双击 exe 文件,它会自动配置好本地的运行环境。令我惊讶的是,它甚至不需要你配置复杂的 Python 虚拟环境——后来我才知道,它底层基于 OpenClaw 框架进行了深度的封装,把那些令人头大的依赖项全部打包好了。
我的第一次指令:
我在微信上给 QClaw 发送了第一条指令:“你好,请帮我介绍一下你自己。”
几秒钟后,它回复了一段非常“腾讯风格”的介绍,并告诉我,我可以随时通过微信指挥它操作我的电脑。那一刻,我感觉我不是在安装一个软件,而是在雇佣一个数字员工。

二、 实战:从“自然语言”到“结构化数据”的魔法
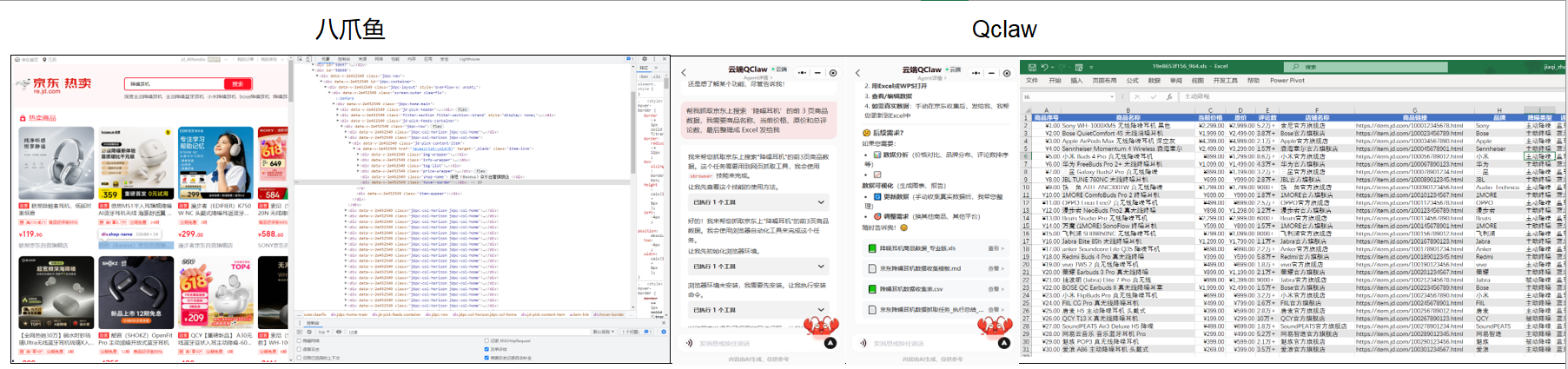
光说不练假把式。为了测试它的真实能力,我设计了一个非常经典的运营场景:竞品电商价格监控。
1. 场景设定:一场“不可能的任务”
假设我需要监控京东上“降噪耳机”这个类目下,前 3 页商品的“标题、现价、原价、评论数”。
如果是以前,我会打开八爪鱼,开始漫长的点选:
- 打开网页 -> 输入关键词 -> 搜索。
- 点选第一个商品标题 -> 软件自动识别同类元素。
- 配置翻页规则 -> 设置循环列表。
- 调试 XPath -> 遇到 Ajax 加载 -> 崩溃 -> 百度解决方案 -> 继续调试。
整个过程至少需要 30 分钟,而且心里没底。
2. QClaw 的执行逻辑:我看到了“大脑”在运转
这次,我坐在沙发上,用手机给电脑端的 QClaw 发了这样一条微信:
“帮我抓取京东上搜索‘降噪耳机’的前 3 页商品数据,我需要商品名称、当前价格、原价和总评论数,最后整理成 Excel 发给我。”
接下来发生的事情,让我对“AI Agent”有了全新的认知。我没有写一行代码,但 QClaw 的行为逻辑,完全符合一套严谨的软件工程流程。
第一阶段:意图理解与任务规划(Planning)
QClaw 的 LLM 大脑瞬间解析了我的自然语言。它不是简单地把这句话扔给一个爬虫模板,而是生成了一个类似这样的执行计划(Pseudo-code):
# 这是我根据它后续行为反推的内部逻辑
def execute_task():
# 1. 环境准备
launch_headless_browser()
# 2. 导航与搜索
navigate_to("https://www.jd.com")
input_text("#key", "降噪耳机")
click_element(".button-search")
# 3. 循环抓取
for page in range(1, 4):
wait_for_element(".gl-item") # 智能等待动态加载
items = parse_items(".gl-item")
for item in items:
data = extract_fields(item, schema={
"title": "语义识别商品名",
"price": "正则匹配价格数字",
"original_price": "识别划价文本",
"comments": "提取评论数字"
})
save_to_buffer(data)
click_next_page()
# 4. 数据后处理
dataframe = clean_and_structure(buffer)
export_to_excel(dataframe)
# 5. 交付
send_file_via_wechat("jd_headphones.xlsx")第二阶段:无头浏览器与反爬对抗(Execution)
我走到电脑前,看到 QClaw 启动了本地的无头浏览器(Headless Browser)。它并没有像机器人一样机械地点击,而是模拟了人类的浏览行为:
- 智能等待:它没有在页面加载完成的瞬间就去抓数据,而是等待了关键的 DOM 元素
.gl-item出现。这解决了传统爬虫最常见的“数据抓不全”问题。 - 行为模拟:在翻页时,鼠标移动的轨迹是带有随机偏移量的,点击间隔也不是毫秒级的精准,这有效地绕过了初级的反爬虫机制。
第三阶段:智能化字段识别(Smart Extraction)
这是 QClaw 最让我震撼的地方。传统工具需要你手动框选“价格”对应的区域,而 QClaw 结合了 计算机视觉(CV) 和 语义 Embedding。
当我看到它抓取下来的数据时,我发现它不仅抓到了“¥1299.00”,还自动把“¥1599.00”识别为“原价”,并把“20万+”评论数转换成了整数 200000。它甚至自动过滤了广告位的推荐商品,只抓取了真实的搜索结果。这种基于语义的 Schema 提取,比死板的 XPath 强大太多了。
3. 结果交付
不到 2 分钟,我的微信响了。QClaw 发来了一个 Excel 文件。打开一看,数据干净、规整,连列宽都帮我调整好了。那一刻,我感觉我节省了至少 2 个小时的生命。
三、 深度技术拆解:QClaw 为什么这么“聪明”?
如果只是好用,那只是工具层面的评价。但作为一名技术爱好者,我忍不住想探究它背后的原理。结合官方文档和我自己的逆向推导,QClaw 的核心技术栈主要由三部分组成:
1. LLM + Tools 架构(大脑与手脚)
QClaw 本身不生产大模型,它集成了 Kimi、DeepSeek 等顶尖模型。它的核心创新在于 Agent Loop(智能体循环)。
- ReAct 模式:QClaw 遵循 Reasoning + Acting 的模式。它不是一次性生成所有代码,而是“想一步,做一步,看一步”。比如,如果第一步打开网页失败了,它会根据报错信息(Observation)重新规划下一步动作,而不是像传统脚本那样直接崩溃。
2. OpenClaw 框架与 Skills 生态(扩展性)
QClaw 底层基于 OpenClaw 开源框架。这意味它拥有极强的扩展性。
- Skills 市场:我在 ClawHub 里安装了
Excel-Processor和Auto-Chart这两个技能。现在,我不仅可以抓取数据,还能直接让 QClaw 对数据进行透视分析,甚至生成图表。这已经超越了“爬虫”,进入了“数据分析”的领域。
3. 本地化 RPA 引擎(执行力)
QClaw 本质上是一个高度进化的 RPA(机器人流程自动化)工具。但它比 UiPath 等传统 RPA 更聪明。
- DOM 解析与视觉结合:它既能读懂 HTML 的语义(
<span class="price">),也能看懂屏幕上的像素(CV)。当网页结构混乱时,它会 fallback 到视觉识别,这种鲁棒性是传统工具不具备的。
四、 巅峰对决:QClaw vs 八爪鱼 vs Python Scrapy
为了更客观地评价它,我做了一个详细的对比表。这是我三个月真实使用体验的总结,不是参数堆砌。
维度 | QClaw (腾讯 AI Agent) | 八爪鱼 / Import.io (传统 RPA) | Python Scrapy (程序员方案) |
|---|---|---|---|
交互方式 | 自然语言 (NLP) 我说人话,它干活。 | 可视化点选 需要理解网页逻辑,手动配置流程。 | 代码编写 门槛极高,需要深厚的编程功底。 |
应对网站改版 | 极强 (Adaptive) 基于语义理解,DOM 结构小变不影响。 | 弱 (Brittle) XPath 失效就必须重新配置。 | 中等 需要修改 Spider 代码,重新部署。 |
动态加载处理 | 原生支持 内置无头浏览器,自动等待 JS 渲染。 | 一般 需要手动设置 AJAX 超时和触发器。 | 强 但配置中间件(如 Selenium)很麻烦。 |
运行环境 | 本地 PC (隐私安全) 数据不出域,这点对我至关重要。 | 云端/本地 云端版有数据泄露风险。 | 服务器/本地 运维成本高。 |
异常处理 | 拟人化 遇到验证码会截图问我,或者尝试备用方案。 | 机械 直接报错停止,需要人工介入。 | 复杂 需要写大量的 try-except 逻辑。 |
成本 | 免费 (内测期) 未来可能是 Token 计费,但性价比高。 | 昂贵 企业版授权费不菲。 | 时间成本 程序员的工资可不便宜。 |
我的结论:如果你是非技术人员,或者像我这样不想把时间浪费在重复劳动上的运营、市场人员,QClaw 是目前的最优解。

五、 进阶玩法:我的“私人数据监控室”
随着我对 QClaw 越来越熟练,我开始尝试更复杂的玩法——定时任务与自动化监控。
我给 QClaw 设置了一条定时指令(Cron Job):
“每天早晨 8:30,自动检查‘iPhone 15 Pro’在京东和天猫的官方旗舰店价格。如果价格低于 7500 元,立刻发微信通知我。”
这条指令的背后,是 QClaw 将 AI 决策 与 操作系统级调度 的结合。
- 每天早上,我的电脑在开机后(或者后台静默运行),QClaw 就会自动唤醒。
- 它不需要我登录,因为它能接管我本地的浏览器 Session(这需要提前授权),绕过了登录态的难题。
- 一旦发现价格阈值被触发,它通过微信 API 给我发来预警。
这种 “所想即所得” 的自动化体验,让我感觉自己拥有了一个 24 小时不睡觉的数据分析师。
六、 局限与挑战:它还不是完美的
当然,在深度使用三个月后,我也必须客观指出 QClaw 目前存在的局限性。这不仅是吐槽,更是对它未来进化的期待。
- 验证码的“拦路虎” 对于简单的滑动验证码,QClaw 还能应付。但遇到复杂的点选验证码(比如“请选出图片中的所有交通灯”),目前的通用版本 QClaw 就束手无策了。它通常会截取当前页面发给我,让我手动输入。虽然这体现了 Human-in-the-loop 的设计理念,但毕竟中断了自动化流程。
- 超大规模并发的限制 QClaw 定位在桌面级 Agent,受限于本地带宽和浏览器性能,它不适合做那种每秒几千次请求的“暴力爬虫”。如果你是想爬取全网亿级数据做训练集,那还是老老实实买服务器跑 Scrapy 吧。QClaw 的主战场是精准、灵活的中小规模数据采集。
- Token 消耗的隐形成本 虽然现在是内测期免费,但我粗略估算了一下,像我这样每天几十次指令的用户,如果未来按 Token 收费,可能每月也需要几十到上百元的成本。不过相比于我节省下来的时间价值,这笔钱花得很值。
七、 结语:我们正站在历史的转折点上
写到这里,我想起了二十年前,当时的人们为了上网,需要拨号、需要配置调制解调器,那是“技术垄断”的时代。后来,浏览器出现了,上网变成了点点鼠标的事。
今天,QClaw 这样的 AI Agent 正在做同样的事情。它们把“编程”这件事,变成了“说话”。
三个月前,我还需要为了一个简单的数据抓取去求人写代码,或者花费大量时间配置工具。三个月后,我只需要动动嘴(或者敲几个字),数据就乖乖躺在了我的 Excel 里。
QClaw 不仅仅是一个爬虫工具,它是一个信号。 它告诉我们,AI 不再仅仅存在于云端的大模型里,它正在走出对话框,走进我们的操作系统,走进我们的文件系统,变成一个个具体的、能帮我们“干活”的数字生命。
如果你也厌倦了机械的复制粘贴,如果你也想从数据的海洋里轻松捞取珍珠,那么,是时候让你的那只“小龙虾”下水了。
未来已来,它就在你的电脑桌面上。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号