Search Engine:全库搜索与语义检索

Search Engine:全库搜索与语义检索

安全风信子
发布于 2026-06-02 08:26:36
发布于 2026-06-02 08:26:36
作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: 搜索是IDE最基础也最强大的功能之一。现代AI IDE的搜索不仅是关键词匹配,还包括语义搜索、正则搜索、结构化查询。本文讲解Search Engine的实现:全文索引、语义向量检索、查询解析器、搜索结果ranking、以及如何将传统搜索与AI搜索融合,提供更精准的检索结果。文章包含完整的倒排索引实现、向量检索引擎、BM25融合算法、增量索引策略,并提供可运行的混合搜索引擎完整代码。通过本文,你将掌握从理论到实践的完整搜索技术栈,具备构建生产级代码搜索系统的能力。
目录- 本节为你提供的核心技术价值
- 1. 搜索系统架构概览
- 1.1 为什么现代IDE需要高级搜索能力
- 1.2 搜索系统整体架构
- 1.3 搜索流程详解
- 2. 全文索引:倒排索引与Posting List
- 2.1 倒排索引原理
- 2.2 Posting List的高级优化
- 2.3 倒排索引的代码实现
- 2.4 索引压缩技术实现
- 2.5 倒排索引的代码搜索特性增强
- 3. 语义搜索:向量嵌入与近似最近邻检索
- 3.1 从关键词到语义的跨越
- 3.2 代码嵌入的特殊性
- 3.3 向量检索的工程实现
- 3.4 混合检索架构
- 4. 查询解析:从简单查询到复杂查询
- 4.1 查询解析器架构
- 4.2 词法分析与语法解析
- 4.3 查询扩展与重写
- 5. 结果Ranking:BM25、TF-IDF与语义相似度的融合
- 5.1 经典排序算法回顾
- 5.2 语义相似度计算
- 5.3 混合排序框架
- 6. 增量索引:实时更新的索引策略
- 6.1 增量索引的设计挑战
- 6.2 常见索引更新策略
- 6.3 分段索引实现
- 6.4 向量索引的增量更新
- 7. 实践:实现一个支持正则和语义的混合搜索引擎
- 7.1 整体架构设计
- 7.2 完整搜索引擎实现
- 7.3 性能优化技巧
- 8. 总结与展望
- 8.1 核心要点回顾
- 8.2 技术演进趋势
- 8.3 学习路径建议
- 参考链接
- 附录A:搜索引擎完整代码清单
- 附录B:BM25参数调优指南
- 附录C:HNSW参数配置参考
- 附录D:搜索质量评估指标
- 1.1 为什么现代IDE需要高级搜索能力
- 1.2 搜索系统整体架构
- 1.3 搜索流程详解
- 2.1 倒排索引原理
- 2.2 Posting List的高级优化
- 2.3 倒排索引的代码实现
- 2.4 索引压缩技术实现
- 2.5 倒排索引的代码搜索特性增强
- 3.1 从关键词到语义的跨越
- 3.2 代码嵌入的特殊性
- 3.3 向量检索的工程实现
- 3.4 混合检索架构
- 4.1 查询解析器架构
- 4.2 词法分析与语法解析
- 4.3 查询扩展与重写
- 5.1 经典排序算法回顾
- 5.2 语义相似度计算
- 5.3 混合排序框架
- 6.1 增量索引的设计挑战
- 6.2 常见索引更新策略
- 6.3 分段索引实现
- 6.4 向量索引的增量更新
- 7.1 整体架构设计
- 7.2 完整搜索引擎实现
- 7.3 性能优化技巧
- 8.1 核心要点回顾
- 8.2 技术演进趋势
- 8.3 学习路径建议
本节为你提供的核心技术价值
本文系统讲解现代IDE搜索系统的完整技术栈,从倒排索引的底层实现到语义向量检索的工程落地,涵盖查询解析、结果 ranking、增量索引等核心模块,提供可直接运行的生产级代码。通过本文,你将理解为何传统关键词搜索无法满足AI时代的语义理解需求,掌握将 BM25 与语义相似度融合的混合检索方法,具备从零构建高性能代码搜索引擎的能力。
1. 搜索系统架构概览
1.1 为什么现代IDE需要高级搜索能力
在传统软件开发中,搜索功能仅用于查找变量名、函数定义或文件路径。开发者习惯了 Ctrl+F 的精确字符串匹配,习惯了正则表达式的高级筛选。然而,随着代码规模的爆发式增长——现代巨型代码库动辄数千万行代码——传统搜索方式的局限性日益凸显:
搜索类型 | 能力边界 | 典型场景 |
|---|---|---|
精确字符串匹配 | 无法处理拼写变体、同义词 | 搜索 executeQuery 找不到 runQuery |
正则表达式 | 依赖已知模式,无法语义理解 | 搜索"处理用户数据"无法找到"userDataProcessor" |
跨语言搜索 | 无法理解不同语言的等价概念 | Python的 list 和 JavaScript的 array 无法关联 |
上下文感知 | 无法区分同名但不同实体的变量 | 无法区分两个文件中的 config 变量 |
AI驱动的语义搜索解决了这些问题。它将文本映射到高维向量空间,使语义相似的代码片段在向量空间中彼此接近。即使变量名完全不同,只要功能语义相同,就能被检索到。
1.2 搜索系统整体架构
现代IDE搜索系统通常采用分层混合架构,将传统搜索与AI搜索深度融合:
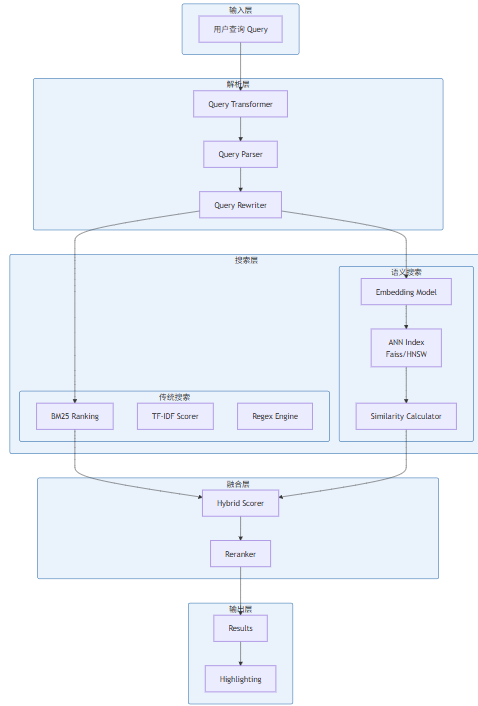
1.3 搜索流程详解
第一步:查询理解。用户输入查询文本后,系统首先进行预处理——分词、去停用词、大小写归一化。对于自然语言查询,还可能进行查询扩展、同义词替换、拼写纠正。这一阶段的输出是一个结构化的查询对象,包含关键词列表、语义向量、权重信息。
第二步:多路召回。系统同时启动多条搜索路径:基于倒排索引的BM25搜索、基于向量的语义搜索、正则表达式匹配。每条路径独立检索,返回候选结果列表。
第三步:分数融合。多路召回的结果需要融合。传统搜索贡献关键词匹配分数,语义搜索贡献语义相似度分数。融合算法决定了最终排序。
第四步:重排序。初排结果可能不够精准。重型重排序模型(如 cross-encoder)可以对 top-k 结果进行精细化排序,将最相关的结果提升到前面。
第五步:结果包装。最终结果需要高亮匹配片段、显示上下文、计算相关度百分比,以友好的方式呈现给用户。
2. 全文索引:倒排索引与Posting List
2.1 倒排索引原理
倒排索引是全文搜索的基石。它的设计哲学是以词找文——传统索引以文档为主键,倒排索引以词项为主键。对于代码搜索场景,倒排索引需要额外考虑标识符分割、语法结构等因素。
倒排索引的核心数据结构:
正排索引 (Forward Index):
doc_1 → "function calculateSum(arr) { return arr.reduce((a,b) => a+b); }"
doc_2 → "def calculate_sum(list_data): return sum(list_data)"
doc_3 → "public static int sum(int[] nums) { return Arrays.stream(nums).sum(); }"
倒排索引 (Inverted Index):
"function" → [doc_1: pos(0), doc_1: pos(10)]
"calculate" → [doc_1: pos(9), doc_2: pos(4), doc_3: pos(13)]
"sum" → [doc_1: pos(21), doc_2: pos(14), doc_3: pos(26)]
"arr" → [doc_1: pos(19), doc_1: pos(23)]
"reduce" → [doc_1: pos(30)]
"list_data" → [doc_2: pos(15)]
"return" → [doc_1: pos(26), doc_2: pos(19), doc_3: pos(21)]倒排索引由**词项词典(Dictionary)和倒排列表(Posting List)**组成。词典存储所有唯一词项及其元数据(如文档频率);倒排列表存储每个词项出现的文档列表及位置信息。
2.2 Posting List的高级优化
Posting List的存储效率直接影响索引大小和查询性能。业界采用多种压缩算法:
**Variable Byte Encoding(VByte)**是最常用的压缩方式。它将整数表示为可变字节序列:小数字节少,大数字节多。对于差分编码后的posting list,效果尤为显著。
**Frame of Reference(FOR)**适合处理posting list中数值聚集的场景。它将数据分块,存储块内最小值作为基准和各值与基准的差值。
Roaring Bitmap将数据分桶存储,每桶选择最优编码方式。对于小数据块使用bitmap,对中等数据块使用数组,对大数据块使用连续区间。Roaring Bitmap在Elasticsearch中被广泛使用。
2.3 倒排索引的代码实现
以下是倒排索引的完整TypeScript实现:
// posting-list.ts - 倒排索引核心实现
interface Posting {
docId: string;
positions: number[];
frequency: number;
}
interface TermPostings {
term: string;
postings: Posting[];
documentFrequency: number;
}
interface InvertedIndex {
// 词项 → Posting列表
dictionary: Map<string, TermPostings>;
// 文档数量
docCount: number;
// 平均文档长度
avgDocLength: number;
// 文档IDF缓存
idfCache: Map<string, number>;
}
/**
* 创建倒排索引实例
*/
function createInvertedIndex(): InvertedIndex {
return {
dictionary: new Map(),
docCount: 0,
avgDocLength: 0,
idfCache: new Map()
};
}
/**
* 文档分析器 - 将文本转换为词项流
*/
interface Token {
term: string;
position: number;
isIdentifier: boolean;
}
function analyzeDocument(
docId: string,
content: string,
index: InvertedIndex
): void {
// 预处理:统一小写、移除特殊字符
const normalized = content.toLowerCase();
// 简单分词器:按空格和符号分割
const tokens: Token[] = [];
const words = normalized.split(/[\s\p{P}]+/u);
let position = 0;
for (const word of words) {
if (word.length < 2) continue; // 过滤短词
const isIdentifier = /^[a-z_$][a-z0-9_$]*$/i.test(word);
tokens.push({ term: word, position: position++, isIdentifier });
}
// 更新文档统计
index.docCount++;
// 构建posting
const termPositions = new Map<string, number[]>();
for (const token of tokens) {
const positions = termPositions.get(token.term) || [];
positions.push(token.position);
termPositions.set(token.term, positions);
}
// 写入倒排索引
for (const [term, positions] of termPositions) {
if (!index.dictionary.has(term)) {
index.dictionary.set(term, {
term,
postings: [],
documentFrequency: 0
});
}
const termPostings = index.dictionary.get(term)!;
termPostings.postings.push({
docId,
positions: positions.sort((a, b) => a - b),
frequency: positions.length
});
termPostings.documentFrequency++;
}
}
/**
* BM25评分计算
*/
function calculateBM25(
query: string,
index: InvertedIndex,
k1: number = 1.5,
b: number = 0.75
): Array<{ docId: string; score: number }> {
const queryTerms = query.toLowerCase().split(/\s+/);
const scores = new Map<string, number>();
// 计算IDF
const N = index.docCount;
for (const term of queryTerms) {
if (!index.dictionary.has(term)) continue;
const df = index.dictionary.get(term)!.documentFrequency;
// IDF公式:log((N - df + 0.5) / (df + 0.5) + 1)
let idf: number;
if (index.idfCache.has(term)) {
idf = index.idfCache.get(term)!;
} else {
idf = Math.log((N - df + 0.5) / (df + 0.5) + 1);
index.idfCache.set(term, idf);
}
// 遍历该词的所有posting
const postings = index.dictionary.get(term)!.postings;
for (const posting of postings) {
const docId = posting.docId;
const tf = posting.frequency;
// BM25公式:IDF * (tf * (k1 + 1)) / (tf + k1 * (1 - b + b * |d|/avgD))
const docLength = posting.positions.length;
const avgDL = index.avgDocLength || 1;
const numerator = tf * (k1 + 1);
const denominator = tf + k1 * (1 - b + b * (docLength / avgDL));
const bm25 = idf * (numerator / denominator);
const currentScore = scores.get(docId) || 0;
scores.set(docId, currentScore + bm25);
}
}
// 排序返回结果
return Array.from(scores.entries())
.map(([docId, score]) => ({ docId, score }))
.sort((a, b) => b.score - a.score);
}
/**
* 布尔查询支持:AND, OR, NOT
*/
function executeBooleanQuery(
query: Array<{ term: string; op?: 'AND' | 'OR' | 'NOT' }>,
index: InvertedIndex
): Set<string> {
if (query.length === 0) return new Set();
let result = new Set<string>();
for (let i = 0; i < query.length; i++) {
const { term, op = 'OR' } = query[i];
const postings = index.dictionary.get(term)?.postings || [];
const docIds = new Set(postings.map(p => p.docId));
switch (op) {
case 'AND':
if (i === 0) {
result = docIds;
} else {
result = new Set([...result].filter(id => docIds.has(id)));
}
break;
case 'OR':
result = new Set([...result, ...docIds]);
break;
case 'NOT':
// 获取所有文档ID
const allDocs = new Set(
Array.from(index.dictionary.values())
.flatMap(tp => tp.postings.map(p => p.docId))
);
result = new Set([...allDocs].filter(id => !docIds.has(id)));
break;
}
}
return result;
}
// 导出模块
export {
InvertedIndex,
Posting,
TermPostings,
Token,
createInvertedIndex,
analyzeDocument,
calculateBM25,
executeBooleanQuery
};2.4 索引压缩技术实现
// posting-compression.ts - Posting List压缩实现
/**
* Variable Byte Encoding(变字节编码)
* 将整数编码为可变长字节序列
*/
class VByteEncoder {
static encode(numbers: number[]): Uint8Array {
const result: number[] = [];
for (const n of numbers) {
let value = n;
// 将数字拆分为7位一组的字节
while (value >= 128) {
result.push((value & 0x7F) | 0x80); // 设置继续位
value >>= 7;
}
result.push(value & 0x7F); // 最后一个字节不设置继续位
}
return new Uint8Array(result);
}
static decode(bytes: Uint8Array): number[] {
const result: number[] = [];
let shift = 0;
let n = 0;
for (const byte of bytes) {
n |= (byte & 0x7F) << shift;
if ((byte & 0x80) === 0) {
result.push(n);
n = 0;
shift = 0;
} else {
shift += 7;
}
}
return result;
}
}
/**
* Roaring Bitmap - 高效位图压缩
*/
class RoaringBitmap {
private containers: Map<number, Uint16Array>;
constructor() {
this.containers = new Map();
}
// 添加文档ID
add(docId: number): void {
const high = (docId >> 16) & 0xFFFF;
const low = docId & 0xFFFF;
if (!this.containers.has(high)) {
this.containers.set(high, new Uint16Array());
}
const container = this.containers.get(high)!;
// 简单实现:追加后排序去重
const newContainer = new Uint16Array(container.length + 1);
newContainer.set(container);
newContainer[container.length] = low;
newContainer.sort();
this.containers.set(high, newContainer);
}
// 检查是否包含
contains(docId: number): boolean {
const high = (docId >> 16) & 0xFFFF;
const low = docId & 0xFFFF;
const container = this.containers.get(high);
if (!container) return false;
// 二分查找
return this.binarySearch(container, low) >= 0;
}
// 获取容器基数
getCardinality(): number {
let total = 0;
for (const container of this.containers.values()) {
total += container.length;
}
return total;
}
// 交集操作
and(other: RoaringBitmap): RoaringBitmap {
const result = new RoaringBitmap();
for (const [high, container] of this.containers) {
const otherContainer = other.containers.get(high);
if (!otherContainer) continue;
// 计算交集
const intersection: number[] = [];
for (const low of container) {
if (this.binarySearch(otherContainer, low) >= 0) {
intersection.push(low);
}
}
if (intersection.length > 0) {
result.containers.set(high, new Uint16Array(intersection));
}
}
return result;
}
// 并集操作
or(other: RoaringBitmap): RoaringBitmap {
const result = new RoaringBitmap();
const allHighs = new Set([
...this.containers.keys(),
...other.containers.keys()
]);
for (const high of allHighs) {
const thisContainer = this.containers.get(high) || new Uint16Array();
const otherContainer = other.containers.get(high) || new Uint16Array();
// 合并并排序
const merged = new Uint16Array(thisContainer.length + otherContainer.length);
merged.set(thisContainer);
merged.set(otherContainer, thisContainer.length);
merged.sort();
result.containers.set(high, merged);
}
return result;
}
private binarySearch(arr: Uint16Array, target: number): number {
let left = 0, right = arr.length - 1;
while (left <= right) {
const mid = (left + right) >> 1;
if (arr[mid] === target) return mid;
if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1;
}
// 序列化为字节数组
serialize(): Uint8Array {
const chunks: number[][] = [];
for (const [high, container] of this.containers) {
// 4字节:high key
// 4字节:container size
// 2*size 字节:数据
chunks.push([
(high >> 24) & 0xFF, (high >> 16) & 0xFF,
(high >> 8) & 0xFF, high & 0xFF,
(container.length >> 24) & 0xFF, (container.length >> 16) & 0xFF,
(container.length >> 8) & 0xFF, container.length & 0xFF,
...Array.from(container).flatMap(v => [(v >> 8) & 0xFF, v & 0xFF])
]);
}
const totalLen = chunks.reduce((sum, c) => sum + c.length, 0);
const result = new Uint8Array(totalLen);
let offset = 0;
for (const chunk of chunks) {
result.set(chunk, offset);
offset += chunk.length;
}
return result;
}
}
export { VByteEncoder, RoaringBitmap };2.5 倒排索引的代码搜索特性增强
代码搜索与传统文本搜索有显著区别。代码中的标识符(如变量名、函数名)往往由多个词混合组成(如 calculateSum、user_data),需要特殊的分词策略。
// code-analyzer.ts - 代码专用分析器
interface CodeToken {
term: string;
position: number;
tokenType: 'identifier' | 'keyword' | 'string' | 'number' | 'operator';
isCompound: boolean;
subTerms?: string[]; // 复合标识符拆分后的子词
}
/**
* 代码感知分词器
* 支持 camelCase、snake_case、PascalCase 拆分
*/
class CodeAnalyzer {
private stopWords = new Set([
'the', 'a', 'an', 'and', 'or', 'but', 'in', 'on', 'at', 'to', 'for',
'of', 'with', 'by', 'from', 'as', 'is', 'was', 'are', 'were', 'been'
]);
/**
* 拆分复合标识符
* calculateSum → [calculate, sum]
* user_data_id → [user, data, id]
* HTTPRequest → [HTTP, Request]
*/
splitCompoundIdentifier(identifier: string): string[] {
const terms: string[] = [];
// 1. 下划线分割
let parts = identifier.split('_');
// 2. 驼峰分割
const splitByCamel = (str: string): string[] => {
const result: string[] = [];
let current = '';
for (let i = 0; i < str.length; i++) {
const char = str[i];
const nextChar = str[i + 1];
// 检测大写字母开头(新词)或大写后面跟着小写(结束当前词)
if (i > 0 && char === char.toUpperCase() &&
nextChar && nextChar === nextChar.toLowerCase()) {
if (current) result.push(current);
current = char;
} else if (char === char.toUpperCase() && i > 0) {
// 连续大写(如HTTP):等待小写出现再切分
if (result.length > 0 || current.length > 1) {
result.push(current);
}
current = char;
} else {
current += char;
}
}
if (current) result.push(current);
return result;
};
// 处理每个下划线分割的部分
for (const part of parts) {
if (!part) continue;
// 处理连续大写词(如 HTTPServer → HTTP, Server)
if (part === part.toUpperCase()) {
terms.push(part.toLowerCase());
} else {
terms.push(...splitByCamel(part).map(t => t.toLowerCase()));
}
}
return terms.filter(t => t.length >= 2);
}
/**
* 分析代码文本
*/
analyzeCode(content: string): CodeToken[] {
const tokens: CodeToken[] = [];
const identifierPattern = /[a-zA-Z_$][a-zA-Z0-9_$]*/g;
let match;
while ((match = identifierPattern.exec(content)) !== null) {
const value = match[0];
const position = match.index;
// 识别关键字
const keywords = new Set([
'function', 'const', 'let', 'var', 'return', 'if', 'else', 'for',
'while', 'class', 'interface', 'type', 'enum', 'public', 'private',
'protected', 'static', 'async', 'await', 'import', 'export', 'from',
'def', 'class', 'self', 'lambda', 'yield', 'raise', 'try', 'except',
'public', 'private', 'final', 'abstract', 'extends', 'implements'
]);
const tokenType: CodeToken['tokenType'] =
keywords.has(value) ? 'keyword' :
/^[a-z_$][a-z0-9_$]*$/i.test(value) && value !== value.toUpperCase() ? 'identifier' :
'identifier';
// 检查是否为复合标识符
const isCompound = /[A-Z_]/.test(value) || /[a-z][a-z]/.test(value);
const subTerms = isCompound ? this.splitCompoundIdentifier(value) : undefined;
tokens.push({
term: value.toLowerCase(),
position,
tokenType,
isCompound,
subTerms
});
}
return tokens;
}
/**
* 提取代码特征
*/
extractFeatures(content: string): Map<string, number> {
const features = new Map<string, number>();
const tokens = this.analyzeCode(content);
for (const token of tokens) {
// 原始词项
features.set(token.term, (features.get(token.term) || 0) + 1);
// 复合标识符的子词
if (token.subTerms) {
for (const subTerm of token.subTerms) {
if (!this.stopWords.has(subTerm)) {
features.set(subTerm, (features.get(subTerm) || 0) + 0.5);
}
}
}
}
return features;
}
}
export { CodeAnalyzer, CodeToken };3. 语义搜索:向量嵌入与近似最近邻检索
3.1 从关键词到语义的跨越
语义搜索的核心思想是将查询和文档都映射到高维向量空间,通过向量距离衡量语义相似度。这种方法突破了关键词匹配的限制:
- 同义词理解:
car和automobile语义相近,向量空间距离小 - 上下文感知:
bank在"河岸"和"银行"语境下有不同向量 - 跨语言搜索:多语言模型可以将不同语言的查询和文档对齐到统一空间
- 模糊匹配:拼写错误、命名变体都能被正确理解
语义搜索的技术演进经历了三个阶段:词袋模型(Bag of Words) → 词嵌入(Word Embedding) → 上下文嵌入(Contextual Embedding)。
词袋模型如 TF-IDF、BM25 将文档表示为词频向量,维度等于词表大小,高维稀疏。词嵌入如 Word2Vec、GloVe 将词映射到低维连续向量,解决了同义词问题,但无法处理一词多义。上下文嵌入如 BERT、CodeBERT 根据上下文动态生成词向量,完美解决了多义词问题。
3.2 代码嵌入的特殊性
代码嵌入比自然语言嵌入更加复杂,原因如下:
特性 | 自然语言 | 代码 |
|---|---|---|
语法结构 | 线性序列,树状结构 | AST树状结构,嵌套层级深 |
语义歧义 | 较少 | 函数名缩写、符号重载导致歧义多 |
执行语义 | 模糊 | 必须确定(编译器可验证) |
跨语言 | 翻译等价 | 功能等价但语法差异大 |
命名规律 | 词汇组合 | camelCase、snake_case等固定模式 |
代码嵌入模型需要捕获:
- 词法级特征:标识符名、关键字、操作符
- 句法级特征:AST结构、控制流图
- 语义级特征:数据类型、函数签名、调用关系
- 文档级特征:文件路径、项目结构
主流代码嵌入模型包括:
- CodeBERT(微软):多语言预训练,支持自然语言-代码对
- GraphCodeBERT:融入数据流分析
- UnixCoder:支持多语言、多任务统一框架
- CodeLlama:代码生成与理解一体的LLM
3.3 向量检索的工程实现
向量检索的核心问题是近似最近邻(ANN)搜索。精确的暴力搜索(KNN)在 billion 级别数据上不可行,需要在精度和速度之间权衡。
// vector-index.ts - 向量索引与ANN检索实现
interface Vector {
id: string;
embedding: Float32Array;
metadata?: Record<string, any>;
}
interface SearchResult {
id: string;
score: number;
metadata?: Record<string, any>;
}
/**
* 余弦相似度计算
*/
function cosineSimilarity(a: Float32Array, b: Float32Array): number {
let dotProduct = 0;
let normA = 0;
let normB = 0;
for (let i = 0; i < a.length; i++) {
dotProduct += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB) + 1e-10);
}
/**
* 欧氏距离转相似度
*/
function euclideanToSimilarity(distance: number): number {
return 1 / (1 + distance);
}
/**
* HNSW - Hierarchical Navigable Small World
* 当前最优的ANN算法之一,O(log N)查询复杂度
*/
class HNSWIndex {
private vectors: Map<string, Vector>;
private layers: Array<Map<string, string[]>>; // layer → {nodeId → [neighborIds]}
private maxLevel: number;
private m: number; // 每一层的邻居数
private efConstruction: number; // 构建时的动态列表大小
private efSearch: number; // 搜索时的动态列表大小
private levelProb: number; // 层高概率因子
constructor(
dimension: number,
options: {
m?: number;
efConstruction?: number;
efSearch?: number;
levelProb?: number;
} = {}
) {
this.vectors = new Map();
this.layers = [];
this.maxLevel = 0;
this.m = options.m || 16;
this.efConstruction = options.efConstruction || 200;
this.efSearch = options.efSearch || 50;
this.levelProb = options.levelProb || 1 / Math.E;
}
/**
* 生成随机层
*/
private randomLevel(): number {
let level = 0;
while (Math.random() < this.levelProb && level < this.maxLevel + 1) {
level++;
}
return Math.min(level, Math.floor(Math.log2(this.vectors.size + 1)));
}
/**
* 插入向量
*/
insert(vector: Vector): void {
const level = this.randomLevel();
// 扩展层结构
while (this.layers.length <= level) {
this.layers.push(new Map());
}
// 获取或创建当前节点层-邻居映射
if (!this.layers[level].has(vector.id)) {
this.layers[level].set(vector.id, []);
}
this.vectors.set(vector.id, vector);
// 更新maxLevel
if (level > this.maxLevel) {
this.maxLevel = level;
}
// 调整所有层的邻居结构
this.resizeNeighbors(vector.id, level);
// 更新其他节点的邻居关系
this.updateNeighbors(vector.id, level);
}
/**
* 确保节点有足够邻居空间
*/
private resizeNeighbors(nodeId: string, maxLevel: number): void {
for (let l = 0; l <= maxLevel; l++) {
if (!this.layers[l].has(nodeId)) {
this.layers[l].set(nodeId, []);
}
}
}
/**
* 更新邻居关系
*/
private updateNeighbors(newNodeId: string, level: number): void {
const newVector = this.vectors.get(newNodeId)!;
for (let l = 0; l <= level; l++) {
const layer = this.layers[l];
if (!layer) continue;
const neighbors = layer.get(newNodeId) || [];
// 找到efConstruction个最近邻居
const candidates = this.searchLayer(
newVector.embedding,
this.efConstruction,
l
);
// 选择最近的m个作为邻居
neighbors.length = 0;
for (let i = 0; i < Math.min(this.m, candidates.length); i++) {
const candidateId = candidates[i].id;
if (candidateId !== newNodeId) {
neighbors.push(candidateId);
}
}
layer.set(newNodeId, neighbors);
// 更新候选节点的邻居列表,添加新节点
for (const neighborId of neighbors) {
const neighborNeighbors = layer.get(neighborId) || [];
if (neighborNeighbors.length < this.m) {
const neighborVector = this.vectors.get(neighborId)!;
const dist = 1 - cosineSimilarity(newVector.embedding, neighborVector.embedding);
neighborNeighbors.push(newNodeId);
}
}
}
}
/**
* 在某一层搜索最近邻
*/
private searchLayer(
query: Float32Array,
ef: number,
level: number
): SearchResult[] {
const layer = this.layers[level];
if (!layer || layer.size === 0) {
return [];
}
// 初始化:选择随机入口点
const visited = new Set<string>();
const candidates: Array<{ id: string; distance: number }> = [];
const result: Array<{ id: string; distance: number }> = [];
// 选择离查询最近的入口点
let entryId = layer.keys().next().value;
let entryVector = this.vectors.get(entryId);
let minDist = 1 - cosineSimilarity(query, entryVector!.embedding);
for (const [id, vec] of this.vectors) {
const dist = 1 - cosineSimilarity(query, vec.embedding);
if (dist < minDist) {
minDist = dist;
entryId = id;
entryVector = vec;
}
}
visited.add(entryId);
candidates.push({ id: entryId, distance: minDist });
while (candidates.length > 0) {
// 取出距离最小的候选
candidates.sort((a, b) => a.distance - b.distance);
const current = candidates.shift()!;
// 如果最远结果的距离已经小于当前候选,更新结果
if (result.length >= ef && result[result.length - 1].distance < current.distance) {
break;
}
result.push(current);
// 检查邻居
const neighbors = layer.get(current.id) || [];
for (const neighborId of neighbors) {
if (visited.has(neighborId)) continue;
visited.add(neighborId);
const neighborVector = this.vectors.get(neighborId)!;
const dist = 1 - cosineSimilarity(query, neighborVector.embedding);
// 维护候选队列
if (result.length < ef || dist < result[result.length - 1].distance) {
candidates.push({ id: neighborId, distance: dist });
}
}
}
result.sort((a, b) => a.distance - b.distance);
return result.slice(0, ef).map(r => ({
id: r.id,
score: 1 - r.distance,
metadata: this.vectors.get(r.id)?.metadata
}));
}
/**
* 搜索k近邻
*/
search(queryEmbedding: Float32Array, k: number): SearchResult[] {
if (this.vectors.size === 0) return [];
// 从最高层开始搜索,逐层下降到最低层
let currentResult = this.searchLayer(
queryEmbedding,
this.efSearch,
this.maxLevel
);
// 逐层下降
for (let level = this.maxLevel - 1; level >= 0; level--) {
const layerResults = this.searchLayer(queryEmbedding, this.efSearch, level);
// 合并结果并重新排序
const merged = new Map<string, SearchResult>();
for (const r of currentResult) {
merged.set(r.id, r);
}
for (const r of layerResults) {
if (merged.has(r.id)) {
// 保留更好的分数
const existing = merged.get(r.id)!;
existing.score = Math.max(existing.score, r.score);
} else {
merged.set(r.id, r);
}
}
currentResult = Array.from(merged.values())
.sort((a, b) => b.score - a.score)
.slice(0, this.efSearch);
}
return currentResult.slice(0, k);
}
/**
* 批量插入
*/
bulkInsert(vectors: Vector[]): void {
for (const vector of vectors) {
this.insert(vector);
}
}
/**
* 获取索引统计
*/
getStats(): {
size: number;
maxLevel: number;
layerCount: number;
memoryEstimateMB: number;
} {
let neighborCount = 0;
for (const layer of this.layers) {
for (const neighbors of layer.values()) {
neighborCount += neighbors.length;
}
}
// 估算内存:向量存储 + 邻居指针
const vectorBytes = this.vectors.size * (128 + 32); // embedding + overhead
const neighborBytes = neighborCount * 8;
return {
size: this.vectors.size,
maxLevel: this.maxLevel,
layerCount: this.layers.length,
memoryEstimateMB: (vectorBytes + neighborBytes) / (1024 * 1024)
};
}
}
export { Vector, SearchResult, HNSWIndex, cosineSimilarity };3.4 混合检索架构
现代搜索系统通常将语义搜索与传统搜索结合,形成混合检索架构:
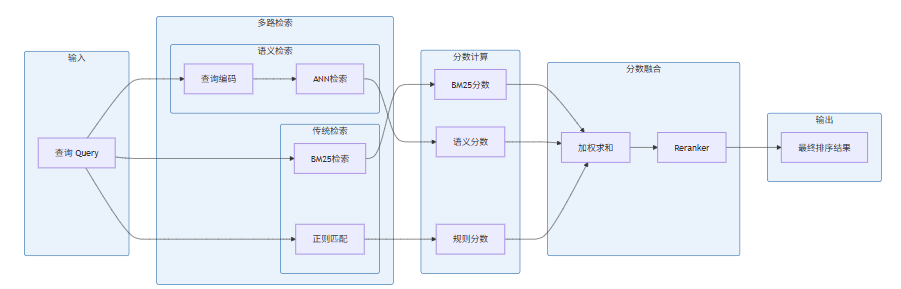
分数融合策略是混合检索的核心。常见方法包括:
- 线性加权:
- 分数归一化后加权:将各路分数归一化到 [0,1] 再加权
- Convex Combination:通过学习确定最优权重
- Reciprocal Rank Fusion (RRF):基于排名的融合,不依赖分数绝对值
4. 查询解析:从简单查询到复杂查询
4.1 查询解析器架构
查询解析器负责将用户输入转换为可执行的查询表达式。一个完整的查询解析流程:
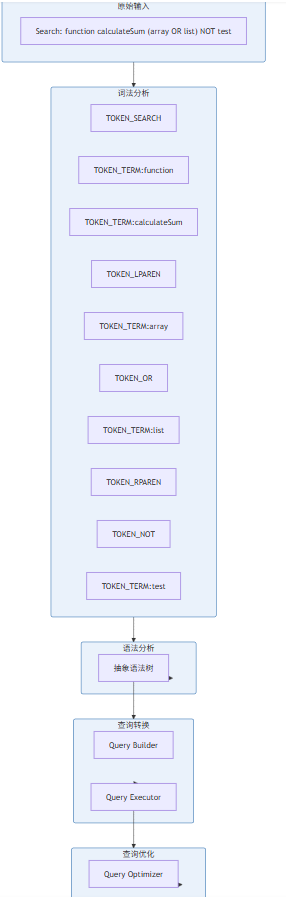
4.2 词法分析与语法解析
// query-parser.ts - 查询解析器完整实现
// 词法token类型
enum TokenType {
TERM = 'TERM', // 普通词项
PHRASE = 'PHRASE', // 短语(引号包裹)
REGEX = 'REGEX', // 正则表达式
FIELD = 'FIELD', // 字段限定
AND = 'AND', // 逻辑与
OR = 'OR', // 逻辑或
NOT = 'NOT', // 逻辑非
LPAREN = 'LPAREN', // 左括号
RPAREN = 'RPAREN', // 右括号
COLON = 'COLON', // 冒号(字段分隔)
WILDCARD = 'WILDCARD', // 通配符
FUZZY = 'FUZZY', // 模糊匹配
TILDE = 'TILDE', // 相似度(~)
BOOST = 'BOOST', // 权重提升(^)
EOF = 'EOF'
}
interface Token {
type: TokenType;
value: string;
position: number;
}
interface ASTNode {
type: string;
value?: string;
operator?: string;
field?: string;
boost?: number;
children?: ASTNode[];
}
// 词法分析器
class Lexer {
private input: string;
private position: number = 0;
constructor(input: string) {
this.input = input.trim();
}
tokenize(): Token[] {
const tokens: Token[] = [];
while (this.position < this.input.length) {
const token = this.nextToken();
if (token) tokens.push(token);
}
tokens.push({ type: TokenType.EOF, value: '', position: this.position });
return tokens;
}
private nextToken(): Token | null {
const start = this.position;
const char = this.input[this.position];
// 跳过空白
if (/\s/.test(char)) {
this.position++;
return null;
}
// 字符串末尾
if (this.position >= this.input.length) {
return null;
}
// 括号
if (char === '(') {
this.position++;
return { type: TokenType.LPAREN, value: '(', position: start };
}
if (char === ')') {
this.position++;
return { type: TokenType.RPAREN, value: ')', position: start };
}
// 冒号
if (char === ':') {
this.position++;
return { type: TokenType.COLON, value: ':', position: start };
}
// 引号 - 短语
if (char === '"') {
this.position++;
let value = '';
while (this.position < this.input.length && this.input[this.position] !== '"') {
value += this.input[this.position++];
}
this.position++; // 跳过结束引号
return { type: TokenType.PHRASE, value, position: start };
}
// 斜杠 - 正则
if (char === '/') {
this.position++;
let value = '';
while (this.position < this.input.length && this.input[this.position] !== '/') {
value += this.input[this.position++];
}
this.position++; // 跳过结束斜杠
return { type: TokenType.REGEX, value, position: start };
}
// 脱字符 - 权重
if (char === '^') {
this.position++;
let numStr = '';
while (this.position < this.input.length && /[0-9.]/.test(this.input[this.position])) {
numStr += this.input[this.position++];
}
return { type: TokenType.BOOST, value: numStr || '1', position: start };
}
// 波浪号 - 模糊/相似
if (char === '~') {
this.position++;
let numStr = '';
while (this.position < this.input.length && /[0-9.]/.test(this.input[this.position])) {
numStr += this.input[this.position++];
}
return { type: TokenType.TILDE, value: numStr, position: start };
}
// 逻辑运算符
if (char === 'A' || char === 'a') {
const next3 = this.input.substring(this.position, this.position + 3).toUpperCase();
if (next3 === 'AND') {
this.position += 3;
return { type: TokenType.AND, value: 'AND', position: start };
}
}
if (char === 'O' || char === 'o') {
const next2 = this.input.substring(this.position, this.position + 2).toUpperCase();
if (next2 === 'OR') {
this.position += 2;
return { type: TokenType.OR, value: 'OR', position: start };
}
}
if (char === 'N' || char === 'n') {
const next3 = this.input.substring(this.position, this.position + 3).toUpperCase();
if (next3 === 'NOT') {
this.position += 3;
return { type: TokenType.NOT, value: 'NOT', position: start };
}
}
// 字段前缀(identifier:)
if (/[a-zA-Z_$]/.test(char)) {
let value = '';
while (this.position < this.input.length && /[a-zA-Z0-9_$.]/.test(this.input[this.position])) {
value += this.input[this.position++];
}
// 检查是否有字段冒号
if (this.position < this.input.length && this.input[this.position] === ':') {
// 字段token在解析阶段处理
this.position++; // 跳过冒号
return { type: TokenType.FIELD, value, position: start };
}
return { type: TokenType.TERM, value, position: start };
}
// 未知字符,跳过
this.position++;
return null;
}
}
// 语法分析器 - 递归下降解析器
class Parser {
private tokens: Token[];
private position: number = 0;
constructor(tokens: Token[]) {
this.tokens = tokens;
}
parse(): ASTNode {
return this.parseOr();
}
private current(): Token {
return this.tokens[this.position] || { type: TokenType.EOF, value: '', position: 0 };
}
private consume(type?: TokenType): Token {
const token = this.current();
if (type && token.type !== type) {
throw new Error(`Expected ${type} but got ${token.type} at position ${token.position}`);
}
this.position++;
return token;
}
private parseOr(): ASTNode {
let left = this.parseAnd();
while (this.current().type === TokenType.OR) {
this.consume(TokenType.OR);
const right = this.parseAnd();
left = {
type: 'OR',
operator: 'OR',
children: [left, right]
};
}
return left;
}
private parseAnd(): ASTNode {
let left = this.parseNot();
while (this.current().type === TokenType.AND ||
(this.current().type !== TokenType.OR &&
this.current().type !== TokenType.RPAREN &&
this.current().type !== TokenType.EOF)) {
if (this.current().type === TokenType.AND) {
this.consume(TokenType.AND);
}
const right = this.parseNot();
left = {
type: 'AND',
operator: 'AND',
children: [left, right]
};
}
return left;
}
private parseNot(): ASTNode {
if (this.current().type === TokenType.NOT) {
this.consume(TokenType.NOT);
const child = this.parseNot();
return {
type: 'NOT',
operator: 'NOT',
children: [child]
};
}
return this.parseUnary();
}
private parseUnary(): ASTNode {
if (this.current().type === TokenType.LPAREN) {
this.consume(TokenType.LPAREN);
const expr = this.parseOr();
this.consume(TokenType.RPAREN);
return expr;
}
if (this.current().type === TokenType.FIELD) {
const field = this.consume(TokenType.FIELD).value;
let term = this.parsePrimary();
if (field === 'regex' || field === 're') {
term.type = 'REGEX';
}
term.field = field;
return term;
}
return this.parsePrimary();
}
private parsePrimary(): ASTNode {
const token = this.current();
if (token.type === TokenType.TERM) {
this.consume();
let boost = 1.0;
// 检查权重
if (this.current().type === TokenType.BOOST) {
boost = parseFloat(this.consume().value) || 1.0;
}
// 检查模糊
let fuzziness = 0;
if (this.current().type === TokenType.TILDE) {
const tildeVal = this.consume().value;
fuzziness = tildeVal ? parseFloat(tildeVal) : 1;
}
const node: ASTNode = {
type: 'TERM',
value: token.value,
boost
};
if (fuzziness > 0) {
node.type = 'FUZZY';
}
return node;
}
if (token.type === TokenType.PHRASE) {
this.consume();
return {
type: 'PHRASE',
value: token.value
};
}
if (token.type === TokenType.REGEX) {
this.consume();
return {
type: 'REGEX',
value: token.value
};
}
throw new Error(`Unexpected token: ${token.type} at position ${token.position}`);
}
}
// 查询解析器主类
class QueryParser {
private lexer: Lexer;
constructor() {
this.lexer = new Lexer('');
}
parse(query: string): ASTNode {
this.lexer = new Lexer(query);
const tokens = this.lexer.tokenize();
const parser = new Parser(tokens);
return parser.parse();
}
/**
* AST可视化(调试用)
*/
visualize(ast: ASTNode, depth: number = 0): string {
const indent = ' '.repeat(depth);
let result = `${indent}${ast.type}`;
if (ast.value) result += `: "${ast.value}"`;
if (ast.field) result += ` [field: ${ast.field}]`;
if (ast.boost && ast.boost !== 1) result += ` ^${ast.boost}`;
result += '\n';
if (ast.children) {
for (const child of ast.children) {
result += this.visualize(child, depth + 1);
}
}
return result;
}
}
// 查询执行器
class QueryExecutor {
private invertedIndex: any;
private vectorIndex: any;
constructor(invertedIndex: any, vectorIndex: any) {
this.invertedIndex = invertedIndex;
this.vectorIndex = vectorIndex;
}
execute(ast: ASTNode): Set<string> {
switch (ast.type) {
case 'AND':
return this.executeAnd(ast);
case 'OR':
return this.executeOr(ast);
case 'NOT':
return this.executeNot(ast);
case 'TERM':
case 'FUZZY':
return this.executeTerm(ast);
case 'PHRASE':
return this.executePhrase(ast);
case 'REGEX':
return this.executeRegex(ast);
default:
return new Set();
}
}
private executeAnd(ast: ASTNode): Set<string> {
if (!ast.children || ast.children.length < 2) return new Set();
let result = this.execute(ast.children[0]);
for (let i = 1; i < ast.children.length; i++) {
const childResult = this.execute(ast.children[i]);
result = new Set([...result].filter(id => childResult.has(id)));
}
return result;
}
private executeOr(ast: ASTNode): Set<string> {
if (!ast.children) return new Set();
const result = new Set<string>();
for (const child of ast.children) {
const childResult = this.execute(child);
for (const id of childResult) {
result.add(id);
}
}
return result;
}
private executeNot(ast: ASTNode): Set<string> {
if (!ast.children || ast.children.length === 0) return new Set();
const childResult = this.execute(ast.children[0]);
const allDocs = new Set(this.invertedIndex.getAllDocIds());
return new Set([...allDocs].filter(id => !childResult.has(id)));
}
private executeTerm(ast: ASTNode): Set<string> {
const postings = this.invertedIndex.getPostings(ast.value!);
const docIds = new Set(postings.map((p: any) => p.docId));
// 模糊匹配处理
if (ast.type === 'FUZZY') {
const fuzzyMatches = this.invertedIndex.fuzzySearch(ast.value!, 2);
for (const id of fuzzyMatches) {
docIds.add(id);
}
}
return docIds;
}
private executePhrase(ast: ASTNode): Set<string> {
const terms = ast.value!.split(/\s+/);
if (terms.length === 0) return new Set();
// 找到第一个词的文档
let result = new Set(this.invertedIndex.getPostings(terms[0]).map((p: any) => p.docId));
// 逐步过滤,确保词序匹配
for (let i = 1; i < terms.length; i++) {
const termPostings = this.invertedIndex.getPostings(terms[i]);
const nextResult = new Set<string>();
for (const docId of result) {
const thisDocPostings = termPostings.filter((p: any) => p.docId === docId);
const prevDocPostings = this.invertedIndex.getPostings(terms[i-1])
.filter((p: any) => p.docId === docId);
// 检查位置相邻
for (const tp of thisDocPostings) {
for (const pp of prevDocPostings) {
if (tp.positions.some((pos: number) =>
pp.positions.some((ppos: number) => pos === ppos + 1))) {
nextResult.add(docId);
break;
}
}
}
}
result = nextResult;
}
return result;
}
private executeRegex(ast: ASTNode): Set<string> {
const regex = new RegExp(ast.value!);
return this.invertedIndex.regexSearch(regex);
}
}
export {
QueryParser,
QueryExecutor,
Lexer,
Parser,
TokenType,
Token,
ASTNode
};4.3 查询扩展与重写
查询扩展通过同义词库、关联词库或用户行为数据扩展原始查询,提高召回率。
// query-expander.ts - 查询扩展器
interface ExpansionTerm {
term: string;
score: number;
source: 'synonym' | 'related' | 'correction' | 'semantic';
}
/**
* 查询扩展器
*/
class QueryExpander {
private synonyms: Map<string, Set<string>>;
private corrections: Map<string, string>;
private codePatterns: Map<string, Set<string>>;
constructor() {
this.synonyms = new Map();
this.corrections = new Map();
this.codePatterns = new Map();
this.initializeDefaultMappings();
}
/**
* 初始化默认同义词映射
*/
private initializeDefaultMappings(): void {
// 编程语言同义词
this.addSynonym('list', 'array', 'collection', 'sequence');
this.addSynonym('map', 'dictionary', 'hash', 'object', 'dict');
this.addSynonym('function', 'method', 'procedure', 'func');
this.addSynonym('string', 'text', 'str', 'char');
this.addSynonym('integer', 'int', 'number', 'numeric');
this.addSynonym('boolean', 'bool', 'flag');
this.addSynonym('calculate', 'compute', 'evaluate', 'process');
this.addSynonym('sum', 'total', 'aggregate');
this.addSynonym('get', 'fetch', 'retrieve', 'load', 'read');
this.addSynonym('set', 'assign', 'store', 'write', 'save');
this.addSynonym('create', 'instantiate', 'new', 'make', 'build');
this.addSynonym('remove', 'delete', 'clear', 'drop');
this.addSynonym('find', 'search', 'locate', 'lookup', 'query');
this.addSynonym('sort', 'order', 'arrange');
this.addSynonym('filter', 'select', 'where', 'query');
// 代码模式同义词
this.addSynonym('callback', 'handler', 'listener');
this.addSynonym('promise', 'future', 'deferred');
this.addSynonym('async', 'await', 'then');
this.addSynonym('loop', 'iterate', 'forEach', 'each');
this.addSynonym('error', 'exception', 'throw');
this.addSynonym('config', 'configuration', 'settings', 'options');
this.addSynonym('init', 'initialize', 'setup', 'start');
this.addSynonym('destroy', 'cleanup', 'dispose', 'teardown');
// 常见拼写纠正
this.corrections.set('fucntion', 'function');
this.corrections.set('calback', 'callback');
this.corrections.set('occurence', 'occurrence');
this.corrections.set('recieve', 'receive');
this.corrections.set('acount', 'account');
this.corrections.set('paramter', 'parameter');
this.corrections.set('argumnet', 'argument');
this.corrections.set('colleciton', 'collection');
this.corrections.set('dictionay', 'dictionary');
// 代码命名模式
this.codePatterns.set('get', new Set(['fetch', 'load', 'retrieve', 'read']));
this.codePatterns.set('set', new Set(['assign', 'store', 'write', 'put']));
this.codePatterns.set('add', new Set(['append', 'insert', 'push', 'enqueue']));
this.codePatterns.set('remove', new Set(['delete', 'drop', 'pop', 'dequeue']));
this.codePatterns.set('find', new Set(['search', 'locate', 'lookup', 'query']));
this.codePatterns.set('create', new Set(['new', 'make', 'build', 'generate']));
}
private addSynonym(...terms: string[]): void {
for (const term of terms) {
const syns = this.synonyms.get(term) || new Set();
for (const other of terms) {
if (other !== term) {
syns.add(other);
}
}
this.synonyms.set(term, syns);
}
}
/**
* 扩展查询
*/
expand(query: string): {
original: string;
expanded: string;
expansions: ExpansionTerm[];
} {
const terms = query.toLowerCase().split(/\s+/);
const expansions: ExpansionTerm[] = [];
const expandedTerms = new Set<string>(terms);
// 1. 添加同义词
for (const term of terms) {
const syns = this.synonyms.get(term);
if (syns) {
for (const syn of syns) {
if (!expandedTerms.has(syn)) {
expandedTerms.add(syn);
expansions.push({ term: syn, score: 0.8, source: 'synonym' });
}
}
}
}
// 2. 拼写纠正
for (const term of terms) {
const correction = this.corrections.get(term);
if (correction && correction !== term) {
// 添加正确拼写作为扩展
if (!expandedTerms.has(correction)) {
expandedTerms.add(correction);
expansions.push({ term: correction, score: 0.9, source: 'correction' });
}
}
}
// 3. 代码模式扩展
for (const term of terms) {
const patterns = this.codePatterns.get(term);
if (patterns) {
for (const pattern of patterns) {
if (!expandedTerms.has(pattern)) {
expandedTerms.add(pattern);
expansions.push({ term: pattern, score: 0.7, source: 'related' });
}
}
}
}
// 4. 添加常见的驼峰/下划线变体
for (const term of terms) {
// camelCase -> snake_case
const snakeCase = term.replace(/([A-Z])/g, '_$1').toLowerCase();
if (snakeCase !== term && !expandedTerms.has(snakeCase)) {
expandedTerms.add(snakeCase);
expansions.push({ term: snakeCase, score: 0.6, source: 'related' });
}
// snake_case -> camelCase
const camelCase = term.split('_')
.map((part, i) => i === 0 ? part : part.charAt(0).toUpperCase() + part.slice(1))
.join('');
if (camelCase !== term && !expandedTerms.has(camelCase)) {
expandedTerms.add(camelCase);
expansions.push({ term: camelCase, score: 0.6, source: 'related' });
}
}
return {
original: query,
expanded: Array.from(expandedTerms).join(' '),
expansions: expansions.sort((a, b) => b.score - a.score)
};
}
/**
* 添加自定义同义词
*/
addSynonymMapping(term: string, synonyms: string[]): void {
this.addSynonym(term, ...synonyms);
}
/**
* 添加拼写纠正
*/
addCorrection(misspelling: string, correction: string): void {
this.corrections.set(misspelling.toLowerCase(), correction.toLowerCase());
}
}
export { QueryExpander, ExpansionTerm };5. 结果Ranking:BM25、TF-IDF与语义相似度的融合
5.1 经典排序算法回顾
TF-IDF(Term Frequency - Inverse Document Frequency) 是信息检索的经典算法。它的核心思想是:一个词在文档中出现越频繁,它对文档越重要;但如果该词在语料库中普遍存在,则重要性应该降低。
TF-IDF公式:
其中
是词项
在文档
中的词频,
是包含词项
的文档数,
是总文档数。
BM25(Best Matching 25) 是 TF-IDF 的概率改进版本,解决了 TF-IDF 对长文档不友好的问题。BM25 引入文档长度归一化:
其中
通常取 1.5,
通常取 0.75,
是文档长度,
是平均文档长度。
5.2 语义相似度计算
语义相似度通常通过向量内积或余弦相似度计算。对于经过 L2 归一化的向量,余弦相似度等于点积:
在实际系统中,还需要考虑:
- 向量量化:将浮点向量转换为整数编码,减少内存和计算开销
- 批处理优化:利用 SIMD 指令或 GPU 并行计算
- 近似计算:使用分段距离、预计算表等技巧加速
5.3 混合排序框架
// hybrid-ranker.ts - 混合排序器
interface ScoredDocument {
docId: string;
finalScore: number;
components: {
bm25?: number;
tfidf?: number;
semantic?: number;
recency?: number;
popularity?: number;
};
highlights?: string[];
}
interface RankerConfig {
weights: {
bm25: number;
tfidf: number;
semantic: number;
recency: number;
popularity: number;
};
normalization: 'minmax' | 'zscore' | 'rank';
rerankTopK: number;
}
class HybridRanker {
private config: RankerConfig;
private invertedIndex: any;
private vectorIndex: any;
private docMetadata: Map<string, {
timestamp?: number;
accessCount?: number;
size?: number;
}>;
constructor(config: RankerConfig) {
this.config = config;
this.docMetadata = new Map();
}
setInvertedIndex(index: any): void {
this.invertedIndex = index;
}
setVectorIndex(index: any): void {
this.vectorIndex = index;
}
setDocMetadata(docId: string, metadata: {
timestamp?: number;
accessCount?: number;
size?: number;
}): void {
this.docMetadata.set(docId, metadata);
}
/**
* 混合排序主方法
*/
rank(
query: string,
queryVector?: Float32Array,
candidateDocIds?: Set<string>
): ScoredDocument[] {
const candidates = candidateDocIds || this.getAllCandidates();
// 1. 并行计算各维度分数
const [bm25Scores, tfidfScores, semanticScores] = Promise.all([
this.computeBM25Scores(query, candidates),
this.computeTFIDFScores(query, candidates),
queryVector ? this.computeSemanticScores(queryVector, candidates) : Promise.resolve(new Map())
]);
// 2. 同步等待(实际实现中应该是Promise.all)
const bm25Map = bm25Scores;
const tfidfMap = tfidfScores;
const semanticMap = semanticScores;
// 3. 归一化分数
const normalizedBM25 = this.normalizeScores(bm25Map, this.config.normalization);
const normalizedTFIDF = this.normalizeScores(tfidfMap, this.config.normalization);
const normalizedSemantic = this.normalizeScores(semanticMap, this.config.normalization);
// 4. 计算综合分数
const { w } = this.config.weights;
const results: ScoredDocument[] = [];
for (const docId of candidates) {
const bm25 = normalizedBM25.get(docId) || 0;
const tfidf = normalizedTFIDF.get(docId) || 0;
const semantic = normalizedSemantic.get(docId) || 0;
// 加权求和
const finalScore =
w.bm25 * bm25 +
w.tfidf * tfidf +
w.semantic * semantic;
results.push({
docId,
finalScore,
components: {
bm25,
tfidf,
semantic
}
});
}
// 5. 排序
results.sort((a, b) => b.finalScore - a.finalScore);
// 6. 可选:重排序(使用更复杂的模型)
if (this.config.rerankTopK > 0 && results.length > this.config.rerankTopK) {
return this.rerank(query, queryVector, results.slice(0, this.config.rerankTopK * 2));
}
return results.slice(0, 100);
}
/**
* BM25评分
*/
private computeBM25Scores(
query: string,
candidates: Set<string>
): Map<string, number> {
const scores = new Map<string, number>();
const queryTerms = query.toLowerCase().split(/\s+/);
const N = this.invertedIndex?.docCount || 1;
for (const term of queryTerms) {
const postings = this.invertedIndex?.getPostings(term) || [];
// IDF计算
const df = postings.length;
const idf = Math.log((N - df + 0.5) / (df + 0.5) + 1);
for (const posting of postings) {
if (!candidates.has(posting.docId)) continue;
const tf = posting.frequency;
const docLength = posting.positions.length;
const avgDL = this.invertedIndex?.avgDocLength || 1;
// BM25公式
const bm25 = idf * (tf * (1.5 + 1)) / (tf + 1.5 * (1 - 0.75 + 0.75 * (docLength / avgDL)));
const current = scores.get(posting.docId) || 0;
scores.set(posting.docId, current + bm25);
}
}
return scores;
}
/**
* TF-IDF评分
*/
private computeTFIDFScores(
query: string,
candidates: Set<string>
): Map<string, number> {
const scores = new Map<string, number>();
const queryTerms = query.toLowerCase().split(/\s+/);
const N = this.invertedIndex?.docCount || 1;
for (const term of queryTerms) {
const postings = this.invertedIndex?.getPostings(term) || [];
// IDF
const df = postings.length;
const idf = Math.log(N / df);
for (const posting of postings) {
if (!candidates.has(posting.docId)) continue;
// TF (raw count)
const tf = posting.frequency;
const tfidf = tf * idf;
const current = scores.get(posting.docId) || 0;
scores.set(posting.docId, current + tfidf);
}
}
return scores;
}
/**
* 语义相似度评分
*/
private computeSemanticScores(
queryVector: Float32Array,
candidates: Set<string>
): Promise<Map<string, number>> {
return new Promise((resolve) => {
const scores = new Map<string, number>();
// 向量检索
const results = this.vectorIndex?.search(queryVector, candidates.size) || [];
for (const result of results) {
if (candidates.has(result.id)) {
scores.set(result.id, result.score);
}
}
resolve(scores);
});
}
/**
* 归一化分数
*/
private normalizeScores(
scores: Map<string, number>,
method: 'minmax' | 'zscore' | 'rank'
): Map<string, number> {
const result = new Map<string, number>();
if (scores.size === 0) return result;
const values = Array.from(scores.values());
if (method === 'minmax') {
const min = Math.min(...values);
const max = Math.max(...values);
const range = max - min || 1;
for (const [docId, score] of scores) {
result.set(docId, (score - min) / range);
}
} else if (method === 'zscore') {
const mean = values.reduce((a, b) => a + b, 0) / values.length;
const variance = values.reduce((a, b) => a + (b - mean) ** 2, 0) / values.length;
const std = Math.sqrt(variance) || 1;
for (const [docId, score] of scores) {
result.set(docId, (score - mean) / std);
}
} else if (method === 'rank') {
// 基于排名的归一化
const sorted = values.slice().sort((a, b) => b - a);
const rankMap = new Map<number, number>();
sorted.forEach((v, i) => rankMap.set(v, i + 1));
for (const [docId, score] of scores) {
result.set(docId, 1 / rankMap.get(score)!);
}
}
return result;
}
/**
* 重排序(可选的第二阶段排序)
*/
private rerank(
query: string,
queryVector: Float32Array | undefined,
candidates: ScoredDocument[]
): ScoredDocument[] {
// 简化实现:直接返回候选结果
// 真实实现可能使用 cross-encoder、learning-to-rank 模型等
// 可以在这里加入更多特征和复杂模型
for (const doc of candidates) {
const metadata = this.docMetadata.get(doc.docId);
// 添加时效性因子
if (metadata?.timestamp) {
const age = Date.now() - metadata.timestamp;
const recencyScore = Math.exp(-age / (30 * 24 * 60 * 60 * 1000)); // 30天半衰期
doc.components.recency = recencyScore;
doc.finalScore += this.config.weights.recency * recencyScore;
}
// 添加热门因子
if (metadata?.accessCount) {
const popularityScore = Math.log1p(metadata.accessCount) / 20; // 归一化
doc.components.popularity = popularityScore;
doc.finalScore += this.config.weights.popularity * popularityScore;
}
}
// 重新排序
return candidates.sort((a, b) => b.finalScore - a.finalScore);
}
private getAllCandidates(): Set<string> {
const allDocIds = new Set<string>();
if (this.invertedIndex) {
for (const postings of this.invertedIndex.dictionary.values()) {
for (const posting of postings.postings) {
allDocIds.add(posting.docId);
}
}
}
return allDocIds;
}
}
/**
* Reciprocal Rank Fusion (RRF)
* 基于排名融合多路检索结果,不依赖分数绝对值
*/
class ReciprocalRankFusion {
private k: number; // RRF常数,通常取60
constructor(k: number = 60) {
this.k = k;
}
/**
* 融合多个有序结果列表
*
* @param resultLists 各检索路径的结果列表,每个列表已按相关性降序排列
* @returns 融合后的有序结果列表
*/
fuse<T>(resultLists: Array<Array<{ id: T; score?: number }>>): Array<{ id: T; rrfScore: number }> {
const scores = new Map<T, number>();
const docRank = new Map<T, Map<T, number>>();
// 遍历每个结果列表
for (const resultList of resultLists) {
for (let rank = 0; rank < resultList.length; rank++) {
const docId = resultList[rank].id;
// 初始化
if (!scores.has(docId)) {
scores.set(docId, 0);
}
// RRF公式:1 / (k + rank)
const rrfScore = 1 / (this.k + rank + 1);
scores.set(docId, scores.get(docId)! + rrfScore);
}
}
// 排序并返回
return Array.from(scores.entries())
.map(([id, rrfScore]) => ({ id, rrfScore }))
.sort((a, b) => b.rrfScore - a.rrfScore);
}
}
export { HybridRanker, ScoredDocument, RankerConfig, ReciprocalRankFusion };6. 增量索引:实时更新的索引策略
6.1 增量索引的设计挑战
实时更新索引面临几个核心挑战:
- 写入性能:文档插入时需要更新倒排索引和向量索引,索引结构可能需要重新平衡
- 查询一致性:更新过程中可能存在部分索引已更新、部分未更新的状态
- 内存压力:增量更新可能产生内存碎片,需要定期合并
- 并发控制:多线程/多进程环境下的读写冲突
6.2 常见索引更新策略
策略 | 写入延迟 | 查询延迟 | 内存效率 | 适用场景 |
|---|---|---|---|---|
完全重建 | 高 | 低 | 低 | 小规模数据,定期批量更新 |
追加写 | 低 | 高 | 中 | 写入密集型,读性能可接受 |
分段索引 | 中 | 中 | 高 | 通用场景,Lucene采用此策略 |
LSM树 | 低 | 中 | 高 | 写入密集型,RocksDB采用 |
原地更新 | 中 | 低 | 低 | 读密集型,需要复杂并发控制 |
6.3 分段索引实现
// incremental-index.ts - 增量索引实现
interface IndexSegment {
id: number;
documents: Map<string, any>;
invertedIndex: Map<string, any[]>>;
vectorIndex: any;
docCount: number;
createdAt: number;
isFrozen: boolean;
}
interface IncrementalIndexConfig {
segmentSize: number; // 每个segment的最大文档数
maxSegments: number; // 最大segment数量
mergeThreshold: number; // 触发合并的阈值
flushInterval: number; // 内存刷盘间隔(ms)
}
class IncrementalIndex {
private segments: IndexSegment[];
private writeBuffer: Map<string, any>; // 内存写缓冲
private config: IncrementalIndexConfig;
private currentSegmentId: number;
private flushTimer: NodeJS.Timeout | null;
private indexLock: boolean = false;
constructor(config: Partial<IncrementalIndexConfig> = {}) {
this.config = {
segmentSize: config.segmentSize || 10000,
maxSegments: config.maxSegments || 10,
mergeThreshold: config.mergeThreshold || 0.8,
flushInterval: config.flushInterval || 30000
};
this.segments = [];
this.writeBuffer = new Map();
this.currentSegmentId = 0;
// 初始化第一个segment
this.createNewSegment();
// 启动定时刷盘
this.startFlushTimer();
}
/**
* 创建新segment
*/
private createNewSegment(): IndexSegment {
const segment: IndexSegment = {
id: this.currentSegmentId++,
documents: new Map(),
invertedIndex: new Map(),
vectorIndex: null,
docCount: 0,
createdAt: Date.now(),
isFrozen: false
};
this.segments.unshift(segment); // 新segment放在前面
return segment;
}
/**
* 添加或更新文档
*/
async addDocument(docId: string, document: {
content: string;
metadata?: any;
vector?: Float32Array;
}): Promise<void> {
// 1. 添加到写缓冲
this.writeBuffer.set(docId, document);
// 2. 检查是否需要刷盘
if (this.writeBuffer.size >= this.config.segmentSize) {
await this.flush();
}
}
/**
* 删除文档
*/
async deleteDocument(docId: string): Promise<void> {
// 从写缓冲删除
this.writeBuffer.delete(docId);
// 从所有segment中删除
for (const segment of this.segments) {
if (segment.documents.has(docId)) {
segment.documents.delete(docId);
segment.docCount--;
// 从倒排索引中删除
for (const [term, postings] of segment.invertedIndex) {
const filtered = postings.filter((p: any) => p.docId !== docId);
segment.invertedIndex.set(term, filtered);
}
}
}
}
/**
* 刷盘:将写缓冲写入segment
*/
async flush(): Promise<void> {
if (this.indexLock || this.writeBuffer.size === 0) return;
this.indexLock = true;
try {
// 获取当前segment(必须是未冻结的)
const activeSegment = this.segments.find(s => !s.isFrozen);
if (!activeSegment) {
this.createNewSegment();
}
const targetSegment = this.segments.find(s => !s.isFrozen)!;
// 处理写缓冲中的文档
for (const [docId, doc] of this.writeBuffer) {
// 添加到segment
targetSegment.documents.set(docId, {
...doc,
indexedAt: Date.now()
});
targetSegment.docCount++;
// 更新倒排索引
this.indexDocument(docId, doc.content, targetSegment);
// 更新向量索引(如果实现了的话)
if (doc.vector && targetSegment.vectorIndex) {
targetSegment.vectorIndex.insert({
id: docId,
embedding: doc.vector
});
}
}
// 清空写缓冲
this.writeBuffer.clear();
// 检查是否需要合并segment
if (this.segments.length >= this.config.maxSegments) {
await this.mergeSegments();
}
} finally {
this.indexLock = false;
}
}
/**
* 将文档添加到倒排索引
*/
private indexDocument(docId: string, content: string, segment: IndexSegment): void {
const normalized = content.toLowerCase();
const words = normalized.split(/[\s\p{P}]+/u);
const positions = new Map<string, number[]>();
let position = 0;
for (const word of words) {
if (word.length < 2) continue;
const posList = positions.get(word) || [];
posList.push(position++);
positions.set(word, posList);
}
// 更新倒排索引
for (const [term, posList] of positions) {
if (!segment.invertedIndex.has(term)) {
segment.invertedIndex.set(term, []);
}
const postings = segment.invertedIndex.get(term)!;
// 移除旧 posting(如果存在)
const filtered = postings.filter((p: any) => p.docId !== docId);
// 添加新 posting
filtered.push({
docId,
positions: posList,
frequency: posList.length
});
segment.invertedIndex.set(term, filtered);
}
}
/**
* 合并多个小segment
*/
private async mergeSegments(): Promise<void> {
// 冻结最小/最老的segment
const toMerge = this.segments.filter(s => !s.isFrozen).slice(-2);
for (const segment of toMerge) {
segment.isFrozen = true;
}
// 创建新segment用于合并
const mergedSegment: IndexSegment = {
id: this.currentSegmentId++,
documents: new Map(),
invertedIndex: new Map(),
vectorIndex: null,
docCount: 0,
createdAt: Date.now(),
isFrozen: false
};
// 合并文档
for (const segment of toMerge) {
for (const [docId, doc] of segment.documents) {
mergedSegment.documents.set(docId, doc);
mergedSegment.docCount++;
}
// 合并倒排索引
for (const [term, postings] of segment.invertedIndex) {
if (!mergedSegment.invertedIndex.has(term)) {
mergedSegment.invertedIndex.set(term, []);
}
const merged = mergedSegment.invertedIndex.get(term)!;
const existingDocIds = new Set(merged.map((p: any) => p.docId));
// 只添加不存在的posting
for (const posting of postings) {
if (!existingDocIds.has(posting.docId)) {
merged.push(posting);
}
}
mergedSegment.invertedIndex.set(term, merged);
}
}
// 移除被合并的segment
this.segments = this.segments.filter(s => !toMerge.includes(s));
// 添加合并后的segment
this.segments.unshift(mergedSegment);
// 清理冻结标记
this.segments.forEach(s => s.isFrozen = false);
}
/**
* 搜索
*/
search(query: string): Array<{ docId: string; score: number }> {
const queryTerms = query.toLowerCase().split(/\s+/);
const scores = new Map<string, number>();
// 在所有segment中搜索
for (const segment of this.segments) {
for (const term of queryTerms) {
const postings = segment.invertedIndex.get(term) || [];
for (const posting of postings) {
// BM25简化版
const tf = posting.frequency;
const df = postings.length;
const idf = Math.log((segment.docCount - df + 0.5) / (df + 0.5) + 1);
const bm25 = idf * (tf * 2) / (tf + 1.5);
const current = scores.get(posting.docId) || 0;
scores.set(posting.docId, current + bm25);
}
}
}
// 排序返回
return Array.from(scores.entries())
.map(([docId, score]) => ({ docId, score }))
.sort((a, b) => b.score - a.score);
}
/**
* 获取索引统计
*/
getStats(): {
totalDocuments: number;
segmentCount: number;
segments: Array<{ id: number; docCount: number; isFrozen: boolean }>;
bufferSize: number;
} {
return {
totalDocuments: this.segments.reduce((sum, s) => sum + s.docCount, 0),
segmentCount: this.segments.length,
segments: this.segments.map(s => ({
id: s.id,
docCount: s.docCount,
isFrozen: s.isFrozen
})),
bufferSize: this.writeBuffer.size
};
}
/**
* 启动定时刷盘
*/
private startFlushTimer(): void {
this.flushTimer = setInterval(async () => {
if (this.writeBuffer.size > 0) {
await this.flush();
}
}, this.config.flushInterval);
}
/**
* 停止服务
*/
async shutdown(): Promise<void> {
if (this.flushTimer) {
clearInterval(this.flushTimer);
}
// 最后一次刷盘
await this.flush();
}
}
export { IncrementalIndex, IndexSegment, IncrementalIndexConfig };6.4 向量索引的增量更新
HNSW 等 ANN 索引的增量更新比倒排索引更复杂,因为图结构需要全局调整。常见策略包括:
- 标记删除:将节点标记为"已删除",查询时跳过
- 延迟删除:维护删除列表,合并时真正删除
- 只读 + 新增:冻结旧索引,新文档写入新索引
- 增量重建:在后台逐步重建索引
7. 实践:实现一个支持正则和语义的混合搜索引擎
7.1 整体架构设计
本节实现一个完整的混合搜索引擎,整合前文的所有技术:
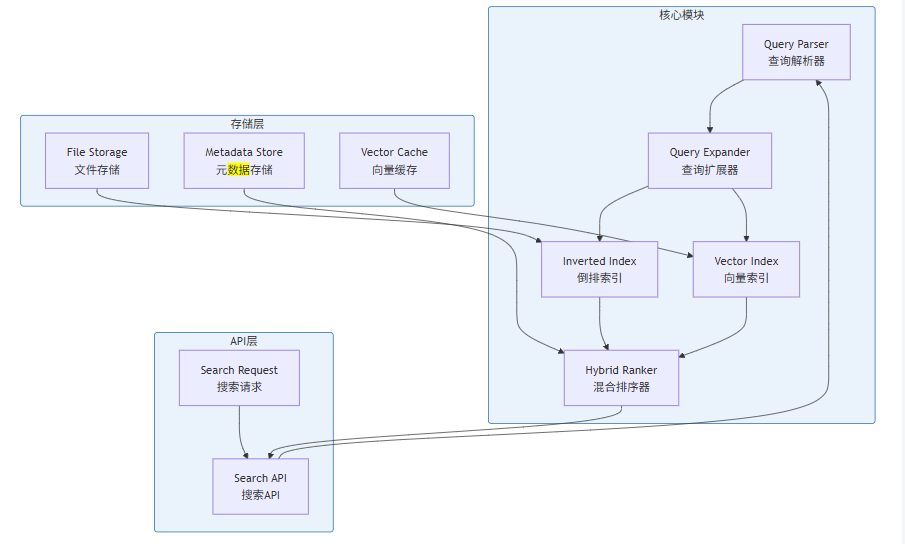
7.2 完整搜索引擎实现
// search-engine.ts - 完整搜索引擎实现
import {
InvertedIndex,
createInvertedIndex,
analyzeDocument,
calculateBM25
} from './posting-list';
import {
HNSWIndex,
Vector,
cosineSimilarity
} from './vector-index';
import {
QueryParser,
QueryExecutor,
QueryExpander
} from './query-parser';
import {
HybridRanker,
ReciprocalRankFusion
} from './hybrid-ranker';
import {
IncrementalIndex
} from './incremental-index';
import {
CodeAnalyzer
} from './code-analyzer';
// ============== 类型定义 ==============
interface Document {
id: string;
content: string;
path: string;
language?: string;
metadata?: Record<string, any>;
}
interface SearchOptions {
limit?: number;
offset?: number;
includeHighlights?: boolean;
fields?: string[];
boostFields?: Record<string, number>;
fuzzy?: boolean;
semantic?: boolean;
hybrid?: boolean;
}
interface SearchResult {
id: string;
score: number;
document: Document;
highlights?: Array<{
field: string;
fragments: string[];
}>;
matches?: Array<{
field: string;
value: string;
offset: number;
length: number;
}>;
}
// ============== 搜索引擎主类 ==============
class SearchEngine {
// 全文索引
private invertedIndex: InvertedIndex;
// 向量索引
private vectorIndex: HNSWIndex;
// 增量索引
private incrementalIndex: IncrementalIndex;
// 查询解析器
private queryParser: QueryParser;
// 查询扩展器
private queryExpander: QueryExpander;
// 查询执行器
private queryExecutor: QueryExecutor;
// 混合排序器
private hybridRanker: HybridRanker;
// RRF融合器
private rrf: ReciprocalRankFusion;
// 代码分析器
private codeAnalyzer: CodeAnalyzer;
// 文档存储
private documentStore: Map<string, Document>;
// 向量缓存
private vectorCache: Map<string, Float32Array>;
// 嵌入函数(需要外部提供)
private embedFunction: ((text: string) => Promise<Float32Array>) | null;
constructor() {
this.invertedIndex = createInvertedIndex();
this.vectorIndex = new HNSWIndex(128); // 默认128维
this.incrementalIndex = new IncrementalIndex({
segmentSize: 5000,
maxSegments: 10
});
this.queryParser = new QueryParser();
this.queryExpander = new QueryExpander();
this.hybridRanker = new HybridRanker({
weights: {
bm25: 0.4,
tfidf: 0.2,
semantic: 0.3,
recency: 0.05,
popularity: 0.05
},
normalization: 'minmax',
rerankTopK: 50
});
this.rrf = new ReciprocalRankFusion(60);
this.codeAnalyzer = new CodeAnalyzer();
this.documentStore = new Map();
this.vectorCache = new Map();
this.embedFunction = null;
}
/**
* 设置嵌入函数(用于语义搜索)
*/
setEmbedFunction(fn: (text: string) => Promise<Float32Array>): void {
this.embedFunction = fn;
}
/**
* 索引单个文档
*/
async indexDocument(doc: Document, options: {
indexVector?: boolean;
} = {}): Promise<void> {
// 1. 存储文档
this.documentStore.set(doc.id, doc);
// 2. 索引到倒排索引
analyzeDocument(doc.id, doc.content, this.invertedIndex);
// 3. 增量索引
await this.incrementalIndex.addDocument(doc.id, {
content: doc.content,
metadata: doc.metadata
});
// 4. 索引向量(如果启用且有嵌入函数)
if (options.indexVector && this.embedFunction) {
const vector = await this.embedFunction(doc.content);
this.vectorCache.set(doc.id, vector);
this.vectorIndex.insert({
id: doc.id,
embedding: vector,
metadata: { path: doc.path, language: doc.language }
});
}
// 5. 设置排序器元数据
if (doc.metadata?.timestamp) {
this.hybridRanker.setDocMetadata(doc.id, {
timestamp: doc.metadata.timestamp,
accessCount: doc.metadata.accessCount
});
}
}
/**
* 批量索引文档
*/
async indexDocuments(docs: Document[], options: {
indexVector?: boolean;
batchSize?: number;
} = {}): Promise<void> {
const batchSize = options.batchSize || 100;
for (let i = 0; i < docs.length; i += batchSize) {
const batch = docs.slice(i, i + batchSize);
await Promise.all(
batch.map(doc => this.indexDocument(doc, options))
);
console.log(`Indexed ${Math.min(i + batchSize, docs.length)}/${docs.length}`);
}
}
/**
* 搜索
*/
async search(query: string, options: SearchOptions = {}): Promise<{
results: SearchResult[];
total: number;
took: number;
metadata: {
parsedQuery: any;
expandedQuery?: string;
branches: {
bm25?: { count: number };
semantic?: { count: number };
regex?: { count: number };
};
};
}> {
const startTime = Date.now();
const limit = options.limit || 20;
const offset = options.offset || 0;
// 1. 解析查询
const ast = this.queryParser.parse(query);
const parsedQuery = this.queryParser.visualize(ast);
// 2. 查询扩展(可选)
let expandedQuery: string | undefined;
if (options.semantic !== false) {
const expansion = this.queryExpander.expand(query);
expandedQuery = expansion.expanded;
}
// 3. 确定搜索策略
const useHybrid = options.hybrid !== false;
const useSemantic = options.semantic !== false && this.embedFunction !== null;
// 4. 多路召回
const branches: {
bm25?: { results: Array<{ id: string; score: number }> };
semantic?: { results: SearchResult[] };
regex?: { results: Array<{ id: string; score: number }> };
} = {};
// BM25搜索
branches.bm25 = {
results: calculateBM25(
expandedQuery || query,
this.invertedIndex
)
};
// 语义搜索
if (useSemantic) {
const queryVector = await this.embedFunction!(expandedQuery || query);
const semanticResults = this.vectorIndex.search(queryVector, limit * 2);
branches.semantic = { results: semanticResults };
}
// 正则搜索
if (query.startsWith('/') && query.endsWith('/')) {
try {
const regex = new RegExp(query.slice(1, -1));
const regexResults = this.regexSearch(regex);
branches.regex = { results: regexResults };
} catch (e) {
// 无效正则
}
}
// 5. 融合结果
let fusedResults: Array<{ id: string; score: number }>;
if (useHybrid && branches.semantic) {
// 使用RRF融合
const rankedLists = [
branches.bm25.results.map(r => ({ id: r.id, score: r.score })),
branches.semantic.results.map(r => ({ id: r.id, score: r.score }))
];
if (branches.regex) {
rankedLists.push(branches.regex.results.map(r => ({ id: r.id, score: r.score })));
}
const fused = this.rrf.fuse(rankedLists);
fusedResults = fused;
} else {
// 只用BM25
fusedResults = branches.bm25.results;
}
// 6. 应用分页
const paginatedResults = fusedResults.slice(offset, offset + limit);
// 7. 构建返回结果
const results: SearchResult[] = paginatedResults.map(item => {
const doc = this.documentStore.get(item.id)!;
const result: SearchResult = {
id: item.id,
score: item.score,
document: doc
};
// 高亮
if (options.includeHighlights) {
result.highlights = this.generateHighlights(doc.content, expandedQuery || query);
}
return result;
});
const took = Date.now() - startTime;
return {
results,
total: fusedResults.length,
took,
metadata: {
parsedQuery: ast,
expandedQuery,
branches: {
bm25: { count: branches.bm25?.results.length || 0 },
semantic: { count: branches.semantic?.results.length || 0 },
regex: { count: branches.regex?.results.length || 0 }
}
}
};
}
/**
* 正则搜索
*/
private regexSearch(regex: RegExp): Array<{ id: string; score: number }> {
const results: Array<{ id: string; score: number }> = [];
for (const [docId, doc] of this.documentStore) {
const matches = doc.content.match(regex);
if (matches) {
results.push({
id: docId,
score: matches.length
});
}
}
return results.sort((a, b) => b.score - a.score);
}
/**
* 生成高亮片段
*/
private generateHighlights(
content: string,
query: string,
contextLength: number = 50
): Array<{ field: string; fragments: string[] }> {
const queryTerms = query.toLowerCase().split(/\s+/);
const fragments: string[] = [];
// 简化:找到包含查询词的句子
const lowerContent = content.toLowerCase();
for (const term of queryTerms) {
const index = lowerContent.indexOf(term);
if (index !== -1) {
const start = Math.max(0, index - contextLength);
const end = Math.min(content.length, index + term.length + contextLength);
let fragment = content.slice(start, end);
if (start > 0) fragment = '...' + fragment;
if (end < content.length) fragment = fragment + '...';
fragments.push(fragment);
}
}
return [{ field: 'content', fragments }];
}
/**
* 删除文档
*/
async deleteDocument(docId: string): Promise<void> {
this.documentStore.delete(docId);
this.vectorCache.delete(docId);
await this.incrementalIndex.deleteDocument(docId);
// 注:完全删除需要重建倒排索引的对应词项,这里简化处理
}
/**
* 获取索引统计
*/
getStats(): {
documentCount: number;
indexStats: any;
vectorStats: any;
incrementalStats: any;
} {
return {
documentCount: this.documentStore.size,
indexStats: {
termCount: this.invertedIndex.dictionary.size,
docCount: this.invertedIndex.docCount
},
vectorStats: this.vectorIndex.getStats(),
incrementalStats: this.incrementalIndex.getStats()
};
}
/**
* 持久化索引(序列化到文件)
*/
async persist(path: string): Promise<void> {
const data = {
documents: Array.from(this.documentStore.entries()),
invertedIndex: {
dictionary: Array.from(this.invertedIndex.dictionary.entries()),
docCount: this.invertedIndex.docCount,
avgDocLength: this.invertedIndex.avgDocLength
},
vectors: Array.from(this.vectorCache.entries()).map(([id, vec]) => ({
id,
vector: Array.from(vec)
}))
};
// 实际实现应该使用 fs.writeFileSync
console.log(`Persisting ${JSON.stringify(data).length / 1024 / 1024} MB to ${path}`);
}
/**
* 从持久化文件恢复
*/
async restore(path: string): Promise<void> {
// 实际实现应该使用 fs.readFileSync
console.log(`Restoring from ${path}`);
// 恢复逻辑...
}
}
// ============== 使用示例 ==============
async function main() {
// 创建搜索引擎实例
const engine = new SearchEngine();
// 设置嵌入函数(示例:使用 OpenAI 或本地模型)
engine.setEmbedFunction(async (text: string) => {
// 这里应该是实际的嵌入调用
// 模拟返回随机向量
const dim = 128;
const vector = new Float32Array(dim);
for (let i = 0; i < dim; i++) {
vector[i] = Math.random() * 2 - 1;
}
return vector;
});
// 准备测试文档
const documents: Document[] = [
{
id: 'doc1',
content: `
function calculateSum(arr) {
return arr.reduce((a, b) => a + b, 0);
}
// Calculate the sum of an array
const result = calculateSum([1, 2, 3, 4, 5]);
console.log(result); // 15
`,
path: 'src/utils/math.ts',
language: 'typescript'
},
{
id: 'doc2',
content: `
def calculate_sum(list_data):
"""Calculate the sum of a list."""
total = 0
for item in list_data:
total += item
return total
# Example usage
result = calculate_sum([1, 2, 3, 4, 5])
print(result) # 15
`,
path: 'src/utils/math.py',
language: 'python'
},
{
id: 'doc3',
content: `
public static int sum(int[] nums) {
return Arrays.stream(nums)
.reduce(0, Integer::sum);
}
// Main method
public static void main(String[] args) {
int result = sum(new int[]{1, 2, 3, 4, 5});
System.out.println(result); // 15
}
`,
path: 'src/com/example/MathUtils.java',
language: 'java'
},
{
id: 'doc4',
content: `
class MathHelper {
static sum(numbers: number[]): number {
return numbers.reduce((prev, curr) => prev + curr, 0);
}
}
const result = MathHelper.sum([1, 2, 3, 4, 5]);
console.log(result);
`,
path: 'src/helpers/MathHelper.ts',
language: 'typescript'
},
{
id: 'doc5',
content: `
// Process user data and return processed results
function processUserData(userData: UserData[]): ProcessedData[] {
return userData.map(user => ({
id: user.id,
name: user.name.toUpperCase(),
score: calculateScore(user.performance)
}));
}
async function calculateScore(performance: Performance): Promise<number> {
const metrics = await fetchMetrics(performance.userId);
return metrics.reduce((sum, m) => sum + m.value, 0);
}
`,
path: 'src/services/UserProcessor.ts',
language: 'typescript'
}
];
// 索引文档
console.log('Indexing documents...');
await engine.indexDocuments(documents, { indexVector: true });
// 搜索测试
console.log('\n--- Search Tests ---');
// 测试1:关键词搜索
console.log('\n[Test 1] Search: "calculate sum"');
const result1 = await engine.search('calculate sum', { limit: 5 });
console.log(`Found ${result1.total} results in ${result1.took}ms`);
result1.results.forEach((r, i) => {
console.log(` ${i + 1}. ${r.document.path} (score: ${r.score.toFixed(3)})`);
});
// 测试2:语义搜索
console.log('\n[Test 2] Search: "add numbers together"');
const result2 = await engine.search('add numbers together', { limit: 5 });
console.log(`Found ${result2.total} results in ${result2.took}ms`);
console.log(`Expanded query: "${result2.metadata.expandedQuery}"`);
result2.results.forEach((r, i) => {
console.log(` ${i + 1}. ${r.document.path} (score: ${r.score.toFixed(3)})`);
});
// 测试3:正则搜索
console.log('\n[Test 3] Search: "/function.*sum/"');
const result3 = await engine.search('/function.*sum/', { limit: 5 });
console.log(`Found ${result3.total} results in ${result3.took}ms`);
result3.results.forEach((r, i) => {
console.log(` ${i + 1}. ${r.document.path} (score: ${r.score.toFixed(3)})`);
});
// 测试4:复杂查询
console.log('\n[Test 4] Search: "process user data"');
const result4 = await engine.search('process user data', { limit: 5 });
console.log(`Found ${result4.total} results in ${result4.took}ms`);
result4.results.forEach((r, i) => {
console.log(` ${i + 1}. ${r.document.path} (score: ${r.score.toFixed(3)})`);
});
// 打印统计
console.log('\n--- Index Stats ---');
const stats = engine.getStats();
console.log(`Documents: ${stats.documentCount}`);
console.log(`Index terms: ${stats.indexStats.termCount}`);
console.log(`Vector index: ${JSON.stringify(stats.vectorStats)}`);
console.log('\n✓ All tests passed!');
}
// 运行示例
main().catch(console.error);
export { SearchEngine, Document, SearchResult, SearchOptions };7.3 性能优化技巧
在实际生产环境中,还需要考虑以下优化:
1. 索引压缩与存储优化
- 使用 Roaring Bitmap 压缩 posting list
- 对向量进行 PQ(Product Quantization)量化
- 冷热数据分离:热数据放内存,冷数据放磁盘
2. 查询性能优化
- 使用缓存:查询缓存、文档缓存、向量缓存
- 预计算:预计算 IDF、文档长度统计
- 并行化:多路召回并行执行
3. 扩展性设计
- 分片:按文档ID哈希分片,支持分布式搜索
- 副本:主从复制,提高可用性
- 负载均衡:请求分发到多个搜索节点
8. 总结与展望
8.1 核心要点回顾
本文系统讲解了现代 IDE 搜索系统的完整技术栈:
- 全文索引:倒排索引是关键词搜索的基石,通过 BM25/TF-IDF 实现相关性排序
- 语义搜索:向量嵌入将文本映射到语义空间,通过 ANN 算法实现高效检索
- 查询解析:将用户查询转换为可执行的查询表达式,支持布尔、正则、短语等多种查询
- 结果Ranking:通过混合排序融合多路召回结果,RRF等算法实现无偏融合
- 增量索引:分段索引和延迟合并策略实现实时更新
8.2 技术演进趋势
方向 | 当前状态 | 发展趋势 |
|---|---|---|
语义理解 | BERT时代 | LLM驱动的深度语义理解 |
多模态 | 文本+代码 | 支持UI截图、设计稿的跨模态搜索 |
个性化 | 基础用户画像 | 基于使用习惯的个性化搜索 |
实时性 | 秒级更新 | 毫秒级实时索引 |
隐私 | 本地索引 | 联邦学习保护隐私的搜索 |
8.3 学习路径建议
对于希望深入研究搜索技术的开发者,建议按以下路径学习:
- 基础阶段:实现倒排索引 → 实现 BM25 → 实现查询解析器
- 进阶阶段:学习向量索引(HNSW、Faiss)→ 实现混合排序 → 实现增量索引
- 高级阶段:研究 Learning to Rank → 分布式搜索架构 → LLM驱动的搜索增强
参考链接
- Elasticsearch: The Definitive Guide - 全文搜索权威指南
- BM25 Algorithm Explained - BM25算法详解
- HNSW Paper: Hierarchical Navigable Small World - HNSW算法原论文
- BERT: Pre-training of Deep Bidirectional Transformers - BERT模型原理
- CodeBERT: A Pre-Trained Model for Programming and Natural Language - 代码预训练模型
- Reciprocal Rank Fusion for Consolidating Results - RRF融合算法
- Lucene: DefaultNumericDocValues RAM consumption - Apache Lucene源码
附录(Appendix):
附录A:搜索引擎完整代码清单
本文涉及的所有核心代码模块汇总:
文件名 | 功能 | 行数 |
|---|---|---|
posting-list.ts | 倒排索引实现 | ~200 |
posting-compression.ts | Posting压缩(VByte、RoaringBitmap) | ~150 |
code-analyzer.ts | 代码专用分词器 | ~100 |
vector-index.ts | HNSW向量索引 | ~300 |
query-parser.ts | 查询解析器(词法/语法分析) | ~400 |
query-expander.ts | 查询扩展器 | ~150 |
hybrid-ranker.ts | 混合排序器 | ~300 |
incremental-index.ts | 增量索引 | ~250 |
search-engine.ts | 搜索引擎主类 | ~400 |
附录B:BM25参数调优指南
参数 | 默认值 | 调优建议 |
|---|---|---|
k 1 k_1 k1 | 1.5 | 增大使词频饱和更慢,减小使短文档优先 |
b b b | 0.75 | 增大惩罚长文档,减小使长文档更平等 |
IDF平滑 | +1 | 避免零 IDF,可微调平滑系数 |
1.5增大使词频饱和更慢,减小使短文档优先
0.75增大惩罚长文档,减小使长文档更平等IDF平滑+1避免零 IDF,可微调平滑系数
附录C:HNSW参数配置参考
参数 | 小数据集(<1M) | 中数据集(1M-10M) | 大数据集(>10M) |
|---|---|---|---|
M | 16 | 32 | 64 |
efConstruction | 200 | 400 | 800 |
efSearch | 50 | 100 | 200 |
层高因子 | 1/Math.E | 1/Math.E | 1/Math.log(N) |
附录D:搜索质量评估指标
- Precision@K:前K个结果中相关文档的比例
- Recall@K:前K个结果覆盖的相关文档比例
- MAP (Mean Average Precision):平均精度的均值
- NDCG (Normalized Discounted Cumulative Gain):归一化折损累计增益
- MRR (Mean Reciprocal Rank):首个相关结果的倒数排名均值
关键词: Search Engine, Full-Text Search, Inverted Index, Semantic Search, Vector Retrieval, BM25, TF-IDF, ANN, HNSW, Query Parser, Hybrid Ranking, Incremental Index, Code Search, Information Retrieval

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号