IM分布式架构系列(08)10000长连接显示在线 | 30%其实是死Session
原创
IM分布式架构系列(08)10000长连接显示在线 | 30%其实是死Session
原创
拉丁解牛说技术
发布于 2026-06-01 00:17:52
发布于 2026-06-01 00:17:52
上小学的时候,记得班里两侧经常挂各种名人名句,比如特别喜欢华罗庚的:聪明在于勤奋,天才在于积累!他的经历告诉了我们:学历,只能决定你的起点;决定你走多远的,是离开学校之后还学不学;
大多数人,毕业那天,就是他这辈子学习的终点。
一、为什么"显示在线"不等于"真的在线"
二、连接会话管理的关键设计
三、大厂如何设计
四、如何优化提升
一、为什么"显示在线"不等于"真的在线"
凌晨梦里和小美在吃饭,运维同学甩来一个急电:接入层显示 1 万多条活跃长连接,TCP 状态全是 ESTABLISHED,看着一片绿。但当天的推送到达率却异常地低。睡不着,开机抽样排查后发现一个后背发凉的数字——这些"在线"连接里,有近三成根本推不动消息,对端早就不在了。连接还挂在那儿,只是没人告诉服务端它已经死了。
这就是 Session 管理最反直觉的地方:一条 TCP 连接"看起来活着"和"真的能送达消息",是两件事。中间这道缝,就是死连接(half-open,半开连接)藏身的地方。今天咱们聊聊接入层的连接会话管理——为什么大量连接会"显示在线、其实已死",怎么发现它们,在线状态该怎么存,以及状态对不上时会捅出什么娄子。
1.1 Session 在 IM 接入层的位置
Session(连接会话)是接入层为每条客户端长连接维护的一份运行时档案:这条连接属于哪个用户、哪个设备(手机 / 桌面 / Web)、最近一次活跃是什么时候、当前在哪台接入机上。它一头连着客户端的物理连接,一头连着"这个用户现在在线"这个全局事实。
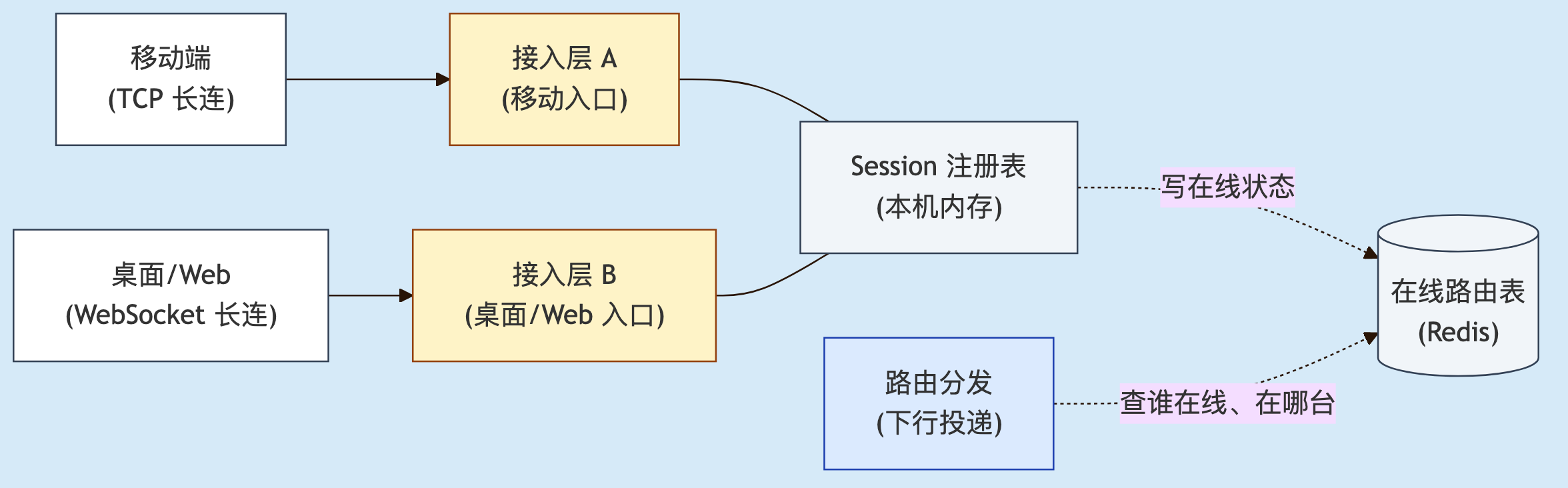
1
图 1. Session 横跨两层:每台接入机本机内存里有一份连接注册表,全局在线状态写在 Redis 路由表里。下行消息要送给某个用户,先查 Redis 找到"他在哪台机器",再投过去。
注意:移动端和桌面 / Web 往往不是同一套接入层。移动端多用裸 TCP 加自定义二进制协议(榨电量、省流量),桌面 / Web 用 WebSocket。两套入口、两种连接,但在线状态最终要汇到同一张全局表里——这给后面的一致性埋了第一颗雷。
1.2 死连接是怎么悄悄攒出来的
为什么连接会"死了却没人知道"?根子在 TCP 这个协议本身——它不会主动告诉你对端没了。只要没有数据要发,一条空闲的 TCP 连接可以在两端的内存里静静躺着,哪怕中间的网络早就断了。死连接主要来自这么几类场景:
- 半开连接:对端进程崩了、手机关机、或链路被切断,但没走正常的四次挥手。服务端这边还停在
ESTABLISHED,像一通对方已挂、你却还举着的电话。 - App 被系统杀死或切后台:移动端最常见。用户切到别的 App,系统为省内存把它清了,连接随之失效,服务端毫不知情。
- 网络切换:4G 切 WiFi、地铁出隧道,客户端 IP 变了,旧连接作废、新连接还没建。
- NAT 超时:运营商网关为回收资源,会淘汰一段时间没有数据往来的 NAT 映射。映射一掉,链路从中间就断了,两端却都还以为连着。
最后这条尤其阴险。微某信团队早年公开测试数据里,中国移动 2G/3G、中国联通 2G 的 NAT 老化时间都在 5 分钟左右——也就是说,只要 5 分钟没动静,链路就可能从中间烂掉。
而 TCP 自带的保活(SO_KEEPALIVE)救不了场:它默认 2 小时才发第一个探测包,等它发现连接死了,黄花菜都凉了。所以——靠 TCP 自己发现死连接对 IM 来说太慢,必须在应用层自己造一套判活机制。这套机制做得好不好,直接决定了那张在线表里有大水分。
二、连接会话管理的关键设计
- 连接数的数量级:单机几万到几十万长连接是常见量级,Session 注册表必须是高频读写还不能爆内存。
- 判活要及时:死连接要在分钟级被发现并清理,不能让在线表越攒水分越多。
- 状态尽量准:在线表是下行投递的依据,它失真,消息就投错地方或投不出去。
- 重连要快、要稳:用户切个网就掉线再重连是日常,重连过程不能把好端端的新连接给误杀了。
- 多端共存:同一个用户手机 + 桌面同时在线是常态,得分得清"哪条连接是哪个端的"。
2.2 连接生命周期与 Session 状态机
一条连接从建立到销毁,Session 跟着走一套状态机。把它画清楚,每个状态转移都是一个潜在的 bug 入口。
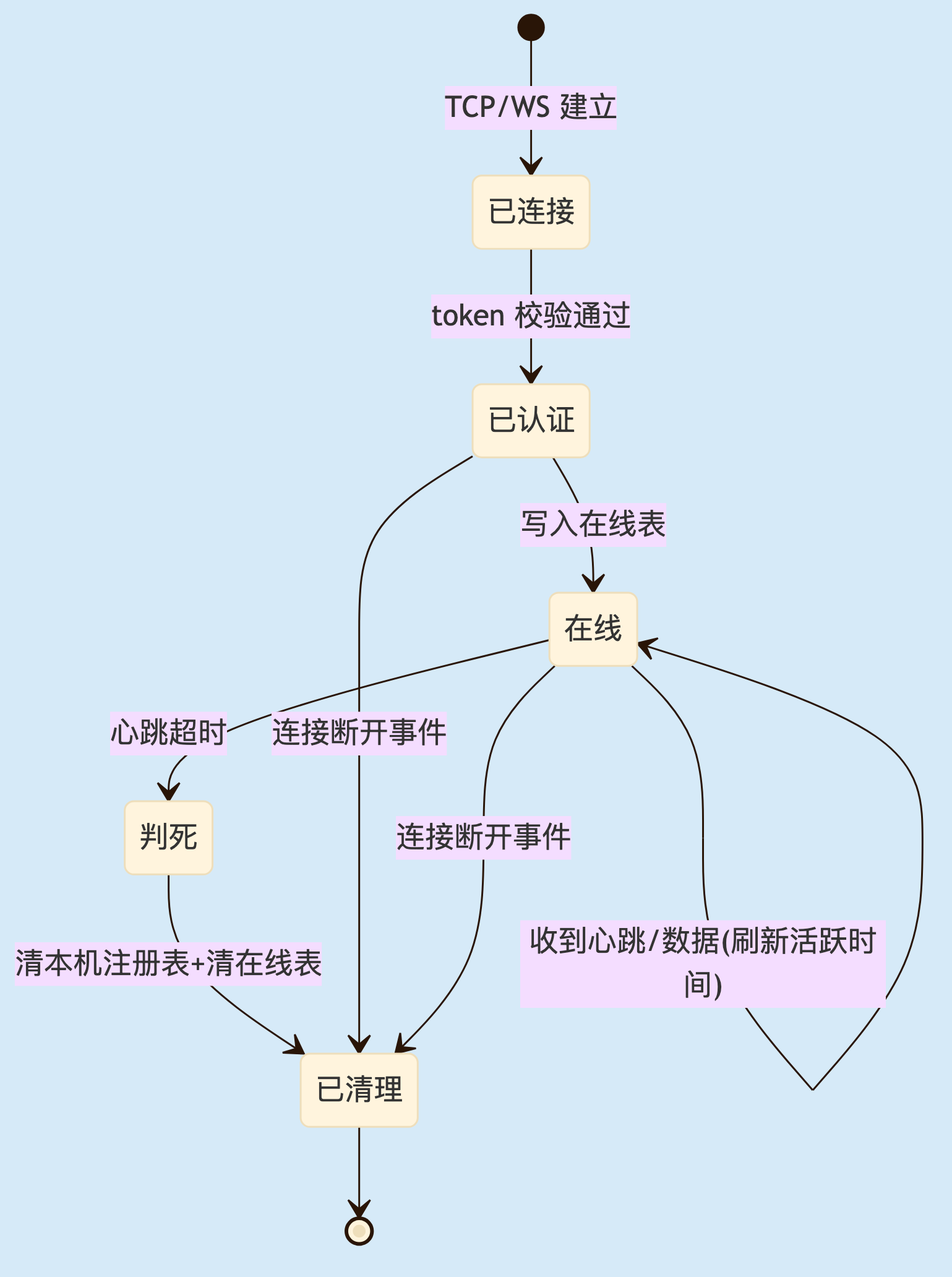
2
图 2. Session 状态机。关键点:进入"在线"才写全局在线表,离开"在线"必须清表;"判死"和"连接断开事件"是两条独立的销毁入口,缺一不可。
这里只靠"连接断开事件"清理 Session 是不够的。半开连接根本不会触发断开事件——这正是死连接攒起来的原因。所以图里必须有"判死"这条旁路销毁路径,由心跳超时兜底。两条路缺哪条,在线表都会失真。
还有个常被忽略的细节:Session 必须有 TTL 兜底。如果本机注册表是个只进不出的 Map,遇到某些异常路径(清理逻辑抛了异常没走完),死 Session 就会永久驻留,攒成内存泄漏。给每个 Session 挂最后活跃时间、配后台扫描线程定期清扫过期项,是很便宜的保险。
2.3 怎么判定一条连接已经死了
既然 TCP 靠不住,应用层判活的主力就是心跳:客户端每隔一段时间发一个轻量的心跳包,服务端收到就刷新这条连接的"最后活跃时间";超过一定时间没收到,就判定它死了。
主流的判死有三种思路,各有取舍:
维度 | 详情 |
|---|---|
固定心跳 + 超时判死 | 最简单:客户端固定 30 秒一个心跳,服务端 90 秒(约等于错过 3 次)没收到就判死。好实现、好理解,但心跳间隔是拍脑袋定的——定太短费电费流量,定太长又跨不过 NAT 超时。 |
自适应心跳 | 客户端动态探测当前网络的 NAT 超时,把心跳间隔逼近这个上限。省电省流量、判活更准,但实现复杂,要按网络类型分别探测和记忆。 |
服务端反向探测 | 服务端发现某连接长时间没动静,主动给它发一个探测帧,看对端是否回。能补客户端心跳的漏,但服务端要为每条连接维护探测调度,开销不低。 |
判死的核心其实就一行伪代码,但魔鬼在"超时阈值"和"漏网场景"里:
on_heartbeat(conn):
conn.last_active = now() // 收到心跳就续命
scan_dead_connections(): // 后台定时扫描
for conn in registry:
if now() - conn.last_active > DEAD_TIMEOUT:
close_and_cleanup(conn) // 判死,走清理流程心跳判死的局限:心跳间隔越短发现死连接越快,但客户端电量流量、服务端处理量都跟着涨,是一笔实打实的资源开销;
而且心跳"通"只证明链路此刻能传数据,不证明业务消息一定送得到(客户端进程卡死但网络栈还在回心跳);
判死有延迟窗口,从对端真死到超时触发这段时间在线表是脏的,把窗口压到分钟级是现实目标,压到秒级代价就陡增。
我们的实践经验是:移动端值得上自适应心跳(电量和 NAT 都敏感),桌面 / Web 用固定心跳就够(插着电、网络稳定),两端不必强求统一。
2.4 在线状态存哪里,为什么会漂移
判死解决的是"本机怎么知道连接死了",而在线状态要解决的是"全局怎么知道这个用户在不在线、在哪台机器"。下行投递时,路由层要先查这张表,才知道把消息投给哪台接入机。
存哪儿?答案几乎是统一的——放在一个分布式缓存里,通常就是 Redis。结构很朴素,一个用户一个 key,记着他当前所在的接入机地址和设备类型:
online:route:<uid>:<device> -> { host: "10.0.1.7:8000", since: 1716... }为什么不放进程内存或数据库?内存只有本机视角,别的机器查不到;数据库太慢,扛不住每秒成千上万次的上下线变更。Redis 在"够快"和"全局可见"之间,是大多数中等规模项目的落点。
但这张表有个绕不开的麻烦——它和真实状态一定会漂移。表里写着"在线",连接可能已经死了;写着某台机器,用户可能已经飘到另一台。漂移来自几处:判死有窗口(连接真死到心跳超时清表之间,记录是脏的);清理可能漏掉(接入机突然宕机,来不及清自己名下那批在线记录,成了孤儿);多端加重连的竞态(旧连接没清、新连接已写,两条记录打架)。
漂移了会怎样?写着在线、其实已死,消息投进黑洞,只能靠离线补偿兜底;写着某台机器、其实在另一台,消息投错地方直接丢。所以在线表不能当成绝对真理,它是个"大概率对"的索引,投递链路必须为"投不到"准备好兜底。
2.5 重连与多端下的 Session 清理
场景:用户从 4G 切到 WiFi,旧连接断了、新连接立刻建起来,同一个用户在极短时间内先后有两条连接。理想情况下旧的该清、新的该上位。但清理动作往往是异步、带延迟的——比如要等一个 ACK 确认或超时回调才真正执行。于是竞态出现了:旧连接的清理姗姗来迟,等它真正执行时,操作的却是已经换成新连接的那条会话记录——一刀砍下去,把刚建好的新连接给误杀了。
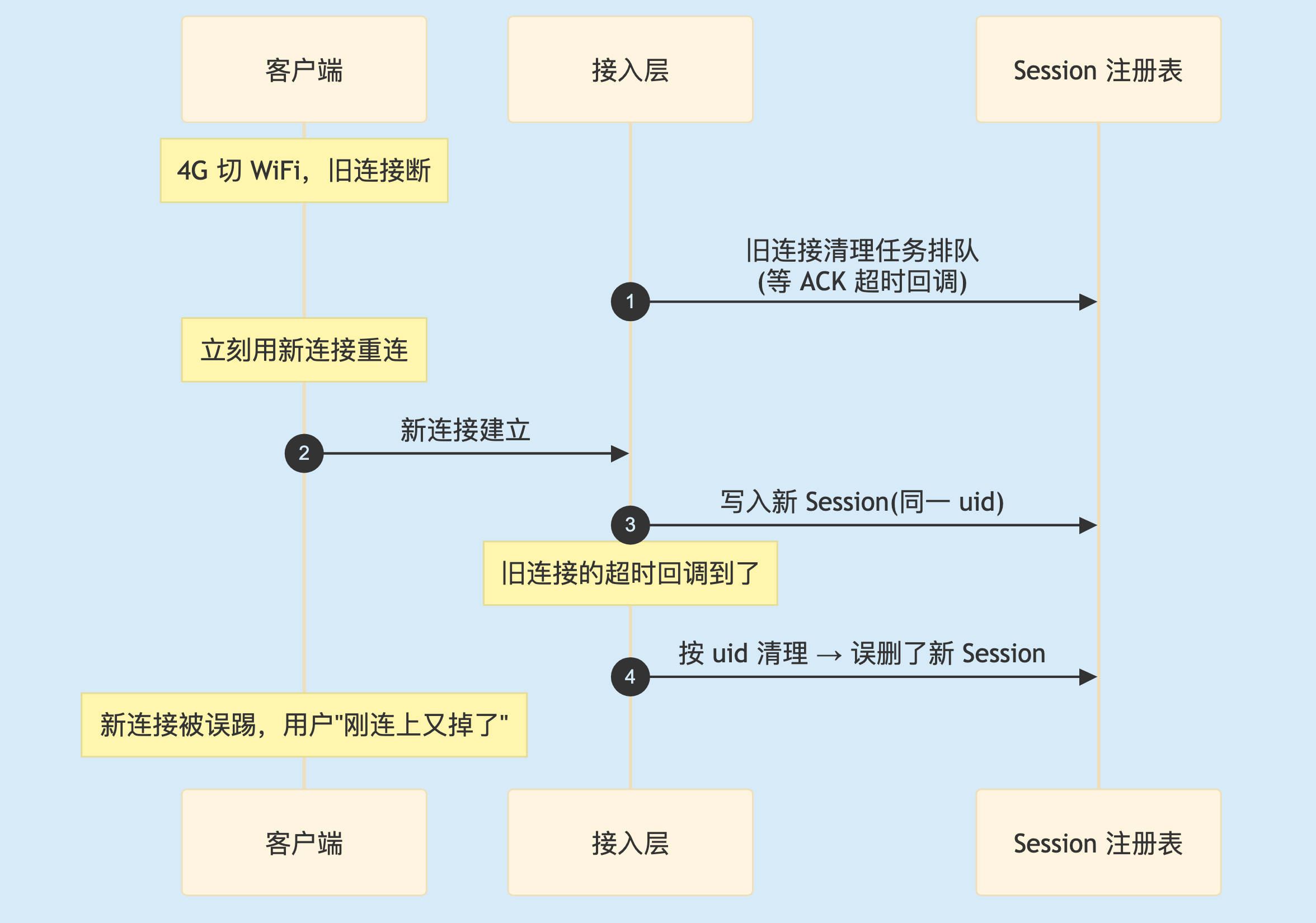
3
图 3. ACK 超时误断新连接的竞态。旧连接的延迟清理回调,按 uid 一刀切,连带把已经上位的新连接也清了。
要解决它,关键是让清理动作认得"我到底要清哪一条连接",而不是"清这个 uid 的所有连接"。常见做法是给每条连接发一个唯一标识(连接序号 / token 指纹),清理时做一次校验:
on_cleanup(uid, conn_id):
cur = registry.get(uid)
if cur != null and cur.conn_id == conn_id: // 关键:确认要清的就是当前这条
registry.remove(uid)
clear_online_table(uid, cur.device)
// 否则说明当前已是另一条新连接,放过,不动它 多端共存又叠了一层:同一用户手机和桌面各一条连接,在线表 key 必须带设备维度(<uid>:<device>),否则手机上线会把桌面的在线记录覆盖掉。互踢策略也得建在这个唯一标识之上——踢的是"同一个端的旧连接",而不是"这个用户的所有连接",否则一登录就把自己另一个端踢了。
总的来说:建连 → 认证 → 写在线表(带设备 + 连接标识)→ 心跳续命 → 断开事件或心跳判死两路兜底销毁 → 清理时用连接标识校验防误杀。每一环松一点,在线表的水分就多一点。
三、大厂如何设计
3.1 某信的智能心跳
某信团队公开分享过 Android 端的智能心跳机制。核心动机就是 2.3 说的那笔账:固定心跳要么费电、要么跨不过 NAT 超时。他们的做法是客户端动态探测当前网络的 NAT 老化时间,把心跳间隔逼近这个上限再留一点余量——按网络类型分别记忆(数据网络按运营商子类型、WiFi 按热点名做 key),还区分前后台:前台用固定心跳保实时,后台才进自适应计算,尽量挑用户不活跃的时段去试探,避免影响收消息。
维度 | 详情 |
|---|---|
优势 | 心跳间隔贴着 NAT 上限走,省电省流量;按网络记忆,换网也准;前后台分治,不牺牲前台实时性 |
代价 | 实现复杂,要做探测、记忆、临界值规避一整套;探测期本身有判死延迟;强依赖客户端配合,纯服务端改不动 |
3.2 融某云的链路保活分层
融某云公开分享过安卓端 IM 的链路保活实践——他们要面对的是被各家厂商深度定制的安卓系统和复杂网络。思路是分层保活:网络层用应用心跳维持链路、对抗 NAT 超时;进程层则要解决"App 被系统杀掉、连接随之消失"的问题,靠厂商推送通道做唤醒补位。把"链路活着"和"进程活着"当成两件事分开治,是这套做法的关键。
维度 | 详情 |
|---|---|
优势 | 分层清晰,链路保活和进程保活解耦;结合厂商推送做唤醒,兜住"进程被杀"这一大类死连接 |
代价 | 强依赖各厂商推送通道,适配成本高且受系统策略限制;保活效果随安卓版本收紧而衰减,是长期对抗 |
3.3 网某某信的在线状态同步
在线状态怎么同步给关心它的人(好友、群友),他们公开分享资料:好友状态可以推、群友状态几乎只能拉。原因是"消息风暴扩散系数"——群场景系数能飙到数百上千,推不动,只能在用户真正进入某个群时按需拉取。
维度 | 详情 |
|---|---|
优势 | 推 / 拉分场景,好友状态实时、群友状态省资源;按需拉取把扩散压力转移到真正需要的时刻 |
代价 | 群友状态非实时,用户看到的是进群那一刻的快照;推 / 拉两套逻辑都要维护,一致性边界要想清楚 |
3.4 三家做法的横向对比
维度 | 某信 | 融某云 | 网某某信 | 中小 toB 典型 |
|---|---|---|---|---|
解决的核心问题 | 心跳判活的能耗与准度 | 链路 + 进程双重保活 | 在线状态同步成本 | 在线表别失真 |
判活方式 | 自适应心跳 | 应用心跳 + 厂商唤醒 | 依赖底层连接 | 固定/自适应心跳 |
状态同步 | — | — | 好友推、群友拉 | 多按需拉取 |
实现复杂度 | 高 | 高 | 中 | 中低 |
强依赖 | 客户端配合 | 厂商推送通道 | 反向好友关系 | Redis 在线表 |
横向看,大厂的精力主要砸在"让连接更不容易死、死了更快被发现"(某信、融某云)和"在线状态怎么低成本同步出去"(网某某信)。中小 toB 项目通常没有客户端深度定制和厂商通道适配的资源,更多关注是:把心跳判死和在线表清理这两件基本功做扎实,保证那张在线表别攒太多水分,比追求秒级判活更重要。
四、如何优化提升
4.1 在线判定要有降级
在线表放 Redis 几乎是共识,但很多实现忘了问一句:Redis 挂了怎么办? 如果"查不到在线记录"被无差别地当成"用户离线",那 Redis 一抖动,全员瞬间被判离线——下行消息全转去走离线和三方推送,瞬时把推送链路打爆,是一种雪崩式的误判。这个坑很隐蔽,因为平时 Redis 好好的,根本测不出来。
更稳的姿势是把"查不到"和"确定离线"区分开。Redis 异常时不要轻易下"离线"的结论:可以退回到本机 Session 注册表做一次兜底确认(本机至少知道自己名下这批连接活着),或者短时间内对在线判定采取保守策略——宁可按"可能在线"投一次试试,也别一刀切判全员离线。在线判定这条路径上,没有降级就等于埋了一颗定时炸弹。
4.2 死连接检测的多重信号
单靠客户端心跳判活,总有够不着的角落:进程卡死还在机械回心跳、心跳通了但业务线程已塞死。判活不该只信一个信号源。可以叠加几路互相印证:客户端心跳是主信号,服务端对长时间无业务数据的连接做反向探测是补充,下行投递失败(写连接报错)是一个强信号——投不出去的连接基本可以判死。多路一起看,别把鸡蛋全押在心跳一个篮子里。
4.3 重连去重避免误杀
"清理回调误杀新连接"的竞态,是 Session 管理里最值得提前设防的一处。核心原则就一句:所有针对连接的清理 / 互踢动作,都必须带上连接的唯一标识做校验,绝不按 uid 一刀切。 给每条连接发一个建连时生成的唯一序号,写在线表时一起写进去;任何清理动作执行前,先比对"我手上这个序号是不是当前在册的那条",对不上就放过。这几行校验逻辑很便宜,但它挡住的是"用户刚连上又被踢、反复掉线"这类最难复现、最招投诉的问题。重连频繁的弱网用户,最吃这个补丁。
4.4 状态漂移的兜底对账
无论判死和清理做得多细,在线表和真实连接的漂移都不可能归零(接入机宕机来不及清表、各种竞态窗口)。与其追求"永不漂移",不如承认它、定期把它对平。一条低成本的兜底是定期对账:每台接入机周期性地把本机当前真实持有的连接列表,与在线表里登记在自己名下的记录比对,清掉"表里说在我这、实际我没有"的孤儿记录。这就像盘库存——不指望实时账账相符,但定期盘一次,把误差控制在可接受范围。
在线表从来不是真理,它只是一份"大概率正确"的索引——我们承认它会脏、并为脏准备好兜底。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号