别再让AI自由发挥了 OODER用元模板、领域骨架、SPI插件规范LLM代码生成的工程实践
原创
别再让AI自由发挥了 OODER用元模板、领域骨架、SPI插件规范LLM代码生成的工程实践
原创
OneCode
发布于 2026-05-29 12:51:09
发布于 2026-05-29 12:51:09
大模型代码生成的本质并非智能创作,而是结构化模板的概率续写与规约对齐。受限于自回归生成机制与训练数据统计特性,LLM自由生成代码普遍存在架构无序、领域边界弥散、扩展范式混乱、格式风格不统一等固有缺陷,这也是传统低代码、AI代码生成工具难以落地企业级场景的核心症结。现有研究多聚焦于模型侧后训练算法优化,仅从损失函数、偏好对齐、强化学习角度提升代码正确率,却普遍忽略模型生成特性与工程架构范式的底层冲突,存在"算法优化到位、工程落地依旧失效"的研究缺口。
OODER框架作为AI原生全栈代码生成架构,跳出传统"模型微调即全部"的单一研究视角,基于LLM代码后训练、偏好对齐、结构化生成的经典学术原理,创新性构建了动态元驱动+聚合根固化+SPI插件扩展的三层架构约束体系。本文核心学术创新在于:反向定义"工程架构适配模型生成特性"的AI原生设计范式,通过标准化元模板规约、固化领域生成骨架、统一扩展插件范式,将LLM无约束的概率化自由生成,转化为可控、规范、可迭代的结构化模板填充,从架构层面填补了LLM代码生成"算法对齐充分、架构约束缺失"的学术空白,解决大模型代码生成的幻觉、结构错乱、扩展失控等核心工程难题。
一范式重构:传统软件架构与LLM代码生成架构的核心冲突
传统软件架构设计服务于人类程序员的工程思维,核心追求高内聚低耦合、模块复用、可维护性与高可用性,依赖人工全局规划、分层设计、逻辑拆解,具备完整的架构预判与全局统筹能力。而LLM代码生成遵循统计概率与模板匹配思维,无全局架构规划能力,仅能基于上下文与训练习得范式逐词续写,二者底层逻辑完全相悖。
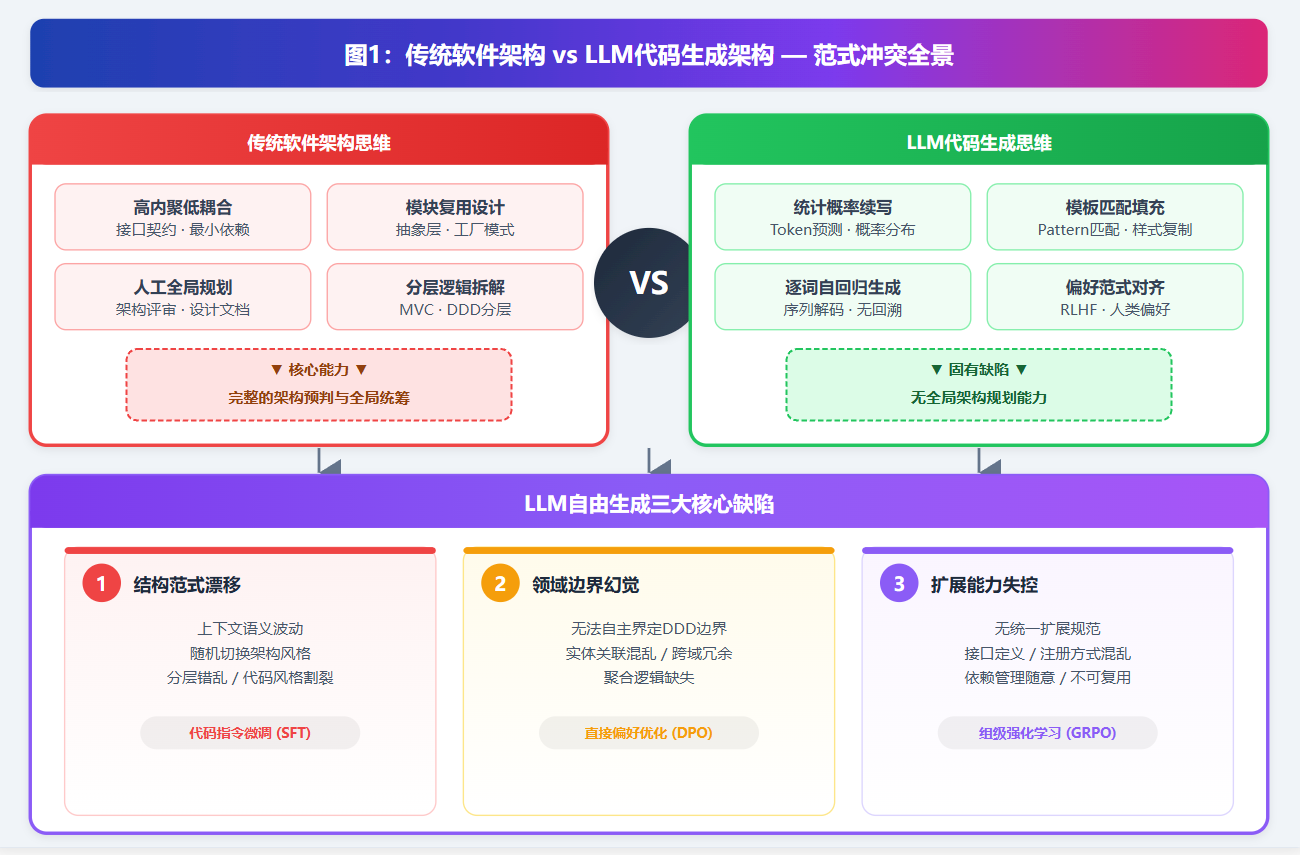
图1:传统软件架构 vs LLM代码生成架构 — 范式冲突全景
结合LLM代码后训练核心技术(代码指令微调、偏好对齐、组级强化学习)的理论结论,自由生成模式的核心缺陷可归纳为三点:
- 结构范式漂移:LLM后训练习得海量代码范式,无强制约束时,会随上下文语义波动随机切换架构风格,导致分层错乱、类结构不统一、代码风格割裂;
- 领域边界幻觉:大模型无法自主界定DDD领域边界,长序列生成中易出现实体关联混乱、跨域冗余代码、聚合逻辑缺失等问题,破坏业务代码整体性;
- 扩展能力失控:自由生成的扩展代码无统一规范,接口定义、注册方式、依赖管理随意性强,无法形成可复用、可迭代的插件体系,丧失工程落地价值。
OODER框架的核心创新逻辑
不依赖模型的"智能理解与算法进化",开创性用工程架构约束模型的"概率生成行为",通过三层层级化模板约束体系,适配LLM模板匹配、逐词续写、偏好固定范式的原生特性,实现了从"模型单向优化"到"模型-架构双向适配"的范式升级。
二动态元驱动:适配LLM生成的底层结构化模板基座
2.1 技术选型核心本质
传统框架的配置驱动、注解驱动,核心目的是简化开发、解耦代码;而OODER动态元驱动体系的选型,核心是为LLM构建一套机器可解析、模型可对齐、全栈可映射的结构化Prompt模板体系。依据代码指令微调的核心结论:LLM无法深度理解业务抽象语义,但对结构化、标准化、规则化的模板具备极强的匹配与填充能力。
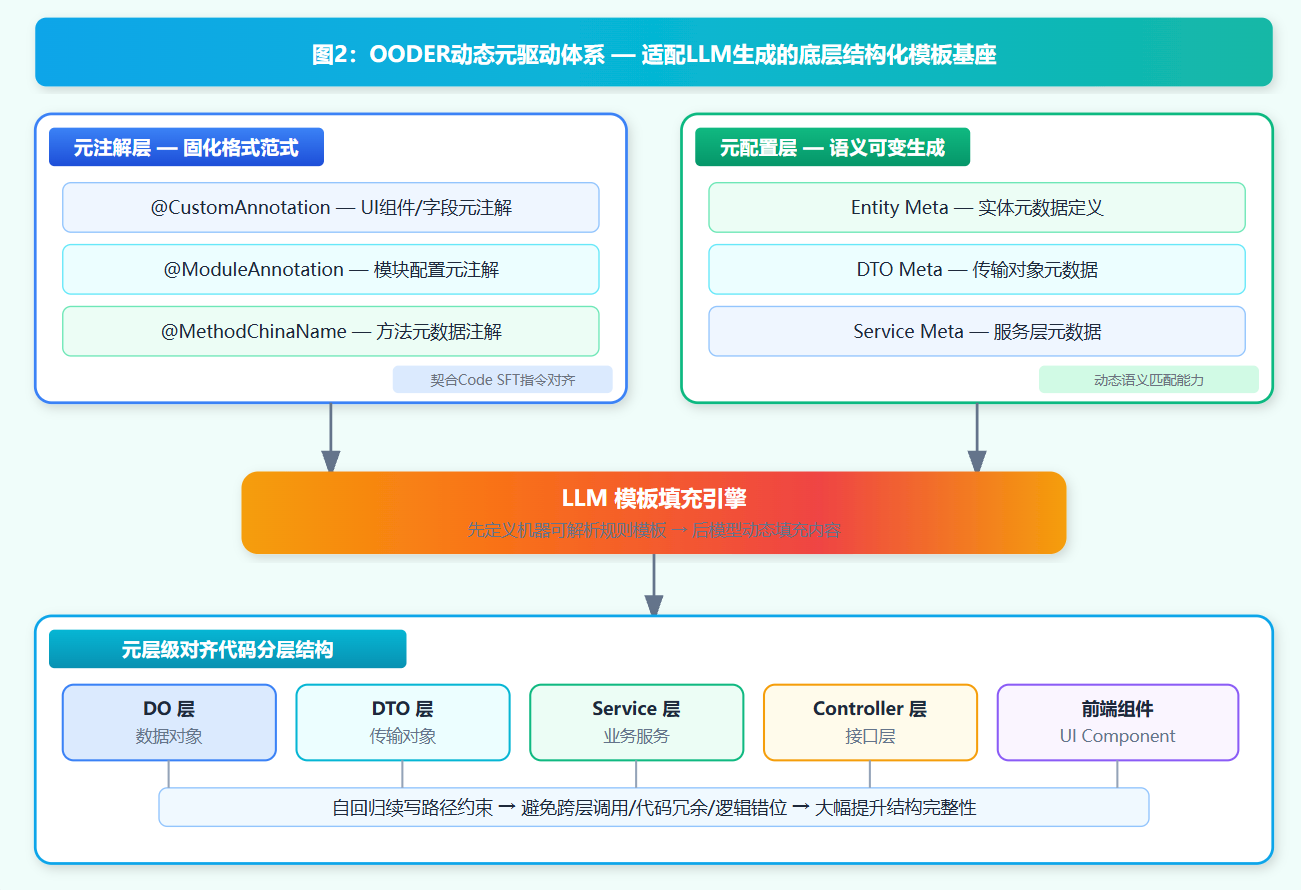
图2:OODER动态元驱动体系 — 适配LLM生成的底层结构化模板基座
2.2 适配LLM后训练特性的核心设计
元注解固化格式范式,消解生成随机性
OODER通过标准化元注解,统一DO、DTO、Service、Controller、前端组件的定义规范与分层边界。契合Code SFT指令对齐训练的核心特性,LLM天生遵循"优先匹配格式概率、再填充业务逻辑"的生成规则。
元注解定义示例 — CustomAnnotation.java
@Target({ElementType.FIELD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface CustomAnnotation {
String caption() default "";
String description() default "";
boolean required() default false;
String defaultValue() default "";
FieldType fieldType() default FieldType.TEXT;
}LLM基于元注解模板生成的实体代码
public class DepartmentManagement {
@CustomAnnotation(caption="部门名称")
@TreeGridColItemAnnotation(width="8.0em")
private String departmentName;
@CustomAnnotation(caption="部门编码")
@TreeGridColItemAnnotation(width="8.0em")
private String departmentCode;
@CustomAnnotation(caption="负责人")
@TreeGridColItemAnnotation(width="8.0em")
private String responsiblePerson;
@CustomAnnotation(caption="联系电话")
@TreeGridColItemAnnotation(width="8.0em", flexSize=true)
private String contactPhone;
}动态元数据适配语义可变生成
区别于静态固定模板,动态元驱动支持字段、规则、场景的动态调整,完美适配LLM的动态语义匹配能力。同一套底层元模板,可根据用户自然语言指令,动态填充不同业务参数、校验规则、逻辑代码,实现"一模板适配多场景"的灵活生成能力。
2.3 选型对比:元驱动完胜硬编码的AI原生逻辑
对比维度 | 传统硬编码/低代码模板 | OODER动态元驱动 |
|---|---|---|
设计目标 | 简化人工开发 | 适配LLM概率生成 |
模板特性 | 静态僵化,复用性差 | 动态可变,语义适配 |
LLM生成方式 | 自由仿写,范式混乱 | 规则约束下精准填充 |
生成质量依赖 | 完全依赖模型泛化能力 | 模板规约+模型能力双保障 |
格式一致性 | 无法保证 | 元注解强制约束 |
三聚合根架构:LLM领域代码生成的标准化骨架模板
3.1 选型核心逻辑
传统DDD中,聚合根用于界定领域边界、保障数据一致性;而在OODER+LLM的AI原生架构中,聚合根的核心价值是固化领域代码的最小生成单元与全局骨架模板。LLM的核心短板是无全局架构规划能力,长序列生成极易出现领域边界模糊、实体关联紊乱、聚合逻辑缺失等问题,而聚合根就是为弥补这一模型缺陷设计的中层架构约束。
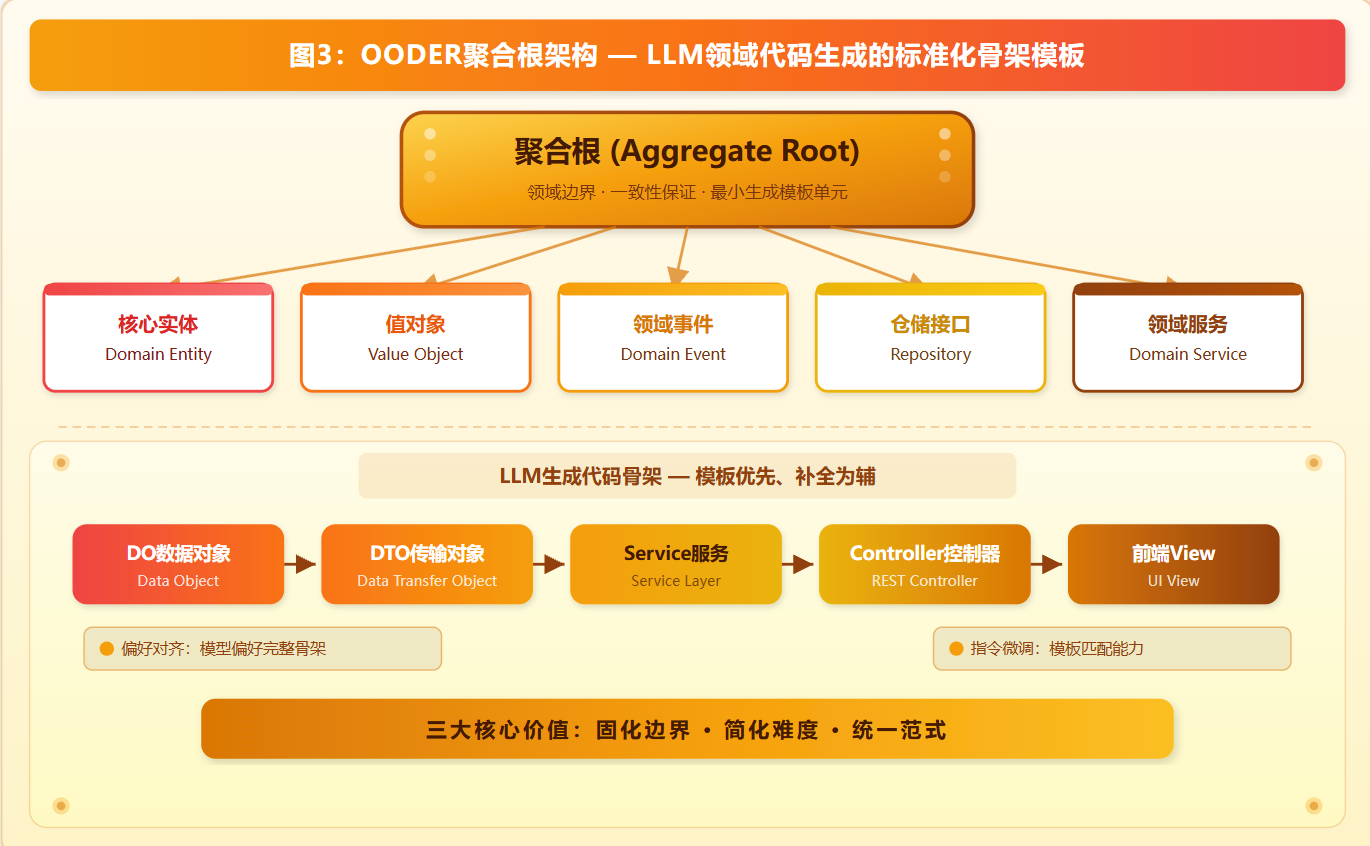
图3:OODER聚合根架构 — LLM领域代码生成的标准化骨架模板
3.2 适配LLM生成的隐性架构价值
- 固化领域边界,约束生成范围:聚合根统一界定核心实体、关联实体、领域行为的边界范围,强制LLM仅在当前领域模板内生成代码,杜绝跨领域冗余代码与逻辑漂移。
- 简化生成难度,降低幻觉概率:聚合根预设实体结构、仓储接口、领域服务、查询能力的完整骨架,LLM无需从零搭建领域架构,仅需专注填充业务字段与核心逻辑。契合直接偏好优化训练中"模型偏好完整规范骨架、排斥碎片化无序代码"的对齐逻辑。
- 统一领域范式,适配增量迭代生成:固定聚合根骨架保证每一轮生成都对齐原有领域范式,避免迭代过程中结构变形、风格割裂。
聚合根基类 — AbstractAggregateRoot.java
public abstract class AbstractAggregateRoot<ID> {
protected ID id;
protected List<DomainEvent> domainEvents = new ArrayList<>();
protected int version;
protected AbstractAggregateRoot() {
this.id = generateId();
}
protected abstract ID generateId();
public ID getId() { return id; }
public void addDomainEvent(DomainEvent event) {
domainEvents.add(event);
}
public interface Repository<T extends AbstractAggregateRoot<ID>> {
T findById(ID id);
List<T> findAll();
void save(T aggregate);
void delete(T aggregate);
}
}LLM生成的领域聚合根 — DepartmentAggregate.java
public class DepartmentAggregate extends AbstractAggregateRoot<String> {
private Department department;
private DepartmentCode departmentCode;
private String parentId;
private int sortOrder;
@Override
protected String generateId() {
return UUID.randomUUID().toString().replace("-", "");
}
public static DepartmentAggregate create(String name, String code, String parentId) {
DepartmentAggregate aggregate = new DepartmentAggregate();
aggregate.department = new Department(name);
aggregate.departmentCode = new DepartmentCode(code);
aggregate.parentId = parentId;
aggregate.addDomainEvent(new DepartmentCreatedEvent(aggregate.getId(), name));
return aggregate;
}
public void rename(String newName) {
this.department.setName(newName);
}
}3.3 LLM后训练视角的选型结论
OODER聚合根架构首次将DDD聚合根领域边界理论与LLM自回归生成特性深度耦合,把传统用于数据一致性的聚合根,重构为领域代码生成的范式收敛骨架。通过架构强制约束收敛模型多样化生成路径,解决了"模型习得范式多、落地收敛难"的行业学术痛点,弥补了DDD与AI代码生成结合的理论落地缺口。
四SPI扩展体系:LLM插件化增量生成的统一扩展模板
4.1 选型核心本质
传统框架选用SPI仅用于工程解耦与热插拔,现有AI代码生成研究也未针对增量续写场景设计专属扩展范式。结合代码强化学习核心原理可知:LLM在增量生成、局部改写场景中,稀疏奖励极易导致扩展代码范式失控、接口错乱。OODER创新性重构SPI体系的学术定位,将传统工程解耦组件,升级为LLM插件化增量生成的标准化对齐模板。
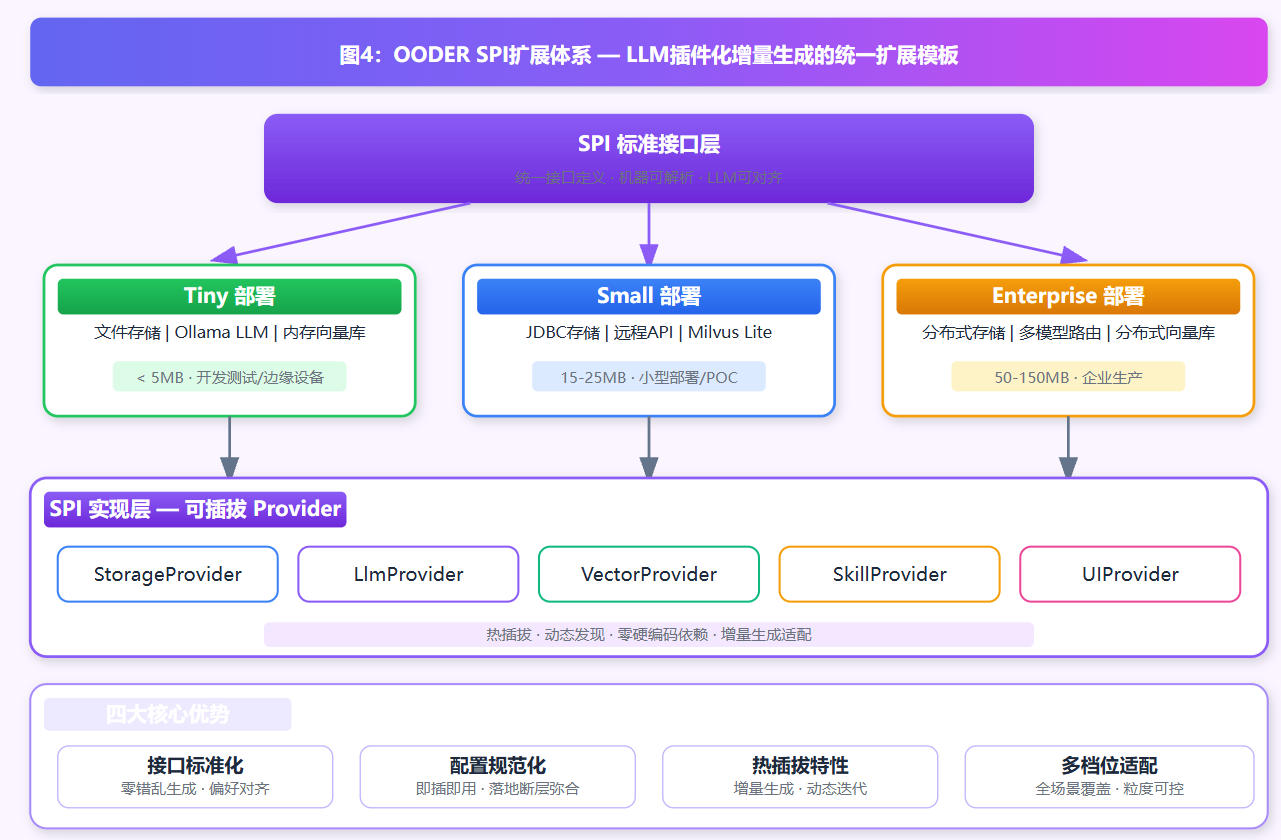
图4:OODER SPI扩展体系 — LLM插件化增量生成的统一扩展模板
4.2 SPI体系适配LLM生成的核心优势
SPI接口定义 — LlmProvider.java
public interface LlmProvider {
String getProviderName();
Map<String, Object> chat(String model,
List<Map<String, Object>> messages,
Map<String, Object> options);
List<String> getSupportedModels();
boolean isAvailable();
}
public interface EnhancedLlmProvider extends LlmProvider {
Map<String, Object> chatWithFunctions(String model,
List<Map<String, Object>> messages,
List<FunctionCall> functions,
Map<String, Object> options);
Map<String, Object> chatMultimodal(String model,
List<Map<String, Object>> messages,
Map<String, Object> options);
boolean supportsFunctionCalling(String model);
}SPI配置文件 — META-INF/services/net.ooder.scene.skill.llm.LlmProvider
# DeepSeek LLM Provider
net.ooder.scene.skill.llm.impl.DeepSeekLlmProvider
# Ollama 本地 LLM Provider
net.ooder.scene.skill.llm.impl.OllamaLlmProvider
# OpenAI 兼容 Provider
net.ooder.scene.skill.llm.impl.OpenAICompatibleProvider4.3 三档部署适配
部署档位 | 存储 | LLM | 向量库 | 包大小 | 适用场景 |
|---|---|---|---|---|---|
Tiny | 文件 | Ollama | 内存 | < 5 MB | 开发测试/边缘设备 |
Small | JDBC | 远程 API | Milvus Lite | 15-25 MB | 小型部署/POC |
Enterprise | 分布式 | 多模型路由 | 分布式向量库 | 50-150 MB | 企业生产 |
4.4 对比传统扩展模式
对比维度 | Spring自动装配/工厂类 | OODER SPI体系 |
|---|---|---|
规范性 | 灵活但无固定范式 | 强规范、模板化、机器可解析 |
LLM生成一致性 | 写法混乱,风格不一 | 自动匹配训练模板 |
热插拔能力 | 需修改代码或配置 | 原生支持动态加载 |
部署灵活性 | 通常全量部署 | Tiny/Small/Enterprise三档 |
五架构协同:三层模板体系对LLM生成的全链路可控约束
OODER动态元驱动、聚合根、SPI体系并非独立模块,而是一套深度适配LLM预训练与后训练特性的层级化约束架构,完全贴合代码指令微调、偏好对齐、组级强化学习的核心技术逻辑,形成从底层规则、中层结构到上层扩展的全链路标准化闭环。

图5:OODER三层模板约束体系 — 全链路AI代码生成闭环
- 底层:动态元驱动(规则模板):定义全栈代码的语法、分层、注解、参数通用规则,约束LLM基础生成格式,解决代码不规范、风格混乱的基础问题;
- 中层:聚合根(领域模板):固化业务领域的代码骨架与边界逻辑,约束LLM领域生成行为,解决结构混乱、领域边界模糊、长序列幻觉问题;
- 上层:SPI体系(扩展模板):标准化插件增量扩展范式,约束LLM自定义生成、迭代续写行为,解决扩展失控、无法复用、难以迭代的工程问题。
核心学术创新价值
突破现有研究"仅优化模型、不约束输出"的单一思维,构建了模型后训练对齐 + 工程架构层级约束的双向适配理论,将LLM原生的无状态、概率化、自由式生成,强制转化为有模板、有规约、有边界、可收敛的结构化填充。该体系首次完整打通了"元规则约束-领域骨架收敛-扩展范式统一"的全链路AI代码生成闭环。
六总结:AI原生视角下的技术选型核心逻辑
相较于当前学界主流的模型微调、损失函数优化、偏好对齐等研究,OODER框架跳出模型层优化的固有范式,形成了架构层适配模型的原创性学术贡献,核心创新逻辑可归纳为三点:
架构组件 | 选型本质 | 解决的LLM生成问题 |
|---|---|---|
动态元驱动 | 为LLM代码生成搭建全栈标准化规则模板体系 | 格式不统一、注解缺失、分层错乱 |
聚合根架构 | 为领域代码生成提供统一骨架模板与边界约束 | 领域边界模糊、结构混乱、逻辑漂移 |
SPI扩展体系 | 为增量插件化生成提供通用扩展模板范式 | 扩展失控、接口混乱、配置缺失 |
整体而言,OODER框架的架构设计,本质是开创了"工程架构适配模型特性"的AI原生设计新范式,区别于传统单一的模型算法优化研究,从架构层面补齐了LLM代码生成工程落地的理论短板,完美承接并延伸了主流代码大模型后训练的学术成果,有效解决了LLM代码生成"能用但不规范、能生成但难落地"的行业痛点。该研究为AI全栈代码生成的企业级工程化落地,提供了全新的理论支撑、架构范式与实践路径,具备显著的学术创新价值与工程应用价值。
OODER Framework — AI原生全栈代码生成框架
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号