最近火热的OpenHuman开源项目-我23年第二大脑文章的工程化实现

最近火热的OpenHuman开源项目-我23年第二大脑文章的工程化实现

人月聊IT
发布于 2026-05-19 18:45:19
发布于 2026-05-19 18:45:19
大家好,我是人月聊IT。最近OpenHuman这个开源项目很火,看了下项目介绍后整体感觉和我23年7月文章提出的第二大脑的思想相当类似。因此做下对比分析。
23年7月文章重新进行了下归纳整理
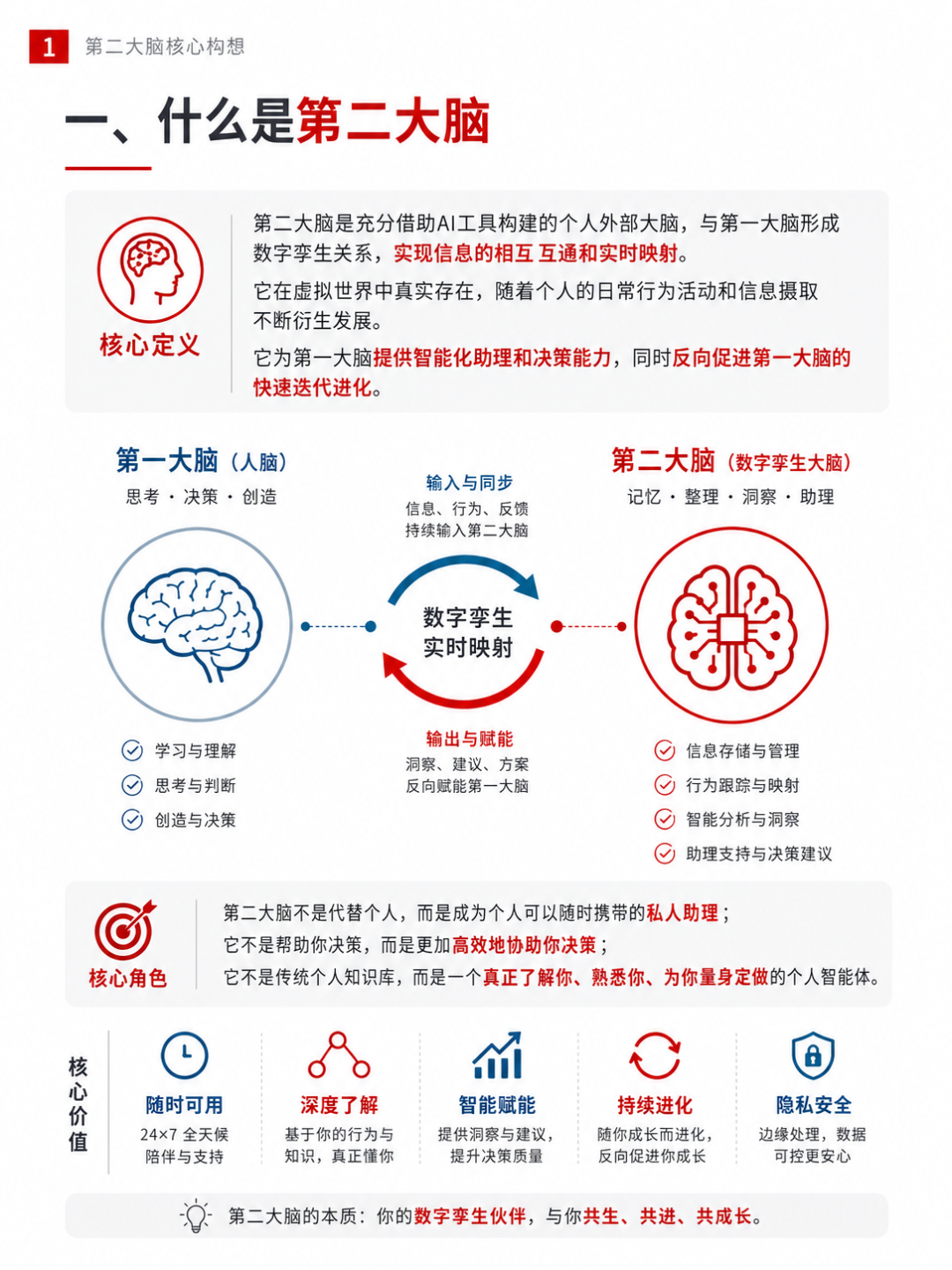
一、什么是第二大脑
在AI和人工智能快速发展的今天,我一直在思考如何通过AI来构建自己的“第二大脑”,或者叫做数字孪生大脑。
第二大脑不是代替个人,而是成为个人可以随时携带的私人助理;它不是帮助你决策,而是更加高效地协助你决策;它不是传统借助IT工具和互联网搭建的个人知识库,而是一个真正了解你、熟悉你、为你量身定做的个人智能体。
我给出的定义是:第二大脑是充分借助AI工具构建的个人外部大脑,与第一大脑形成数字孪生关系,实现信息的相互互通和实时映射。 它是一个在虚拟世界中真实存在的、随着个人日常行为活动和信息摄取不断衍生发展的大脑。它随着第一大脑不断迭代进化,为第一大脑提供智能化助理和决策能力,同时反向促进第一大脑的快速迭代进化。
二、人脑的局限与传统知识管理的不足
2.1 人脑的天生缺陷
个人大脑的核心能力是思维能力,本质是学习能力和解决问题的能力。学习能力完成外界知识的加工和存储,解决问题的能力则是调取已有知识库进行匹配和输出。但人脑存在两个明显缺陷:
- 记忆力有限:存在遗忘曲线规律,多年实践过的有用经验和方法论由于长期不用会被遗忘。
- 复盘精力不足:思维能力的提升依赖“学习-实践-复盘”的持续迭代,但个人精力很难做到每件事都认真复盘,更难在长周期内对多件类似事情进行归纳抽象。
2.2 传统知识管理的不足
第一代个人知识管理工具主要解决知识存储问题,但没有提升思维能力和解决问题能力。它们只关注知识形成后的静态存储,而没有跟踪知识形成的动态过程。因此,工具无法真正懂你,无法了解你的行为特征和做事习惯,自然难以辅助你做出最佳决策。
传统工具采用拉式模式:只有当面对问题后,你主动去检索知识库,获取知识点,再加工整合成解决方案。而我们希望的是:如果AI足够了解你,它应该能主动推送你需要的信息。
此外,公有大模型(如GPT)依赖的是互联网公开知识库,没有结合个人私有知识库,因此生成式AI的输出并不一定匹配你的具体需求和业务场景。
三、第二大脑的核心能力与构建目标
第二大脑需要弥补个人大脑在三个方面的不足:
- 个人经验模式库的构建与盘活
- 外部海量信息和经验的实时获取
- 面对复杂应用场景的问题解构与快速匹配
它不是简单的知识存储库,而是一个真正懂你的知识应用库。我们希望第二大脑具备两个关键特征:
- 动态库:与个人大脑信息随时高度匹配
- 动态行为跟踪库:而非知识的简单存储
只有这样,第二大脑才是一个数字孪生大脑,能够持续跟随第一大脑进化,并反向促进第一大脑的进化。
四、技术架构:边缘个人AI智能网关
4.1 混合AI的理念
高通提出的“混合AI”是未来方向。AI处理必须分布在云端和终端,才能实现规模化扩展。与仅在云端处理不同,混合AI在云端和边缘终端之间分配并协调AI工作负载。这种架构带来三大好处:
- 成本:减少云端开销,充分利用边缘端能力
- 时效:快速实时响应并作出判断
- 隐私:边缘端私有数据无需上传云端
公有大模型在云端进行大规模训练,但训练完成后的模型数据量很小,可以下放到边缘端设备。
4.2 边缘个人AI智能网关

构建第二大脑的核心目标就是构建一个个人边缘AI智能网关。这个网关:
- 实时动态同步个人知识库和个人行为特征,逐步训练出适配你的AI智能分析模型
- 不是完全私有:还需要结合外围GPT的能力,补充私有知识库的不足
- 个人私有AI小模型库 + 外围GPT大模型库 = 个人第二数字孪生大脑
4.3 三大关键能力
1. 外部连接能力
AI智能网关具备与外围终端设备(手机、电脑等)的快速连接和信息实时同步能力。同步的信息包括:
- 个人文档、知识库
- QQ、微信、邮件等文字沟通信息
- 网站浏览、APP使用等操作行为数据
- 日常信息输入、对外输出和反馈
这样AI才能不断学习和进化,了解你的知识技能水平、知识缺陷和行为模式。
2. AI算法和私有模型库
基于开源私有大模型库(结合AutoGPT、Langchain等)搭建。前期需要你参与进行框架规则、流程规则的微调和训练,让模型更容易理解你的工作和实践场景。
3. AI外部开放能力接入
接入Google搜索引擎、OpenAI等互联网开放能力,形成海量外围知识库。同时接入地图、图像处理、酒店预订等外部应用提供的OpenAI能力接口。
当所有内容连接后,我们期望AI能回答最基本的问题:即使你没有记录工作日志,AI也能准确回答你每天做了哪些事情——发了哪些邮件、在微信群做了哪些沟通、形成了哪些待办、添加了哪些联系人、学习了哪些文档。
五、应用场景
5.1 从ifttt到智能推送
ifttt(if this then that)实现了信息的主动推送和流程自动化,但前提是你必须预设规则。而AI智能网关的目标是:不预设规则,AI基于对你行为模式和输入信息的学习,自动生成规则并完成信息推送。
5.2 具体场景
1. 工作事务提醒
- 按你习惯每周五下班前填周报,发现本周没填则提醒
- 你习惯回家前删除与某人的隐私聊天记录,若忘记则提醒
- 你在群里沟通了下周拜访客户,提前提醒
2. 个人经验总结与复盘
AI完整了解你的工作行为和输入,可以自动根据关键词帮你完成项目或事务的复盘。例如,你在多个微信群就某个项目与客户多次沟通,AI可以帮助你基于时间线对所有内容进行总结和复盘。这种能力将极大丰富你的经验模式库。
3. AI反向训练和学习
AI可以7×24小时不断训练,甚至两个AI互搏训练。类似围棋AlphaGo,现在的专业棋手反而跟着AI训练——如果下一手的下法与AI高度一致,说明水平在提升。
AI智能网关不是封闭的私有模型,它会结合互联网海量的OpenAI和搜索工具知识库,吸纳他人成功经验,在了解你的知识盲区后给出更好的学习和提升计划。你可以在AI思路下行动,AI进一步采集你的输出和反馈,以正反馈或负反馈方式持续迭代完善。
4. 复杂问题的处理和解构
单纯的外网GPT可能给出“胡说八道”的解决方案,但结合个人私有模型后,解决方案往往有效。AI网关在大量学习你的知识结构和行为特征后,面对复杂问题能有针对性地给出最佳方案。例如,面对一个新甲方标书,AI可以帮你自动整理一份匹配需求的、有针对性的技术方案。
六、结语
构建第二大脑(边缘AI智能网关)将是你个人的强大外挂。它不仅解决知识检索问题,更重要的是:真正理解你的知识和行为后,变拉式为推式,变预设规则为自动理解内容生成规则——这才是我们真正希望的第二大脑。
它将持续跟随你、了解你、辅助你,并反向促进你第一大脑的持续进化。在AI时代,这不再是一个遥远的构想,而是可以逐步实现的未来。
开源项目OpenHuman简单总结
OpenHuman 是什么?
一句话总结: OpenHuman 是一个开源的"个人 AI 超级智能"桌面助手,目标是让 AI agent 真正融入你的日常工作流——它不只是聊天机器人,而是能主动感知你的数据、记住你的习惯、替你干活的本地 AI 管家。
核心功能解析
🧠 记忆系统(Memory Tree + Obsidian Wiki)
所有接入的数据(邮件、文档、聊天记录等)会被压缩成不超过 3000 token 的 Markdown 片段,存入本机 SQLite 数据库,同时以 .md 文件形式写入兼容 Obsidian 的本地知识库,灵感来自 Andrej Karpathy 分享的工作流。你的知识图谱完全在本地,不上云。
🔗 118+ 第三方集成 + 自动同步
支持一键 OAuth 接入 Gmail、Notion、GitHub、Slack、Stripe、Calendar、Drive、Linear、Jira 等服务,并每 20 分钟自动拉取最新数据到记忆树。也就是说,agent 早上醒来已经帮你把今天的邮件、日历、PR 都消化好了。
🎭 有"脸"的 Agent(Desktop Mascot)
agent 拥有一张脸——一个桌面虚拟形象,能说话、能感知周围环境、能以真实参与者身份加入你的 Google Meet 会议,并在你停止打字后继续在后台思考。这个设计相当有意思,把 AI 从对话框变成了一个"常驻同事"。
⚡ Token 压缩(TokenJuice)
所有工具调用、网页抓取结果、邮件正文等在进入任何大模型之前,都会经过 token 压缩层处理:HTML 转 Markdown、长 URL 缩短、移除非 ASCII 字符等,可以降低 80% 的 token 消耗,大幅压低使用成本。 github
🛠️ 开箱即用的工具集
内置网页搜索、网页抓取、完整编程工具链(文件系统、git、lint、测试、grep)以及原生语音支持(STT 输入、ElevenLabs TTS 输出、吉祥物口型同步、Google Meet 实时 agent),还支持通过 Ollama 接入本地模型。
技术栈
项目主要用 Rust(69.4%) 和 TypeScript(26.6%) 编写,Rust 负责核心性能层,TypeScript 负责 UI 和业务逻辑。这个技术选型意味着性能和内存安全都有保障。
项目现状
- ⭐ 776 Stars,105 Forks,目前处于 Early Beta 阶段
- 最新版本为 v0.53.22(2026年5月9日发布),迭代非常活跃(已有1650次提交、31个版本)GPL-3.0 开源协议
一句话点评
OpenHuman 的野心不小——它想做的不是"又一个 AI 聊天工具",而是真正有持久记忆、能主动感知上下文、有桌面形象的个人 AI 操作层。Memory Tree + 自动同步 + TokenJuice 这几个设计组合在一起,解决的是目前大多数 agent 框架"每次冷启动、没有长期记忆"的痛点。目前仍是 Beta,适合开发者和早期爱好者尝鲜。
两者对比分析说明
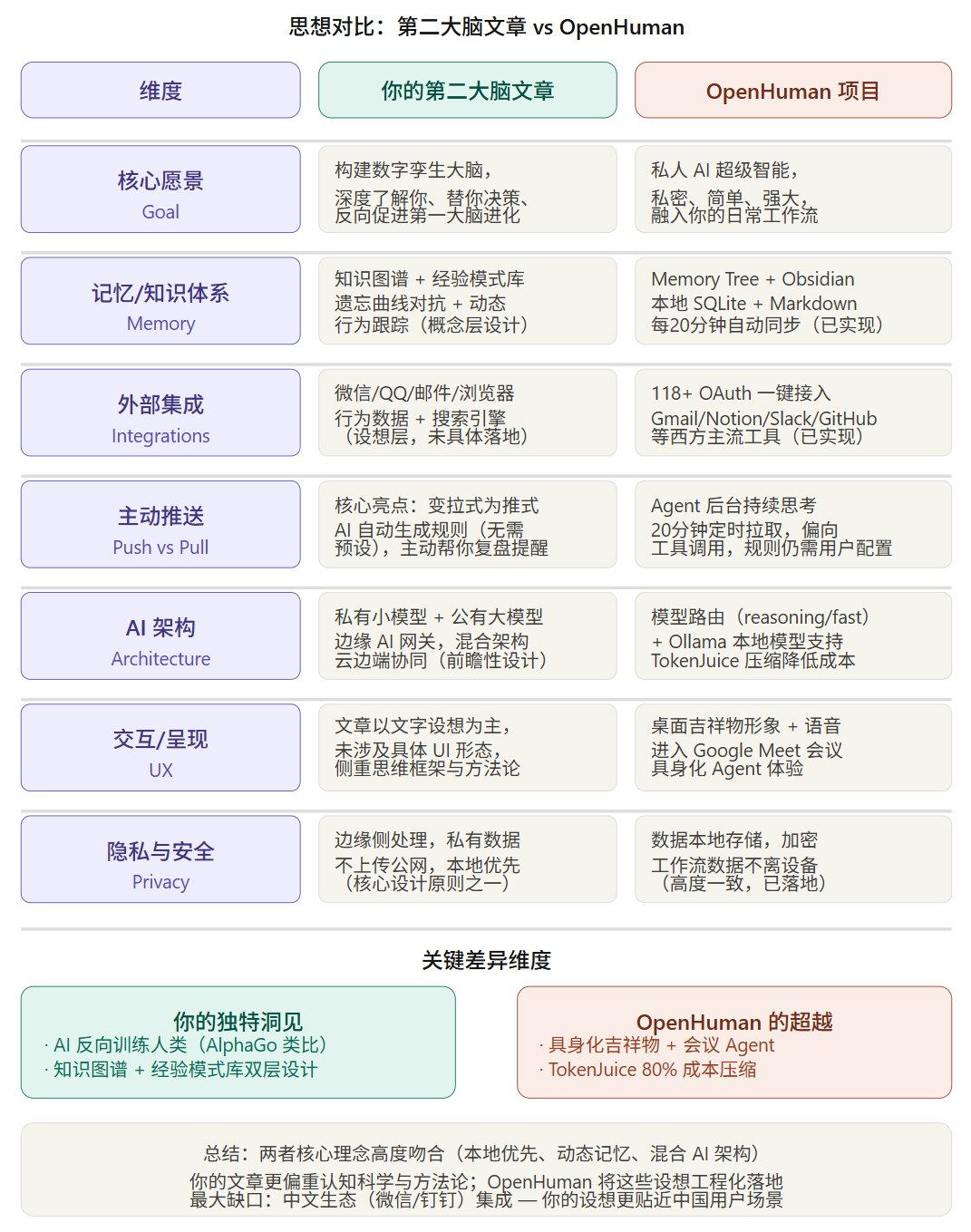
下面展开逐维度的深度分析:
一、核心理念:高度契合,但出发点不同
你的文章从认知科学视角切入——遗忘曲线、经验模式库、知识图谱——核心问题是"人脑有哪些缺陷,AI 如何弥补"。OpenHuman 则从用户体验视角切入,核心问题是"怎么让 AI agent 在五分钟内就能有用"。
两者殊途同归,都指向同一个目标:一个真正了解你、持续进化的私人 AI 智能体。
二、你最有前瞻性的观点
"变拉式为推式" 是你文章中最有价值的洞见。你写道:传统知识库是你遇到问题才去检索,而真正的第二大脑应该是 AI 在充分了解你之后,主动生成规则、主动推送。这个 push 模型理念至今仍是大多数 AI 工具的痛点——OpenHuman 的自动同步(20分钟循环)只是做到了数据层面的主动,"无需预设规则的自动理解"这一层还没完全实现。
"AI 反向训练人类" 的 AlphaGo 类比也很有意思。你设想的不只是 AI 帮你干活,而是 AI 倒过来促进你自己的认知进化——这是一个比 OpenHuman 更深层的哲学命题,OpenHuman 目前还停留在"帮你记住、帮你执行"的阶段。
三、OpenHuman 超越你文章的地方
具身化呈现是你文章完全没有触及的维度。一个有脸、会说话、能进入视频会议的 Agent,这种"常驻同事"体验是 OpenHuman 特有的创新,也是当前整个 AI Agent 领域的前沿探索。
TokenJuice 成本压缩体现了工程思维。你的文章设想了私有模型 + 公有模型混合架构来降本,OpenHuman 则用更务实的方法——压缩每次调用的 token 消耗,降低 80% 成本。两种路径,一理论一实践。
四、最大的生态差距
你的文章里提到了微信、QQ、邮件、浏览器行为,完全以中国用户的数字生活为场景出发。OpenHuman 的 118+ 集成几乎全是 Gmail、Slack、Notion、GitHub 这些西方工具,中文生态(微信/钉钉/飞书)完全缺失。
这恰恰是你的文章比 OpenHuman 更贴近中国用户的地方,也是一个真实的市场机会。
五、一句话总结
你的文章是一份有认知深度的需求规格书,OpenHuman 是把类似需求规格书工程化落地的开源实现。两者的核心判断几乎一致,但你更强调"人机共进化"的哲学层,OpenHuman 更强调"今天就能用"的体验层。
今天分享就到这里,希望对你有所启发。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号