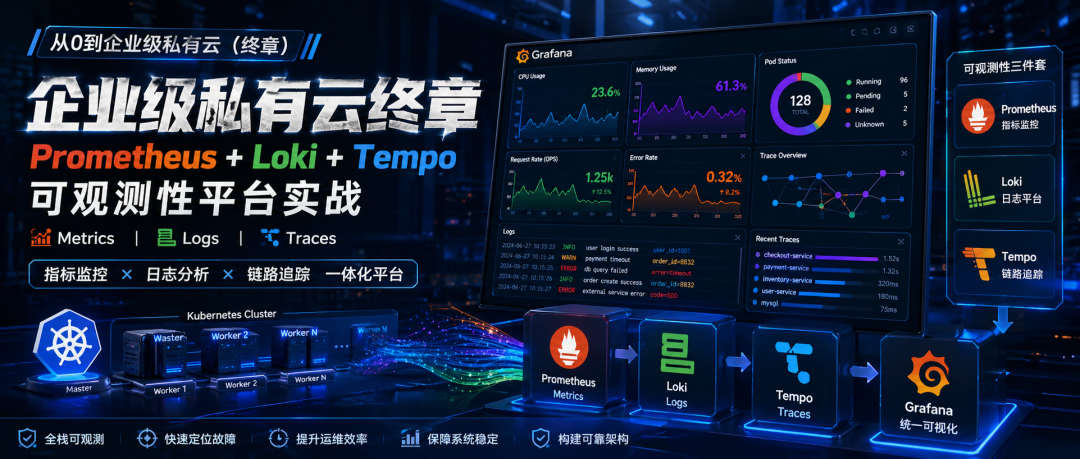
从 0 到企业级私有云 | Prometheus + Loki + Tempo 打造可观测性平台

从 0 到企业级私有云 | Prometheus + Loki + Tempo 打造可观测性平台

一根头发丝的宽度
发布于 2026-05-06 20:58:45
发布于 2026-05-06 20:58:45
在前几篇文章中,我们已经完整实践了企业级私有云的核心链路:
- Kubernetes 集群部署
- Harbor 私有镜像仓库
- Jenkins 持续集成(CI)
- ArgoCD GitOps 持续交付(CD)
- 自动化发布流水线
至此,许多人可能认为核心链路已搭建完成。但在真实的企业环境中,这仅仅是平台建设的起点。
系统上线之后,真正决定平台稳定性的,并非部署速度,而是:
系统是否可观测
故障是否可定位
性能是否可分析
问题是否可追踪
因此,今天我们将继续完成企业级私有云的最后一块拼图:
可观测性平台(Observability)
本文将带你实战:
Prometheus —— 指标监控(Metrics)
Loki —— 日志平台(Logs)
Tempo —— 链路追踪(Traces)
Grafana —— 统一可视化(Visualization)
最终形成企业级三位一体监控体系:
Metrics + Logs + Traces
一、为什么企业一定要做可观测性?
许多初学者对监控的理解往往局限于:
CPU 使用率
内存使用率
磁盘空间
这些指标仅为基础资源监控。而在企业线上环境中,真实问题常常表现为:
场景1:接口突然变慢
CPU 使用率正常,但用户反馈页面明显卡顿。
场景2:某服务频繁报错
Pod 并未重启,但请求持续返回 500 状态码。
场景3:多个微服务相互调用失败
订单服务调用库存服务,再调用支付服务,中间某一跳发生超时。
此时,仅凭 CPU 或内存指标已无法定位根因。因此,需要:
能力 | 工具 |
|---|---|
看资源状态 | Prometheus |
看日志内容 | Loki |
看调用链路 | Tempo |
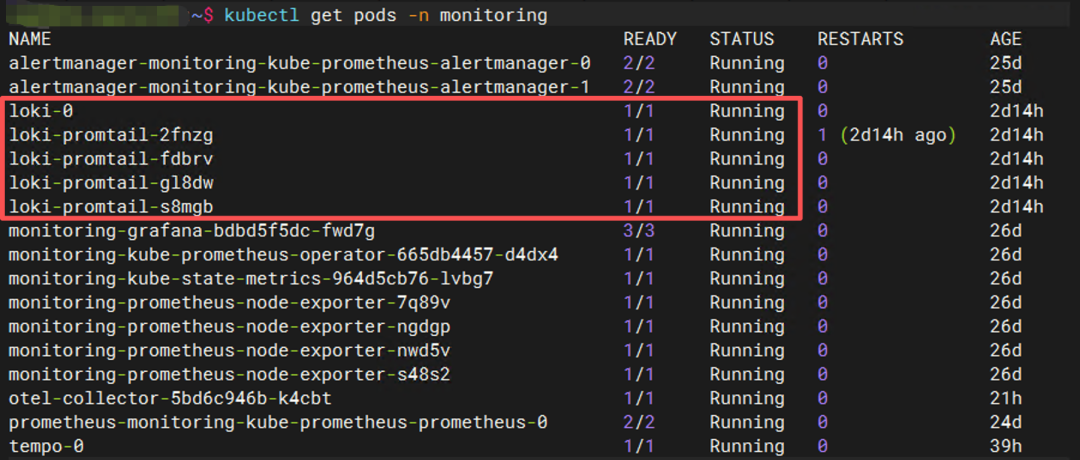
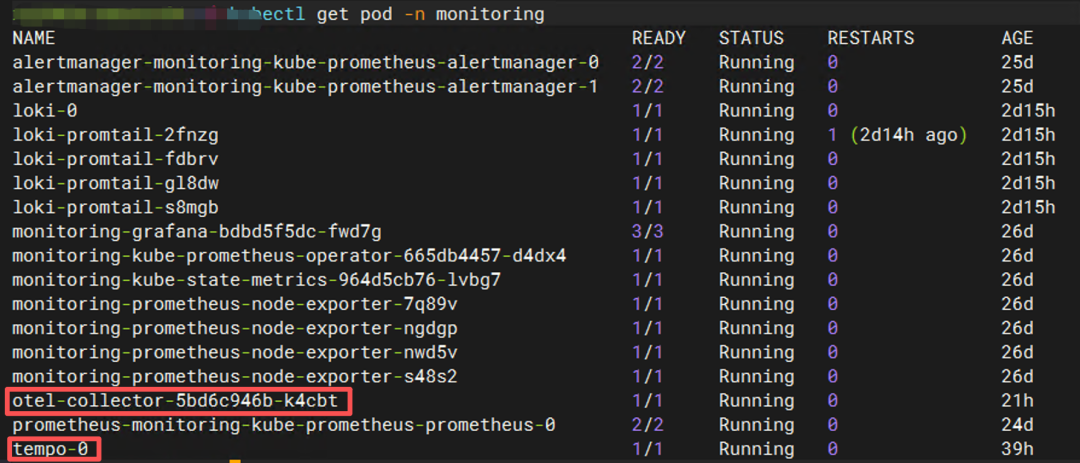
二、整体架构图
基于我们已有的 Kubernetes 集群,最终形成的可观测性架构如下:
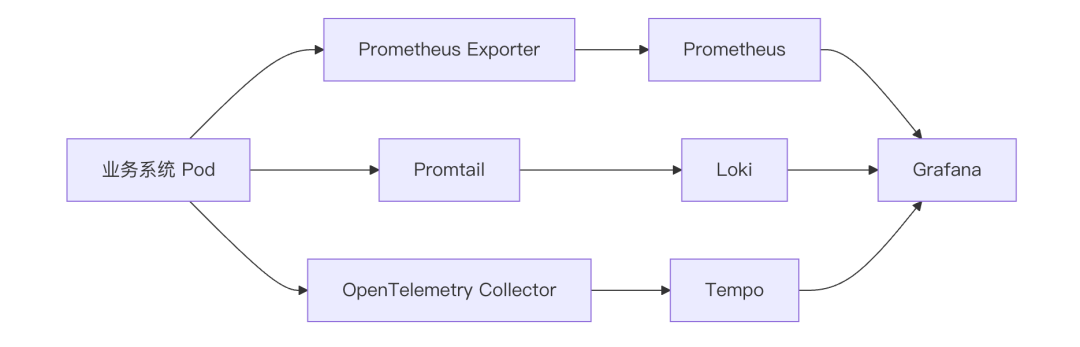
Grafana 作为统一入口,实现了一个平台同时查看指标、日志与链路。在本次实验中,所有组件均通过 Helm Chart 方式部署于之前的 K8s 集群中,彼此之间通过 Kubernetes Service 互相通信。
三、第一阶段:Prometheus 指标监控
之前已在集群中部署了:
kube-prometheus-stack
这套 Helm Chart 会一键安装以下组件:
- Prometheus
- Alertmanager
- Node Exporter(以 DaemonSet 形式运行)
- kube-state-metrics
- Grafana(与后续手动安装的 Grafana 整合或共用)
实验中我们启用了 ServiceMonitor,使其能够自动发现集群中所有暴露 /metrics端口的服务。
可监控维度
节点层:
CPU
内存
磁盘
网络流量
负载
Kubernetes 层:
Pod 状态
Deployment 副本数
重启次数
Namespace 资源占用
应用层:
接口 QPS
响应时间 P95 / P99
错误率
实际价值
当某个节点 CPU 使用率异常升高时,5 秒内便能在 Grafana 仪表盘中观测到。
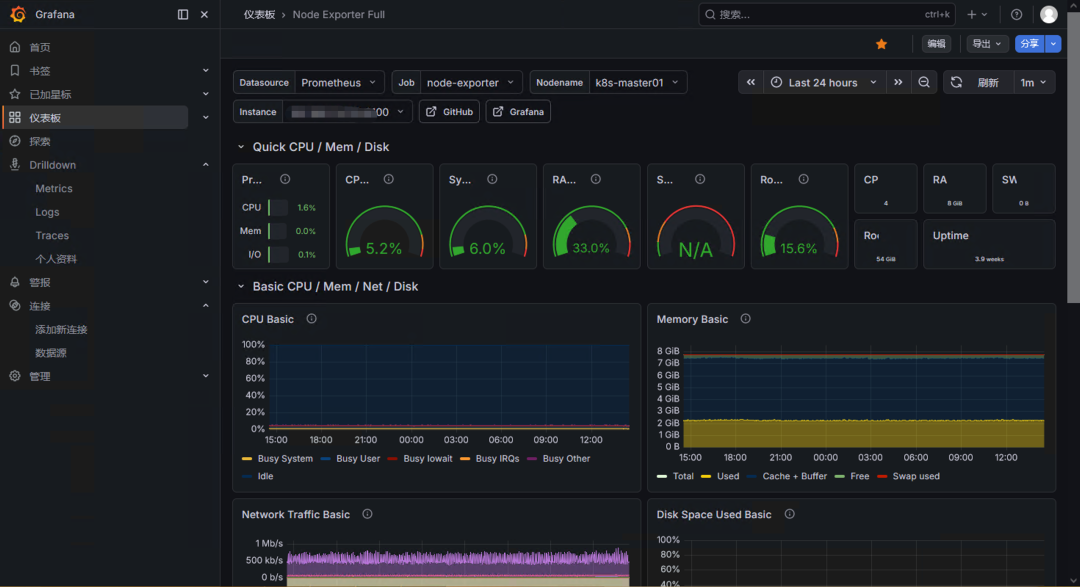
当某个 Pod 频繁发生 CrashLoopBackOff 时,Alertmanager 可第一时间发出告警。
四、第二阶段:Loki 日志平台
传统日志查看方式:
kubectl logs pod-name
其局限性十分明显:
- 仅能查看单个 Pod 的日志
- 无法进行全文检索
- 无法跨命名空间查询
- Pod 重建后历史日志丢失
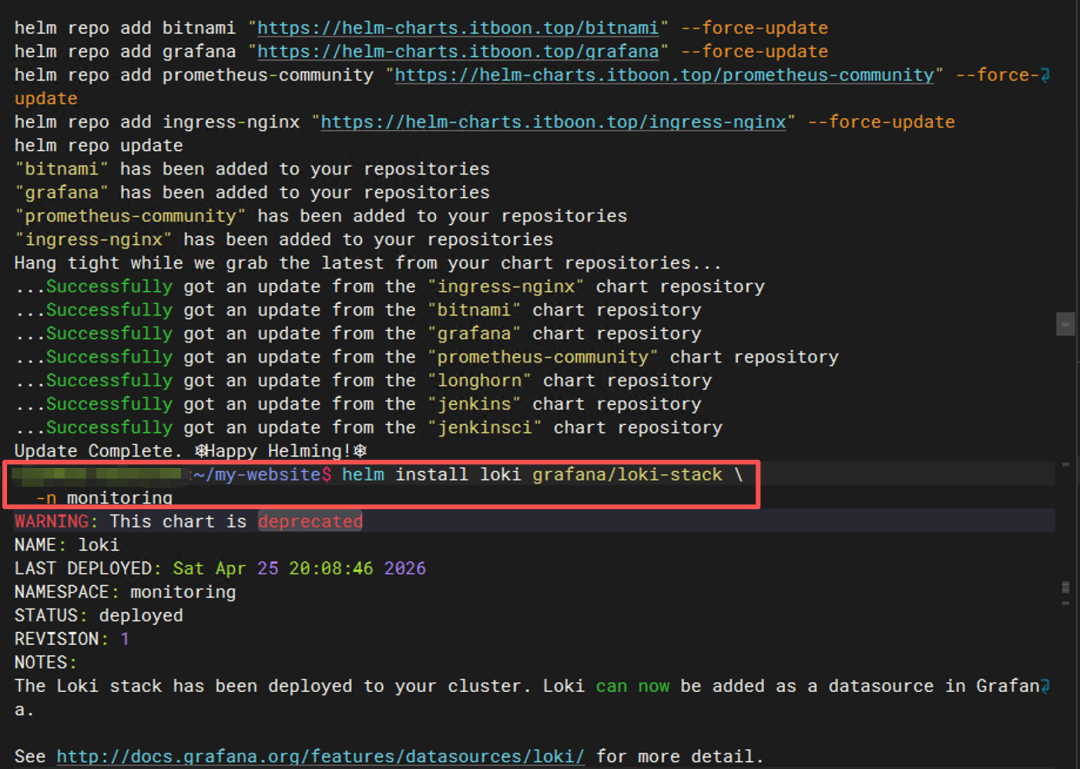
为此,我们部署了:
Loki + Promtail
核心部署命令:
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install loki grafana/loki-stack -n monitoring
Promtail 的工作机制
Promtail 以 DaemonSet 形式运行在每个节点上,自动采集:
/var/log/containers/*.log
并利用 Kubernetes API 为日志自动注入 Pod 名称、Namespace、Labels 等元数据,随后推送到 Loki。
在 Grafana 中将 Loki 添加为数据源后,即可通过 Explore 界面使用 LogQL 进行查询。
在 Grafana 中的操作
搜索关键词:
error
timeout
exception
trace_id
可秒级定位问题日志。同时,由于 Promtail 正在采集我们在前面流水线中部署的应用日志,因此从代码提交到部署后的异常日志都能够即时呈现。

企业价值对比
传统方式:
SSH 登录服务器 -> grep -> tail -f
现代方式:
打开 Grafana -> 输入关键词 -> 全集群定位
五、第三阶段:Tempo 链路追踪
这是一项许多人较少接触但在分布式系统中不可或缺的能力。我们部署了:
Tempo + OpenTelemetry Collector
部署命令:
# 如果镜像拉取失败使用 kubectl edit 修改国内的镜像地址
# Daocloud、渡渡鸟、1秒、轩辕等
helm install tempo grafana/tempo -n monitoring
helm install otel-collector open-telemetry/opentelemetry-collector \
-n monitoring
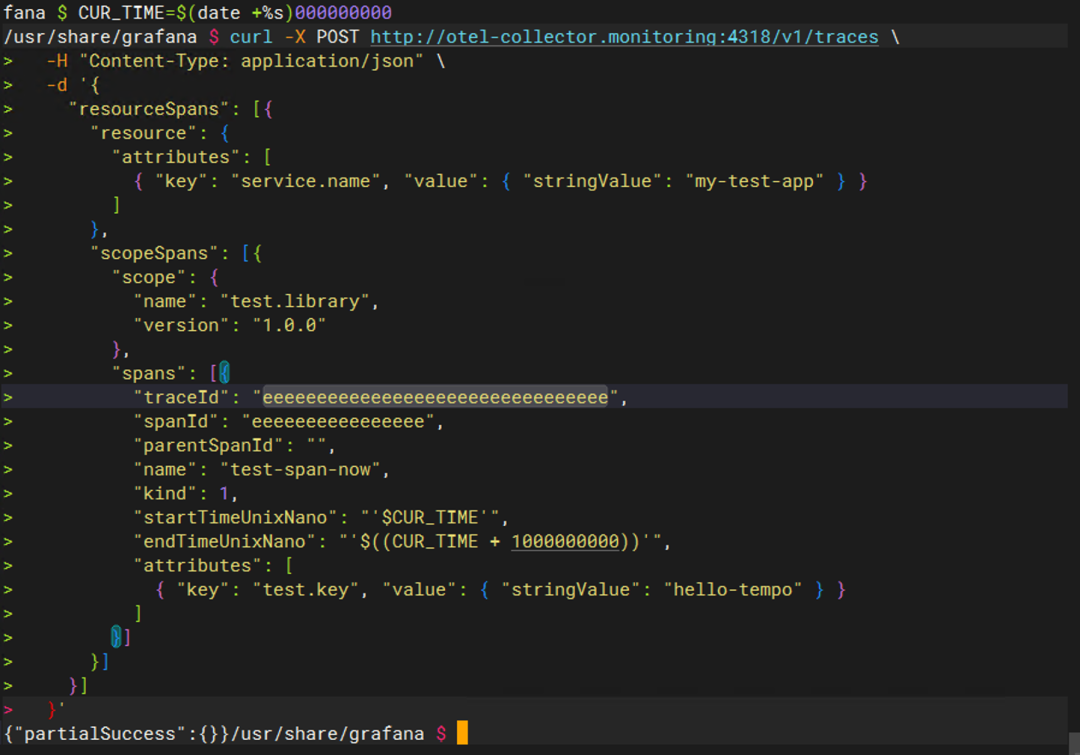
进入一个可访问 Collector 的 Pod(例如 Grafana 或任意带 curl 的 Pod),发送一条自定义 Trace 测试:
# 获取当前时间的纳秒
CUR_TIME=$(date +%s)000000000
curl -X POST http://otel-collector.monitoring:4318/v1/traces \
-H "Content-Type: application/json" \
-d '{
"resourceSpans": [{
"resource": {
"attributes": [
{ "key": "service.name", "value": { "stringValue": "my-test-app" } }
]
},
"scopeSpans": [{
"scope": {
"name": "test.library",
"version": "1.0.0"
},
"spans": [{
"traceId": "eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee",
"spanId": "eeeeeeeeeeeeeeee",
"parentSpanId": "",
"name": "test-span-now",
"kind": 1,
"startTimeUnixNano": "'$CUR_TIME'",
"endTimeUnixNano": "'$((CUR_TIME + 1000000000))'",
"attributes": [
{ "key": "test.key", "value": { "stringValue": "hello-tempo" } }
]
}]
}]
}]
}'
解决什么问题?
假设用户下单请求的调用链路如下:
Nginx
→ API Gateway
→ Order Service
→ Inventory Service
→ Payment Service
→ MySQL
用户反馈:“下单缓慢,耗时约 8 秒。”应当如何排查?
使用 Tempo 之后
在 Grafana 中可直接查看完整的调用链:
Order Service 20ms
Inventory Service 50ms
Payment Service 6.8s
MySQL Query 100ms
问题即刻定位:支付服务内部耗时 6 秒,无需猜测,直接依据 Trace 下钻分析。
六、本次实验已真实打通链路
在集群中部署了一个 OpenTelemetry Collector Deployment,配置了 OTLP 接收器,并将 Trace 数据导出到 Tempo。
为验证链路是否拉通,使用 curl模拟了一次业务请求上报:
curl -X POST http://otel-collector.monitoring:4318/v1/traces \
-H "Content-Type: application/json" \
-d '{"resourceSpans":[...]}'
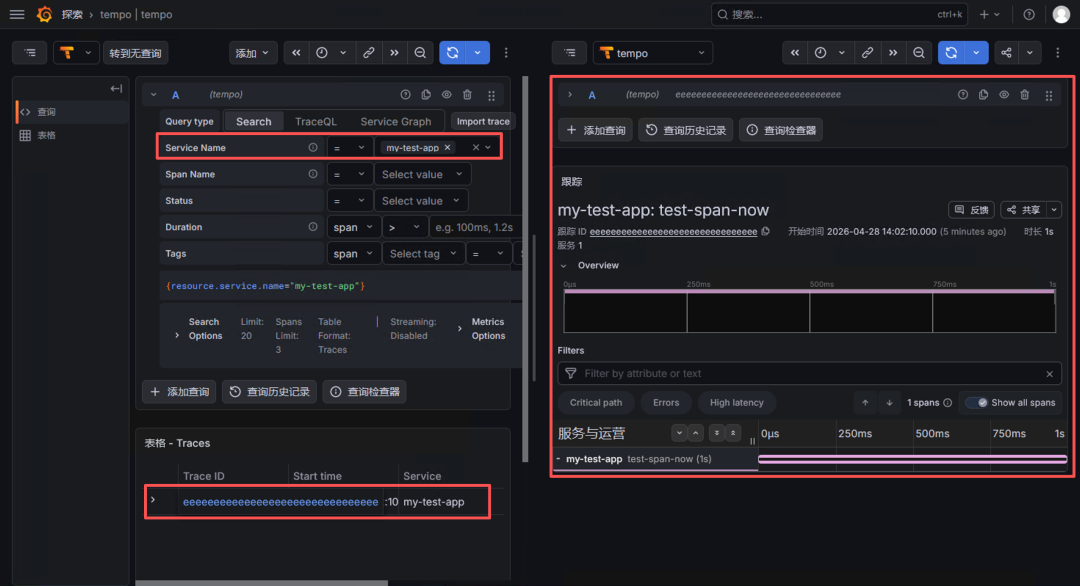
随后在 Grafana 的 Tempo 数据源中,通过 Trace ID 成功查询到这条链路:
service.name = my-test-app
span.name = test-span-now
Trace ID = eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
这验证了完整的数据通路:
业务请求 → OpenTelemetry Collector → Tempo → Grafana
如第五段测试图。
七、关于“统一可观测性”的落地难点
有的团队虽然拥有监控、日志和 APM 工具,但仍觉得问题难以排查?
实践中发现,根本原因并非缺少工具,而是工具之间缺乏有效关联:
- 监控告警提示 CPU 升高,但无法直接查看当时的错误日志;
- 日志中出现超时报错,却无法得知本次调用经过了哪些下游服务;
- APM 显示出某跳耗时较高,却又缺少对应的业务日志上下文。
最终导致:监控、日志、APM 各成孤岛,排查问题时需要在多个控制台之间反复切换,甚至需要人工对齐时间戳。
此次搭建的 Grafana 全家桶(Loki、Tempo、Prometheus),通过统一的数据源管理与面板内跳转机制,将原本孤立的三种信号真正关联了起来。
指标异常 → 查看日志 → 下钻链路,一气呵成。
这正是本次实验最核心的价值:不是简单地安装了几个组件,而是实现了企业级可观测性的关联闭环。
八、后续升级方向
基于当前成果,可以进一步完善,使其具备生产级能力:
告警体系
- Prometheus Alertmanager 规则配置
- 企业微信通知
- 钉钉通知
- 邮件通知
- 值班轮值机制
自动化发布联动
- Jenkins 发布后自动打标
- Grafana 自动记录部署事件标记
- 通过对比发布时间与监控异常,快速决定回滚
SLO / SLA 管理
- 接口可用率 ≥ 99.9%
- 响应时间 < 200ms
- 错误率 < 0.1%
九、整个系列至此,完成了什么?
从零搭建:
Linux
Docker
Kubernetes
Harbor
Jenkins
ArgoCD
Prometheus
Loki
Tempo
Grafana
这已经不再是单纯的“学习环境”,而是一套完整的企业私有云平台雏形。
十、写给还在迷茫的人
很多人常问:
学 Kubernetes 有什么用?
真正的答案不在于能背诵多少命令,而在于你能否动手构建:
交付体系
监控体系
稳定性体系
自动化体系
这才是企业真正需要的工程化能力。
结尾
当你把这些系统全部打通之后,便会体会到:
运维的价值,不是修机器。 而是构建稳定运行的平台。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号