DeepSeek V4 领衔实测:国产 AI 大模型工程代码能力大测评!
原创
DeepSeek V4 领衔实测:国产 AI 大模型工程代码能力大测评!
原创
DolphinDB
发布于 2026-05-06 11:49:05
发布于 2026-05-06 11:49:05
随着 vibe coding 相关技术日趋成熟,大模型辅助编程已经逐渐成为主流的开发方式。各大模型也在持续发力工程级代码能力,竞争愈发激烈。
在这个背景下,一个自然而然的问题出现了:对于 DolphinDB 这类深耕专业细分领域、自带编程语言的产品,大模型的辅助效果到底如何?不同模型之间的差距有多大?恰好 DeepSeek V4 系列也刚刚发布,我们也很好奇新版本的实际表现。
于是,我们跑了一轮系统性评测,覆盖当前主流的国产大模型,并引入 gpt-5.4 作为能力基准线,看看国产模型的真实水位在哪里!
测试框架
和常见的问答式评测不同,这次我们刻意把测试环境做得更接近真实开发。
模型不是简单地回答问题,而是要完成一个完整的闭环:理解任务、查文档、写代码、运行脚本、根据报错调整,再反复迭代,直到结果可以被验证。整个过程里,我们唯一坚持的原则是——不接受“看起来对”的答案。代码必须跑通,结果必须正确,否则一律不算完成。
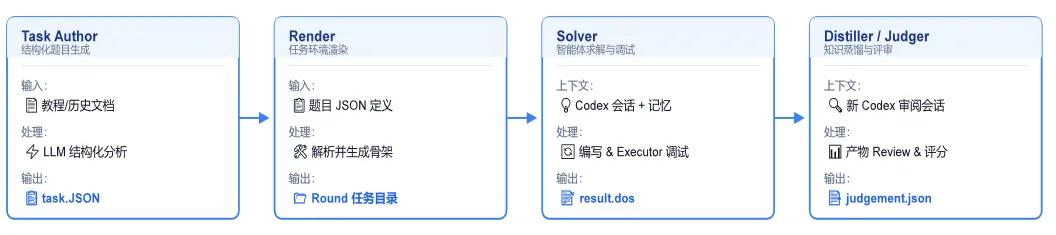
图片
测试平台分四层运作:
- 任务生成层(Task Author)读取语料、输出结构化任务描述;
- 渲染层(Render)将任务固化为稳定的目录结构;
- 解题层(Solver)驱动 Agent 完成代码编写与调试;
- 评分层(Reviewer)依据预设细则量化打分,并从解题过程中提炼改进建议。
既然要全流程评估,评分自然也不能只看结果。我们设置了八个维度进行打分:结果正确(30分)、代码风格(15分)、工具使用(15分)、文档查询(10分)、技能遵守(10分)、测试实验(10分)、调试效率(5分)、时间成本(5分)。共计满分 100 分,最终代码的正确性只占 30%,剩下 70% 考察的是"怎么做到的",因为过程质量和结果质量同样重要。
题目设计上,我们没有刻意追求难度,而是更关注真实。我们的测试题覆盖了因子计算与存储、DECIMAL 类型精度、OLTP 交易账户表、流计算引擎、分钟 K 线入库与日 K 聚合计算等贴近日常开发的实操场景,尽量还原真实使用中会遇到的问题类型。
结果分析
在剔除了网络中断、权限异常等外部干扰之后,我们最终保留了 94 轮有效样本。从结果上看,一个比较清晰的结论是:国产模型的分层已经非常明显,而且这种分层不只是体现在分数高低,更体现在稳定性和工程可用性上。
我们从平均得分、得分标准差、得分 CV、优秀率、耗时、Token 开销、平均运行次数这几个层面进行对比。对比结果如下:
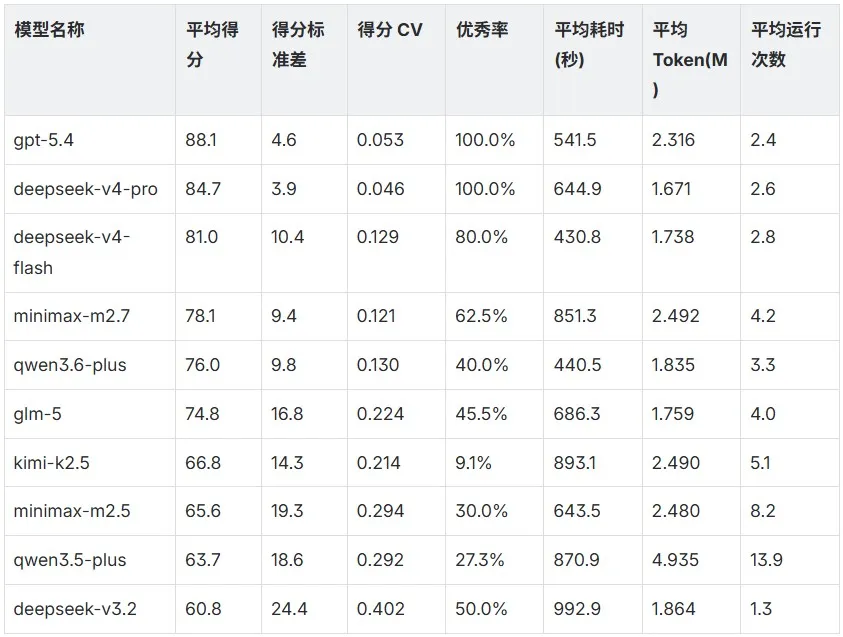
图片
注:CV= 标准差/均值,用于衡量稳定性,数值越低越稳定。优秀率=总分 >80 分的比例。
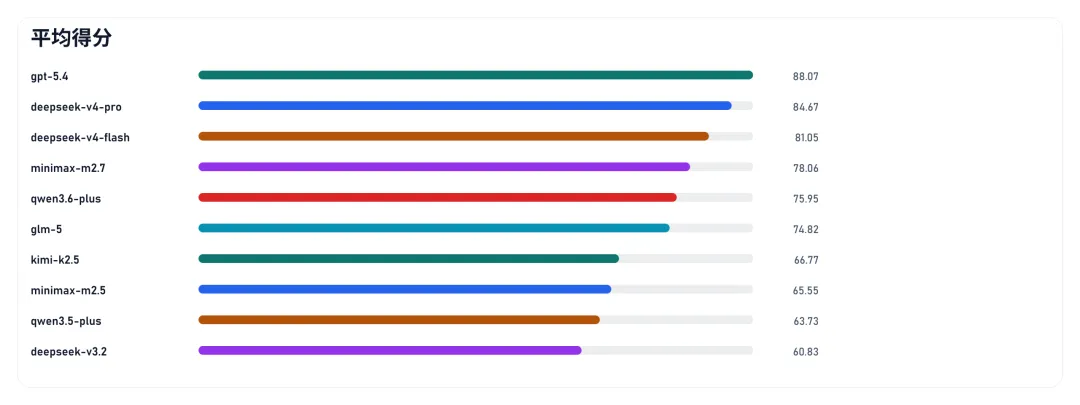
图片
整体来看,在这个实验项目中,各模型的表现结果能够呈现出明显差距。第一梯队是 deepseek-v4-pro、deepseek-v4-flash 和 minimax-m2.7。其中,deepseek-v4-pro 上限最高、稳定性最强,是实验项目中国产模型综合表现最均衡的一个;deepseek-v4-flash 效率最突出,速度和 Token 消耗都控制得很好;minimax-m2.7 则是非 DeepSeek-V4 系里表现最稳定的一个。
其后是 qwen3.6-plus 和 glm-5。其中,qwen3.6-plus 的效率表现不错,耗时和 Token 消耗都在合理范围内,但优秀率偏低,上限和头部三组还有差距;glm-5 的优势在于 Token 成本控制,整体表现比较均衡,没有特别突出的短板,也没有特别亮眼的地方。
为了给工程选型提供更具操作性的参考,我们进一步将评分项,按照代码能力、纪律性、执行效率三个层面作进一步划分,各模型的均值如下:
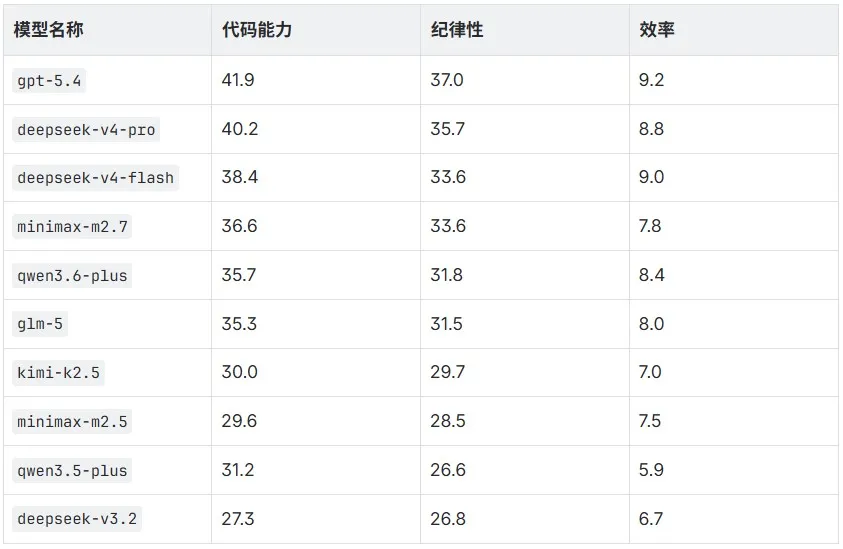
图片
代码能力
代码能力由计算结果与代码风格两项构成,考察的是模型能不能把事情做对。
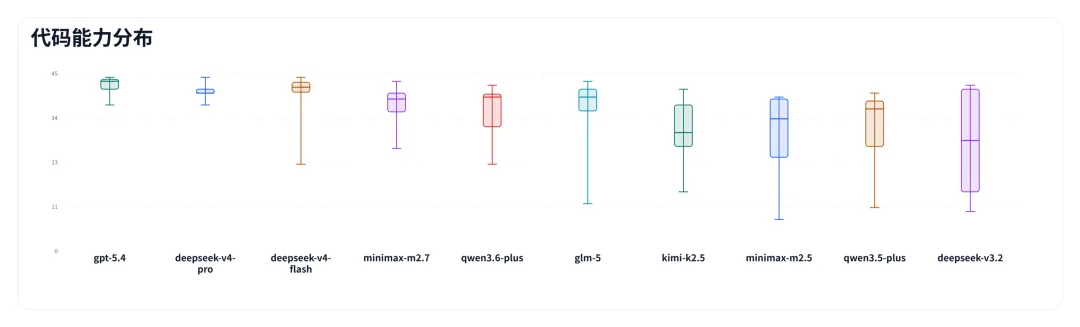
图片
在这个层面,deepseek-v4-pro 和 deepseek-v4-flash 在国产模型里表现最佳,为第一梯队,其余模型都有一定差距。第二梯队的 minimax-m2.7、qwen3.6-plus、glm-5 彼此相差不大,选谁更多取决于其他维度的偏好。值得一提的是 deepseek-v3.2——它的波动极大,好的时候能冲高分,差的时候也会垫底。这种不确定性在实际使用中意味着:同一个问题,结果是否可靠是不可预期的。
纪律性
纪律性考察的是过程质量,分数越高,说明工具调用、文档查阅、技能遵守和测试流程越完整。本质上,它决定的是:模型能不能沿着一条可控的路径把问题解决掉。
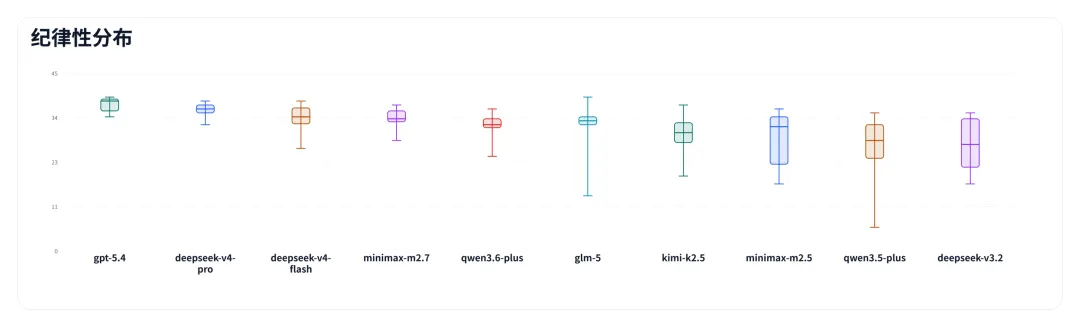
图片
deepseek-v4-pro、deepseek-v4-flash 和 minimax-m2.7 在这一维度上的优势比较明显。值得一提的是 minimax-m2.7,它在工具调用和文档查阅上尤其规范,在非 DeepSeek-V4 系里是这项得分最高的——这也是它能跻身第一梯队的重要原因之一。
qwen3.6-plus 和 glm-5 能完成大部分流程,但在复杂任务里稳定性略弱。qwen3.5-plus 是中游里最弱的一组,问题集中在调试阶段——遇到报错之后倾向于反复尝试,而不是定点排查,导致整体执行一致性不足。
执行效率
效率衡量的是投入产出比,由调试效率和时间成本构成。简单说,就是完成同一任务需要付出多少试错成本。
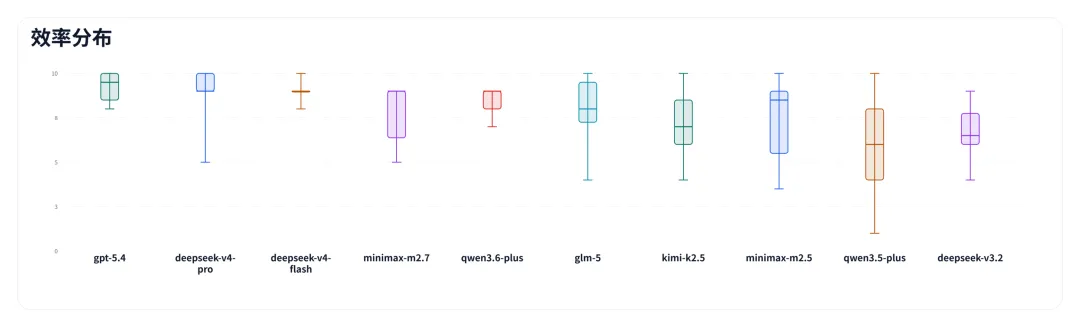
图片
deepseek-v4-flash 在这一维度上表现最佳,deepseek-v4-pro 和 qwen3.6-plus 紧随其后。这类模型通常能够较快收敛到可用结果,整体路径较短。minimax-m2.7 和 glm-5 略低一些,主要体现在完成同一任务时需要经历更多中间步骤。而 qwen3.5-plus 的效率问题最为突出,其表现为明显更长的尝试路径和更高的交互成本;kimi-k2.5 和 deepseek-v3.2 也存在类似情况。
结论
以上几个维度分析下来,本实验中各模型的优劣势其实已经比较清晰了,现在我们将其汇总如下:
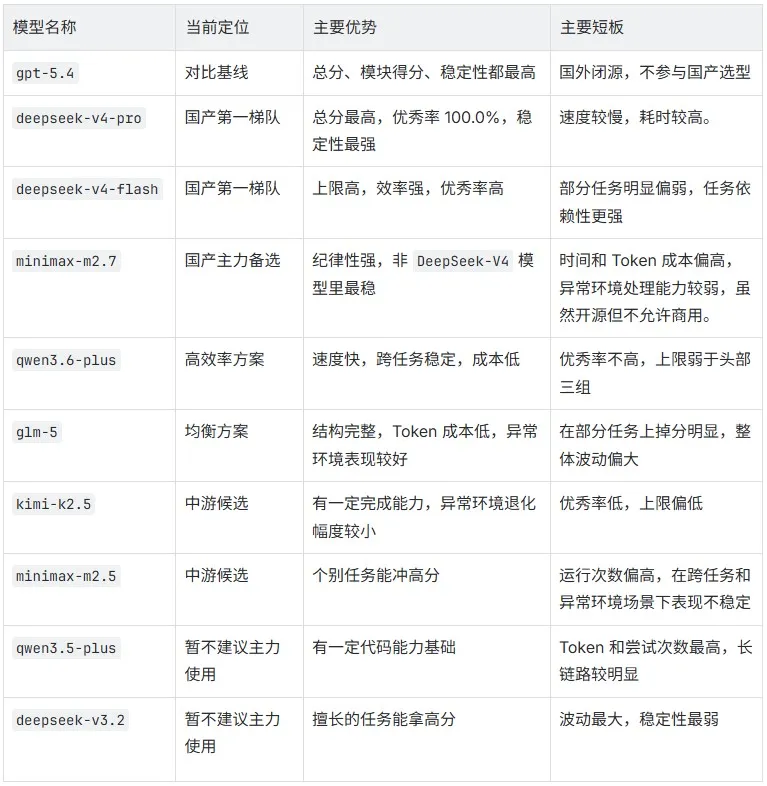
图片
把六个维度叠在一张雷达图上,模型之间的能力差异一目了然:
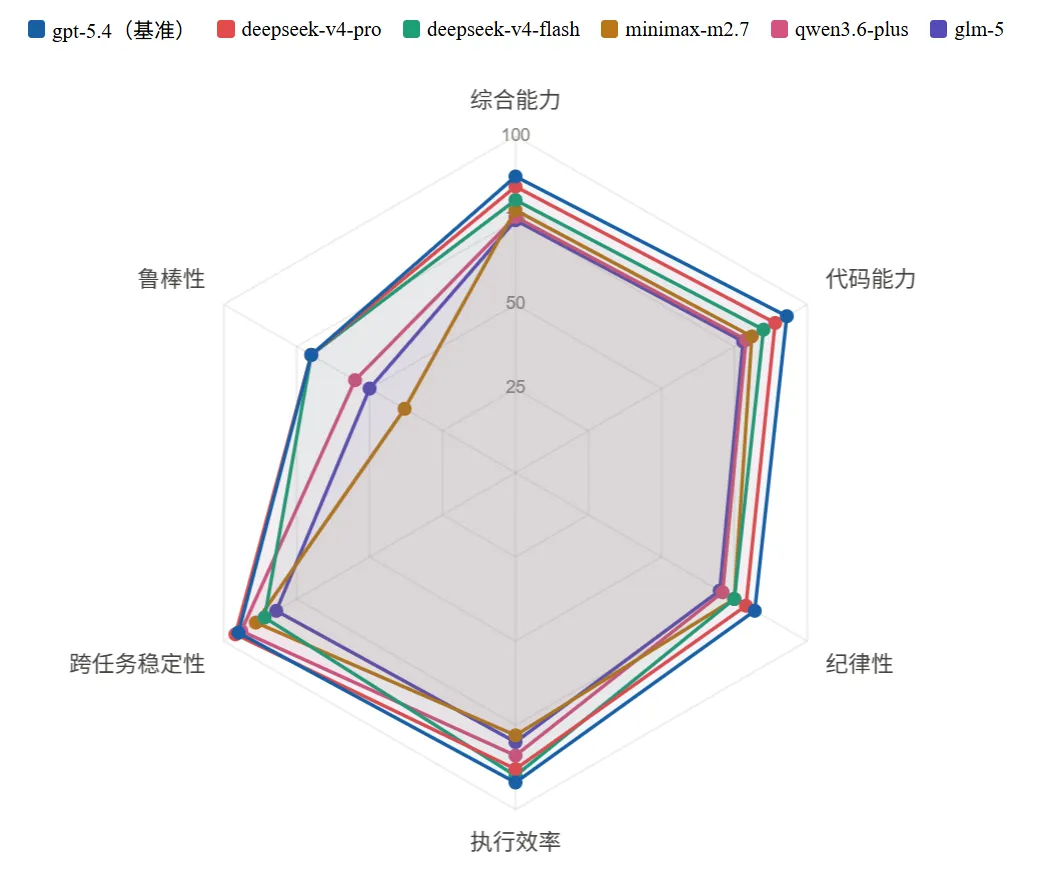
图片
从综合能力、稳定性和一致性来看,deepseek-v4-pro 是目前最适合作为主力的选择。优秀率 100%、跨任务 CV 最低、Token 消耗全场最低——结果质量、过程规范性和成本控制三项同时在线,是目前国产模型里唯一没有明显短板的选择。
如果更看重响应速度和吞吐效率,deepseek-v4-flash 值得优先考虑。它的平均耗时是所有模型里最短的,效率评分也排在国产第一。需要注意的是,它在事务型任务上的结果正确性不如 v4-pro 稳定,任务类型对它的发挥影响较大。
不想用 DeepSeek 系的话,minimax-m2.7 是目前最接近第一梯队的备选。它的纪律性得分在非 DeepSeek-V4 系里最高,过程质量和跨任务一致性都有保障。主要代价是时间和 Token 成本偏高,以及在异常环境下退化较明显。
如果预算有限、更在意性价比,qwen3.6-plus 和 glm-5 都值得考虑,侧重点不同:qwen3.6-plus 速度更快、跨任务稳定性更好,适合对吞吐有要求的场景;glm-5 各维度更均衡,异常环境表现在第二梯队里最好,适合对稳定性要求更高的场景。
最后,glm-5.1 本轮有效样本不足,暂未纳入正式对比。但考虑到 glm-5 的整体表现,后续值得持续关注。
结语
受限于样本规模与任务覆盖,且模型版本仍在持续迭代,本次测试的结论具有一定局限性。但我们做这件事的目的,不是给出最终确定答案,而是提供一个相对客观的参考以及可复用的测试框架。
如果你也想针对自己的场景做类似的测试,我们的测试框架可以直接复用,欢迎联系 DolphinDB 小助手。后续,我们也会持续跟进的模型的迭代,并增加更多测试样本。
希望了解更多测试细节?点击国产大模型在 DolphinDB 代码生成任务上的测评 - DolphinDB Blogs,进行跳转。
关于 DolphinDB
由智臾科技研发的高性能分布式时序数据库 DolphinDB,不仅支持海量数据的高效存储与查询,更开创性地提供功能完备的编程语言以支持复杂分析,以及高吞吐、低延时、开发便捷的流数据分析框架,是计算能力最强的数据库系统之一。目前,DolphinDB 已广泛服务于券商、基金、银行、保险等金融机构,以及能源、电力、工业制造等物联网行业的头部企业,显著提升了海量数据分析的效率,大幅降低开发成本。

图片
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号