不止于“爬”:如何构建真正可靠的情报采集系统

不止于“爬”:如何构建真正可靠的情报采集系统

易海聚开源情报
发布于 2026-04-21 16:46:07
发布于 2026-04-21 16:46:07
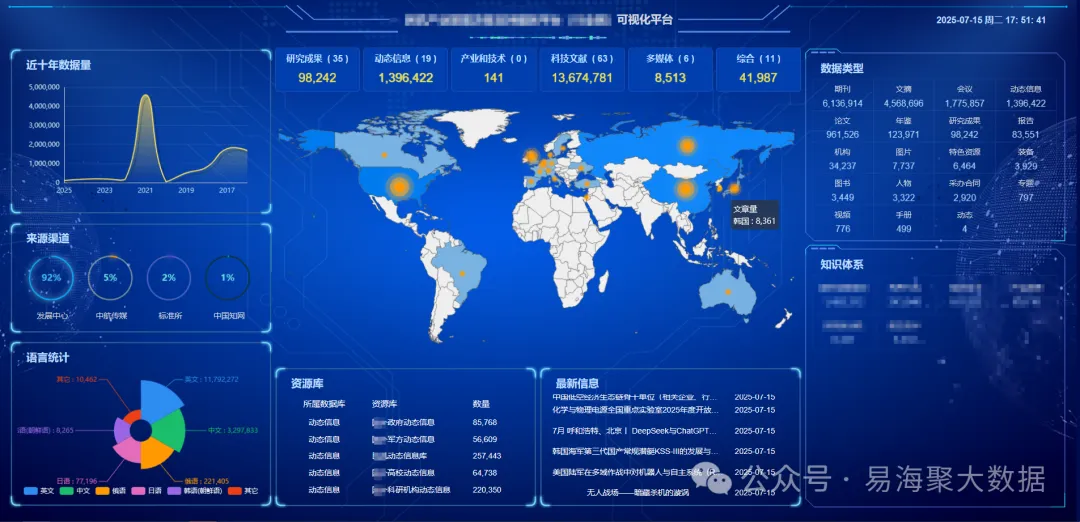
在当今信息高度互联的时代,网络数据已成为国家安全、公共治理、金融监管和企业竞争等领域的重要战略资源。作为开源情报系统的关键环节,网络信息采集承担着从海量公开信息中提取高价值数据的重任。然而,随着网站反爬机制不断升级、页面结构频繁变动、数据格式日益复杂,传统采集手段已难以满足实战需求。
作为深耕网络信息采集领域十余年的技术服务商,深圳易海聚依托自主研发与长期项目经验积累,构建了一套集“工具矩阵+智能配置+人工运维”于一体的抗干扰采集解决方案,在多个关键场景中实现了稳定、高效、精准的数据采集能力。
图片
一、突破账号登录限制:自动化模拟登录与Token复用策略
在实际采集过程中,越来越多的网站要求用户登录后才能访问核心内容。例如政务平台、社交媒体、电商后台、金融数据库等。面对这些限制,易海聚通常采用多种技术手段实现自动化登录与Token复用。
图片
1. 表单登录自动化模拟
我们使用无头浏览器工具,模拟真实用户登录行为,记录登录后的Session或Cookies,并在后续采集任务中复用。对于高并发场景,我们还构建了多账号多Cookie池管理机制,实现自动轮换,避免账号被封。
具体操作流程如下:
- 使用抓包分析目标网站的登录请求结构,定位用户名、密码字段以及验证码参数。
- 通过Python脚本构造POST请求,携带登录凭证进行提交。
- 成功登录后,将返回的Cookies保存至Redis缓存中,并设置过期时间。
- 采集任务调用缓存中的Cookies进行访问,确保采集过程无需重复登录。
- 设置定时任务定期检测Session有效性,自动重新登录,避免因超时导致采集失败。
该方法已在多个项目中应用,如某电商平台价格监测系统、某政务信息采集平台,均实现了稳定、高效的登录后数据采集。

图片
2. 手机验证码自动识别
对于需要短信验证码的登录方式,我们接入第三方短信平台,结合OCR识别技术,实现验证码自动识别与填写,大幅降低人工干预频率。
实施步骤如下:
- 在采集任务中嵌入短信接收接口,自动获取验证码短信。
- 使用OCR识别技术解析短信内容,提取验证码。
- 将验证码自动填写至登录表单中,完成登录流程。
该方案已在某金融数据采集项目中部署,有效解决了验证码登录带来的采集瓶颈。
3. OAuth2 登录
部分平台采用OAuth2授权机制,如微信、微博、Google账号等。我们通过抓包分析、逆向JS代码、模拟授权码获取流程,实现Token自动获取与续期,保障采集任务持续运行。
该机制已在某社交舆情监测项目中成功应用,覆盖微博、知乎等多个平台,实现多账号Token自动管理。
二、应对IP封锁:构建高可用IP资源池与智能轮换机制
IP封禁是网站防御采集最常用的手段之一。面对频繁的IP封锁问题,易海聚构建了一个百万级IP资源池,覆盖家庭宽带、数据中心、移动代理等多种类型,并结合智能轮换机制,实现高效采集。

图片
1. 多类型IP资源池
我们根据采集目标的风险等级,部署不同类型的IP资源:
- 家庭宽带代理:用于高风险网站采集,模拟真实用户行为,降低被识别为爬虫的风险。
- 移动代理:适用于社交媒体、短视频平台等行为验证较强的网站,支持多设备IP切换。
- 数据中心代理:用于一般网站采集,成本低、速度快,适合高并发场景。
- 自建节点:用于核心数据源采集,具备高可控性,可灵活部署在多个区域。
资源池统一由IP管理平台调度,支持按任务优先级、地理位置、目标网站封禁策略等维度进行智能分配。

图片
2. 智能IP轮换策略
我们开发了一套基于状态反馈的IP调度系统:
- 实时评估每个IP的存活率、请求成功率。
- 自动降权或剔除异常IP,避免因单个IP被封影响整体采集效率。
- 根据采集任务优先级分配高质量IP资源,确保核心任务优先执行。
具体实现方式包括:
- 每个IP在使用前进行健康检测,判断是否已被封禁。
- 每次请求后记录IP状态,更新至IP质量评估模型。
- 当IP请求失败率超过阈值时,自动切换至备用IP。
- 对于高风险网站,采用“一任务一IP”模式,降低被关联风险。
例如,在某金融监管项目中,原采集系统因IP被封导致日均采集量下降至不足1万条。部署IP资源池与智能轮换后,日均采集量提升至8万条,效率提升超10多倍。
三、破解页面搜索与行为验证难题:模拟用户交互与无头浏览器优化
部分网站设置了页面搜索限制、强制模拟用户行为等机制,极大增加了采集难度。例如知乎、小红书、Twitter等平台要求用户手动输入关键词进行搜索,甚至要求完成滑块验证、点击指定区域等操作。
图片
1. 页面搜索模拟
我们使用模拟用户输入关键词,并结合OCR识别验证码,实现自动搜索。采集结果缓存至本地数据库,避免重复提交请求。
以某政务服务平台为例,其政策文件库只能通过关键词搜索访问,且每小时最多提交50次请求。我们通过模拟输入+IP轮换+定时调度的方式,实现了每日稳定采集5000余条数据。
操作流程如下:
- 分析目标网站的搜索接口,判断是否支持参数构造。
- 若不支持,则使用模拟用户输入搜索词。
- 若存在验证码,则调用OCR识别服务自动填写。
- 将搜索结果缓存至本地数据库,避免重复提交请求。
2. 行为验证绕过
我们采用以下策略应对行为验证:
- 集成第三方打码平台:支持主流验证码识别,准确率达95%以上。
- 自研行为模拟算法:模拟人类鼠标移动轨迹、点击速度、停留时间等。
- 人工辅助干预机制:当系统识别失败时,由运营人员介入处理。
在一个项目的社交媒体采集中,我们成功绕过Twitter的滑块验证机制,实现连续14天无中断采集。
具体实现方式包括:
- 在采集任务中嵌入打码平台API,自动上传验证码图片并获取识别结果。
- 使用模拟鼠标滑动轨迹,模拟用户行为,比如向下滑动,热点区域停留,无规律滑动等。
- 对于无法自动识别的复杂验证码,系统自动将任务标记为“人工处理”,由运营人员介入。
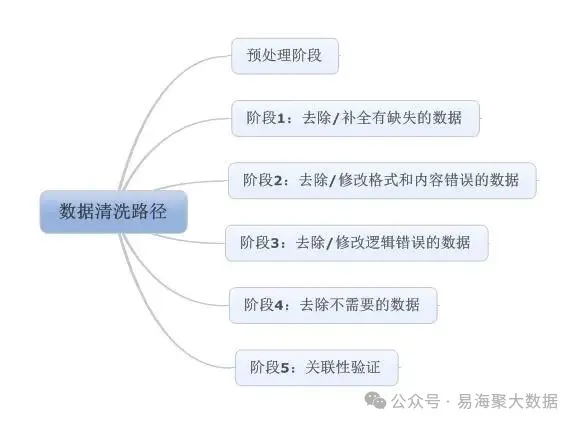
四、应对页面结构频繁变化:构建动态解析引擎与增量学习机制
网站频繁改版是采集工作中常见的“隐形障碍”。一旦页面结构发生变化,原有采集配置规则即失效,可能导致数据中断或遗漏,并且需要花费大量的人工来重新配置。
图片
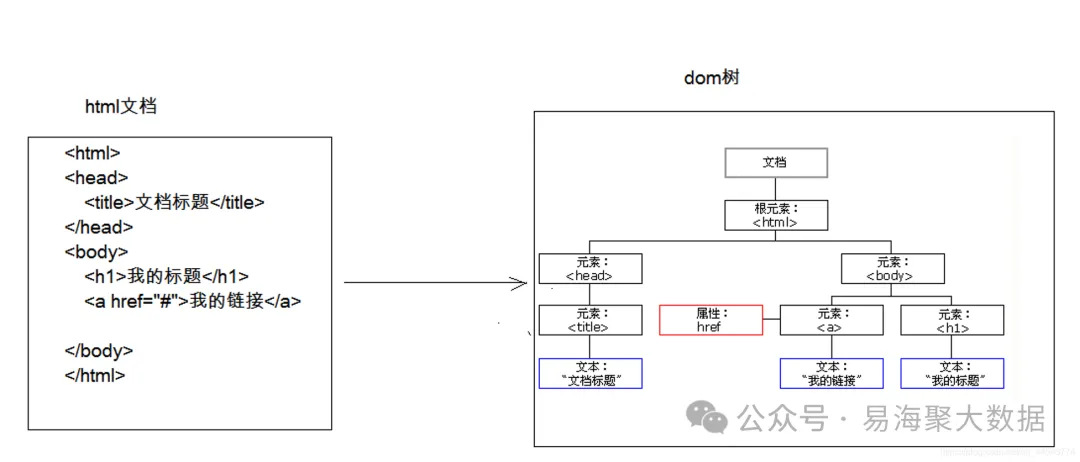
1. 动态DOM树分析
我们的采集配置有精准的人工配置,还有智能的通用配置。基于采集精准度要求稍低的采集,我们开发了一套基于XPath/CSS选择器的智能推荐系统,具备以下能力:
- 自动分析页面DOM结构,识别内容区块。
- 推荐稳定性高的XPath路径,并给出评分。
- 支持历史版本比对,快速定位结构变化位置。
该系统通过以下方式实现:
- 使用Selenium加载目标页面,提取完整的DOM结构。
- 分析DOM树,识别正文区域、标题、发布时间等关键字段。
- 根据历史采集记录,推荐稳定性高的XPath路径,并给出匹配度评分。
- 当页面结构发生变化时,自动触发比对流程,提示用户调整采集规则。
在某证券研究项目中,通过该系统将采集规则维护效率提升了60%以上。
2. 增量学习适配机制
我们采用一种轻量级机器学习模型,定期的对采集目标页面进行截屏,用于自动识别页面结构变化:
- 当检测到内容字段缺失或格式异常时,触发比对流程。
- 结合少量人工标注样本和设置,更新采集规则。
- 新规则部署时间控制在2小时内。
该机制已在多个项目中部署,例如某跨境电商监测项目,帮助我们实现了7×24小时不间断运行,大幅降低了人工干预频率。
具体实现流程如下:
- 设置采集字段的“完整度”指标,如文本长度、字段匹配率等。
- 当完整度下降至设定阈值时,触发结构变化检测流程。
- 系统自动调用历史采集规则进行比对,识别变化位置。
- 提供可视化界面供人工标注样本,训练模型更新采集规则。
- 新规则部署后,系统自动测试并上线,确保采集任务不中断。
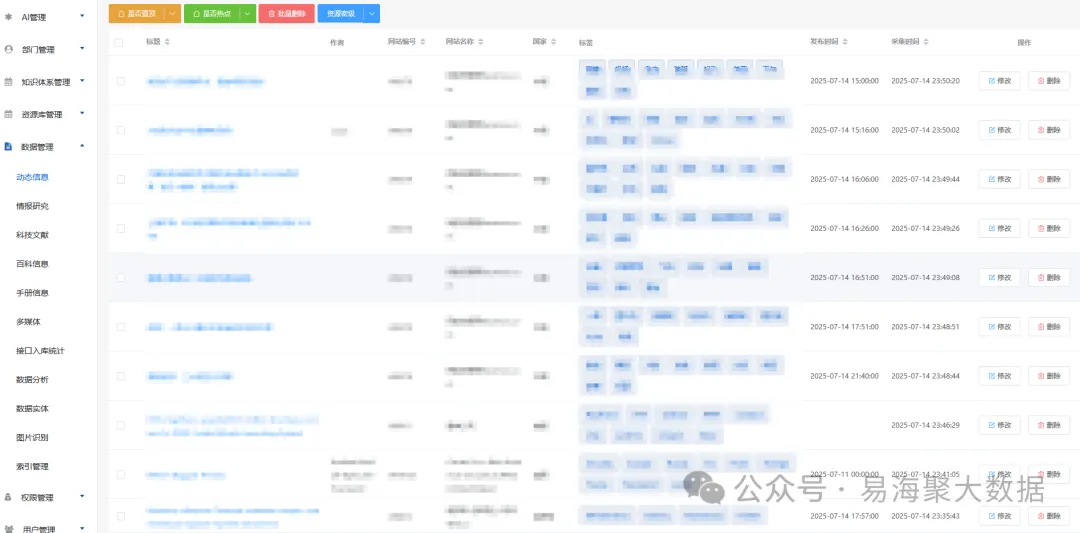
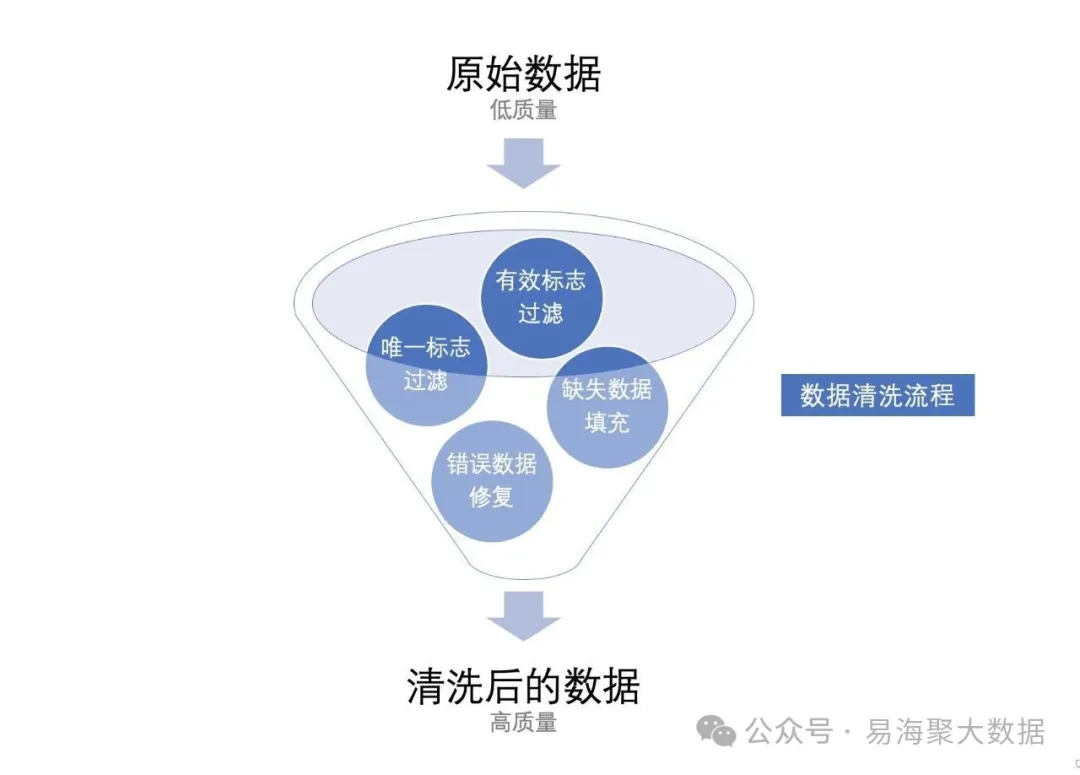
五、数据质量管控:四层清洗体系确保精准输出
大规模智能采集回来的数据往往包含无效信息,如广告位、重复内容、乱码等,严重影响后续分析准确性。为此,易海聚构建了一套完整的清洗流程,涵盖语法层、语义层、时间层和业务层。
图片
1. 语法层清洗
- 使用正则表达式库匹配200多种常见数据格式。
- 自定义标签剥离器,保留正文内容。
- 去除HTML标签、JavaScript脚本、CSS样式等非结构化内容。
图片
2. 语义层过滤
- 基于BERT模型进行文本相似度检测。
- 过滤广告、垃圾评论、重复内容等无效数据。
3. 时间戳校验
- 发布时间标准化处理(如“2025-04-05 14:30:00”格式)。
- 采集时间与发布时间交叉验证,剔除未来时间或明显错误时间。
- 支持多时区转换,确保时间数据的准确性。
图片
4. 异常值剔除
- 基于统计模型识别明显错误或异常记录。
- 设置字段长度、数值范围等规则,自动过滤异常数据。
- 支持自定义规则引擎,灵活应对不同数据源的异常情况。
例如,在一个知识产权监测项目中,该清洗体系将无效专利数据过滤率提升至92%,大大提高了情报的可用性。
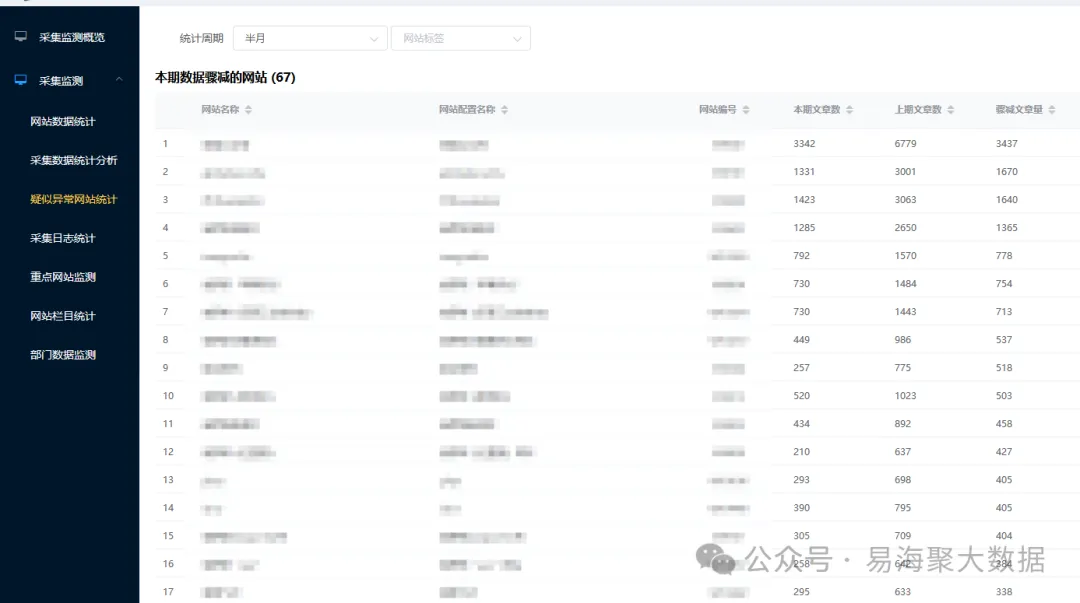
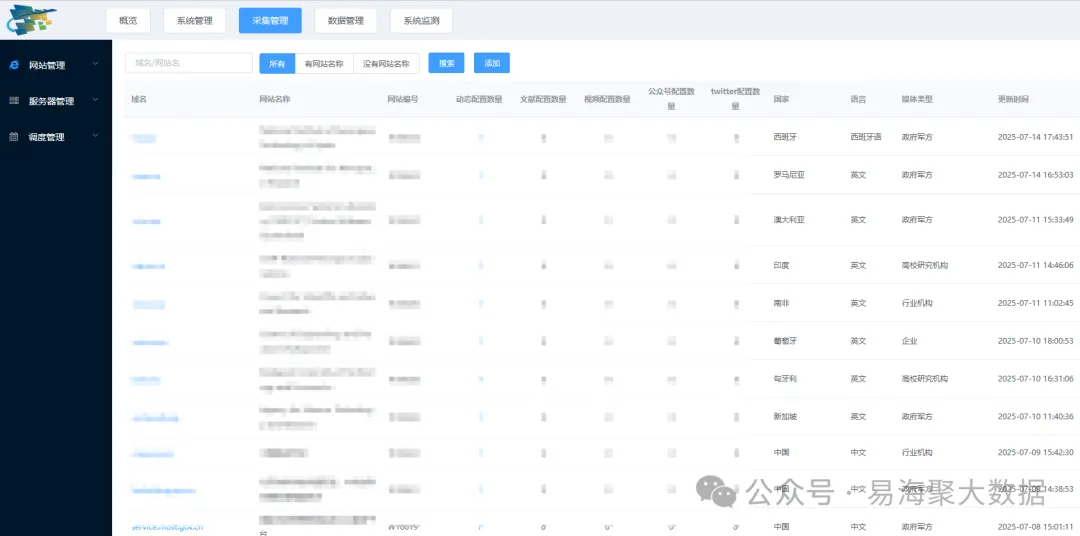
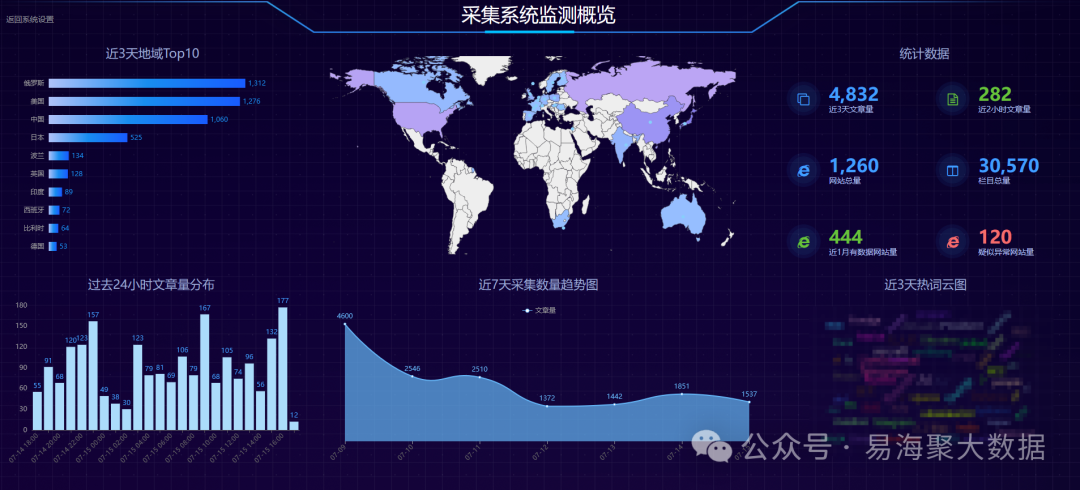
六、运维保障体系建设:智能监控与人工干预相结合
图片
1. 智能监控中心
我们搭建了实时监控平台,功能包括:显示各采集节点状态(CPU、内存、带宽);各个目标网站的入库数据情况;自动生成健康度报告(响应时间分布、错误率趋势); 提前预警潜在故障,缩短排查时间。
平台具备以下功能模块:
- 采集节点状态监控:实时显示各采集任务的运行状态、请求成功率、响应时间等关键指标。
- 异常检测与预警:设置阈值规则,当任务失败率、响应时间超过设定值时自动告警。
- 健康度评分系统:根据任务运行情况,对采集任务进行综合评分,辅助运维决策。
在一个电信运营商项目中,通过该系统提前4小时预警DDoS攻击,有效保障了采集稳定性。
图片
2. 人工干预平台
尽管自动化程度越来越高,但在复杂场景下仍需人工参与。我们建立了可视化规则编辑器,支持现场调试与即时调整,并沉淀专家经验库,累计覆盖5000多种异常情况。
平台功能包括:
- 规则编辑器:支持XPath、CSS选择器、正则表达式等多种规则编辑方式。
- 任务调试工具:提供在线调试功能,实时查看采集结果。
- 异常处理知识库:记录常见异常场景及解决方案,供运维人员快速参考。
图片
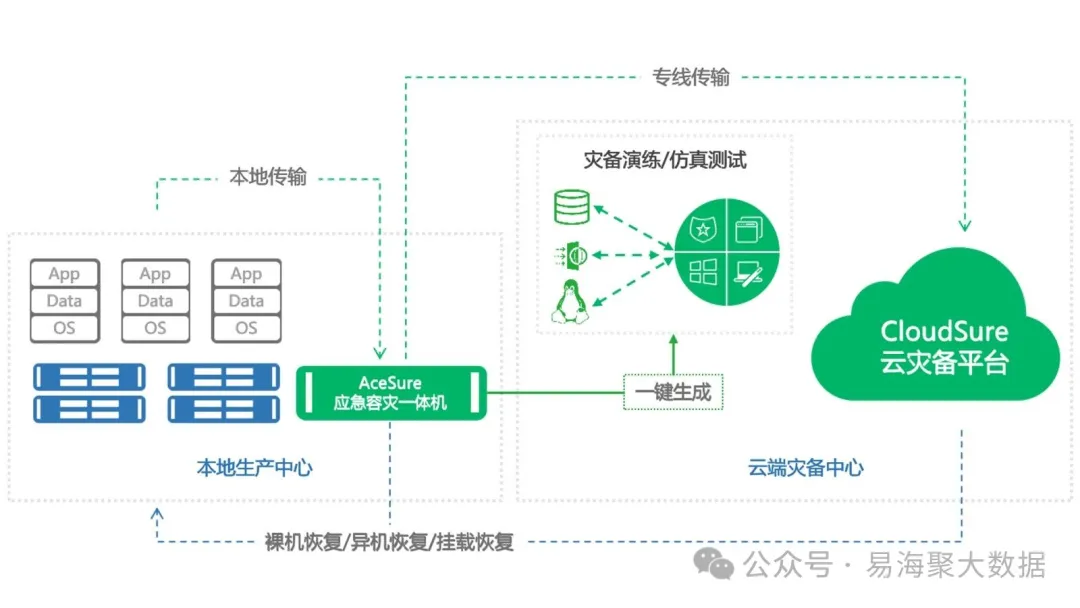
3. 灾备切换机制
我们部署了跨地域服务器集群,具备秒级故障转移能力,确保采集任务不中断。在一个能源领域的开源情报搜集项目中,该机制实现了跨云厂商的容灾能力。
具体实现如下:
- 在多个地域部署采集服务器,形成高可用集群。
- 每台服务器之间通过心跳机制实时通信,检测节点状态。
- 当某节点发生故障时,系统自动切换至备用节点,故障转移时间小于5秒。
- 支持多云部署(如阿里云、腾讯云、AWS等),实现跨云容灾。
图片
七、结语:让采集更高效、更可靠、更可控
在网络信息采集进入“深度对抗”时代的大背景下,单纯依赖单一工具或技术已难以满足实战需求。易海聚始终坚持“技术赋能+人工智慧”的融合理念,通过工具矩阵、智能配置、人工运维三位一体的架构,打造了一套稳定、高效、精准的采集系统。
未来,我们将继续深化技术研究,拓展应用场景,为国安、军工、金融、能源等多个领域提供专业、可靠的开源情报采集解决方案,助力构建更加智能、高效的情报工作体系。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号