售前打工人的龙虾进化史:从加班写标书到23个Skill解放双手
原创
售前打工人的龙虾进化史:从加班写标书到23个Skill解放双手
原创
君子不器
发布于 2026-04-20 19:14:06
发布于 2026-04-20 19:14:06
我是老王,一个在BI赛道摸爬滚打的售前打工人。 我的一天通常是这样的:
🌅 早上9点:到工位,打开电脑,先扫一眼微信——客户群里已经炸了3条消息,一个是催方案进度的,一个是问演示能不能提前到明天
🕐 上午10点:邮箱里躺着一封新邮件,RFP来了。200多页的招标文件,附件就有8个,要求3天内交完整方案+报价——连周末都搭进去的那种
🕑 下午1点:刚扒了两口外卖,销售兄弟发来一条语音:"老王,明天下午的客户demo你准备得怎么样了?对方是技术总监,可能会问性能和并发的事"
🌙 晚上8点:终于把方案初稿搞完了,打开周报模板开始凑字数……等等,这周的客户调研资料放哪个文件夹来着?
🌙 晚上11点:关上电脑,脑子里还在转:"那个客户的IT架构到底用的什么数据库来着?"
如果你也是做售前的,上面这些场景你应该每一个都能对上号。
直到半年前,我的生活还是这个节奏。
然后我遇到了 OpenClaw 的免部署版——WorkBuddy。更准确地说,是遇到了它的 Skill 插件系统。
现在?我是一个手握 23 个自定义 Skill 的「养虾大户」。今天毫无保留地把这套东西分享出来——如果你也想从上面的死循环里逃出来,这篇文章建议先收藏再看。
一、我的进化路线图:从聊天工具到数字员工
图1:三阶段进化路线图 - 从纯聊天到装插件到自建Skill生态
🦕 第一阶段:纯聊天时代(2025年底)—— "AI好像也没那么神"
刚接触 WorkBuddy 时,我和大多数人一样——把它当高级版 ChatGPT 用:
我:帮我写一段XX报表产品的介绍
AI:好的,这是产品介绍……(中规中矩,能用但不出彩)
我:帮我总结一下这个客户的资料
AI:好的,这是总结……(但每次都要重新粘贴上下文)说实话,用了一段时间后有点失望:
- ❌ 每次都要重新描述背景和上下文(它不认识我的客户)
- ❌ 无法直接读取本地文件(还得我自己复制粘贴)
- ❌ 做完一次就忘,下次还得从头说(跟金鱼似的)
- ❌ 效率提升约 20%——有总比没有强吧
感觉就像请了个很聪明但失忆的实习生。
🐣 第二阶段:装插件时代(2026年初)—— "好像有点意思了"
发现了 Skill 系统后,我开始疯狂安装现成的 Skill,像发现了新大陆:
- xlsx —— 处理客户数据表格
- docx —— 生成Word方案文档
- pptx —— 快速出演示PPT
- pdf —— 解析招标文件(终于不用自己一页页翻了)
- 浏览器自动化 —— 抓取竞品信息
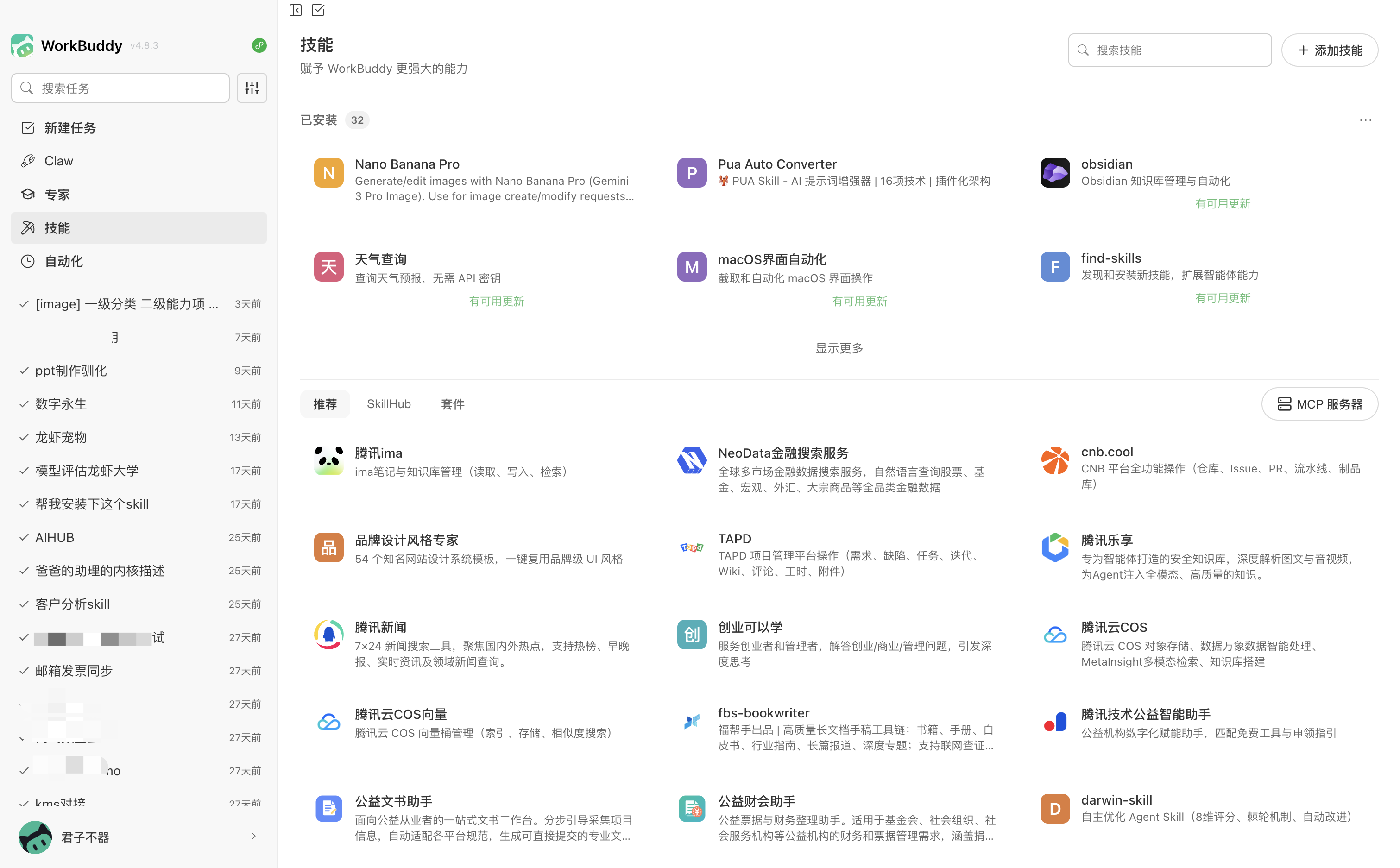
图2:已安装的Skill列表截图
效率提升到了 50% 左右。至少不用再手动复制粘贴了。
但还是觉得差点意思——这些通用插件就像瑞士军刀,什么都能干一点,但不懂我的业务场景。比如它能帮你读PDF,但它不知道一份RFP里哪些条款是关键评分项;它能帮你写PPT大纲,但它不知道我们行业的客户最在意什么。
🦞 第三阶段:自建 Skill 生态(现在)—— "这才是真的起飞了"
真正让我觉得这玩意儿能替代半个我的,是自己动手写 Skill 之后的事。
目前我已经搭建了 23 个自定义 Skill,基本覆盖了售前工作的全链路:
类别 | 核心Skill | 解决什么问题 |
|---|---|---|
🔍 客户分析 | prospect-analyst | 扔一个客户文件夹给它,自动出需求文档 |
📊 商业洞察 | -insight | 查企业信息、看竞品、筛商机 |
👥 团队协作 | wechat-group-analyzer | 微信群聊自动变周报 |
🧠 记忆系统 | memory-manager + Obsidian | 跨会话记忆,再也不用重复交代背景 |
📚 内部知识 | our-kms | 一键查公司内部知识库 |
📧 办公自动化 | QQ邮箱 / 发票整理 / 腾讯会议 | 邮件收发+发票归类+会议管理 |
🎨 内容创作 | pptx / docx / 报表模板解析 | 方案文档一站搞定 |
🔧 数据查询 | 金融数据 / Google服务自动化 | 外部数据随手查 |
🎮 有趣玩法 | 桌面宠物 / PUA提示词增强器 | 工作累了还能摸鱼 |
甚至于我还自己构建了一个AI SKILL应用市场
图3:AIhub skill应用市场截图截图
整体效率提升:约 70%-80%。
什么概念呢?就是以前周五晚上还在赶的东西,现在周四下班前就搞定了。省下来的时间干嘛?后面细说。
下面挑 4 个最能打的 Skill,讲讲它们怎么改变了我的一天。
二、核心 Skill 实战展示:4个真实场景
🏆 Skill 1:prospect-analyst —— 客户需求自动分析器
💡 这是什么?
给我一个客户文件夹路径——里面可能有 pdf、docx、xlsx、pptx 各种乱七八糟的文件——它自动扫描所有文件 → 提取关键信息 → 生成一份结构化的需求分析报告,直接存到我的 Obsidian 知识库里。
🔥 解决的那个痛
做过售前的都知道,接到一个新客户跟进任务的时候有多头大:
❌ 传统流程(耗时 2-4 小时):
1. 打开客户文件夹——好家伙,15个子目录,42个文件
2. 一个个打开看:这是之前的会议纪要,那是技术规格说明书,
还有几张不知道谁做的Excel表……
3. 一边看一边记笔记:客户什么行业?多大?用什么系统?
预算多少?谁是对话人?决策流程是什么?
4. 整理成需求文档——格式还每次都不一样,看心情
5. 开始构思解决方案框架
→ 结果:经常漏看某个关键文件里的信息,
或者同一个客户下次再跟进时又忘了之前看过什么
→ 最惨的是:有时候看到第20个文件才发现,
第3个文件里早就写了核心诉求……有没有一种可能,这些活可以让机器干?
✨ 现在怎么做
只需要一句话:
帮我分析下 /path/to/客户跟进/某某科技集团/然后它就会自动干活:
- 扫描文件夹内所有支持的文件格式(pdf/docx/xlsx/pptx/txt/md)
- 提取关键维度:行业、规模、已有系统、核心痛点、预算、时间要求……
- 联网补全企业的工商信息和最新动态
- 输出一份完整的分析报告 + 初步方案建议
全过程大约 3-5 分钟。 我一般这时候去倒杯水,回来就好了。
图4:prospect-analyst 执行效果
📊 输出示例(精简版)
# 客户需求分析报告 - XX科技集团
## 一、企业画像
- **名称**:XX科技有限公司
- **行业**:互联网/企业服务
- **规模**:年营收约20亿,员工2000+
- **上市情况**:已上市(港股)
## 二、核心诉求(从文件中自动提取)
1. 多业务线数据分散,缺统一的数据资产管理平台
2. 管理层要实时经营驾驶舱 + 移动端查看(老板爱看手机)
3. 业务部门想自己做分析,不想天天找IT提需求
4. 数据安全合规要求高,必须私有化部署
## 三、技术约束
- 已有MySQL + ClickHouse混合数据架构
- 必须支持私有化部署
- 预算区间:80-150万/年(注意:含实施费)
- 时间要求:Q2完成POC验证(很急!)
## 四、推荐方案方向
基于XX报表 + XXBI 组合:
- XX报表:复杂报表+填报+移动端+数据大屏
- XXBI:自助分析+数据挖掘+AI辅助分析
- 数据集成平台:多源数据接入与调度
## 五、风险预警 ⚠️
⚠️ 对方技术团队自研能力强,要突出产品成熟度和交付效率
⚠️ 同时在看开源方案,准备好差异化对比效果对比:
维度 | 以前 | 现在 |
|---|---|---|
耗时 | 2-4小时/客户(还要集中精力) | 3-5分钟(倒杯水的时间) |
信息遗漏率 | 高(翻着翻着就困了) | 低(机器逐字扫描不犯困) |
输出质量 | 看当天心情 | 固定模板,稳定输出 |
可复用性 | 无(下次重来) | 自动归档,随时回溯 |
🏆 Skill 2:john-insight —— 商业洞察助手
💡 这是什么?
一个商业数据分析工具。输入一家公司名字,返回企业全景画像——工商信息、股权结构、财务概况、新闻舆情等。相当于给你配了一个24小时在线的行研助理。
🔥 使用场景
场景A:明天要去拜访客户,今晚做功课
帮我查一下 腾讯公司 的基本情况
图5:john-insight 查询企业信息输出示例
30秒出结果。股权结构、主要高管、财务数据、最近新闻——该知道的都知道了。
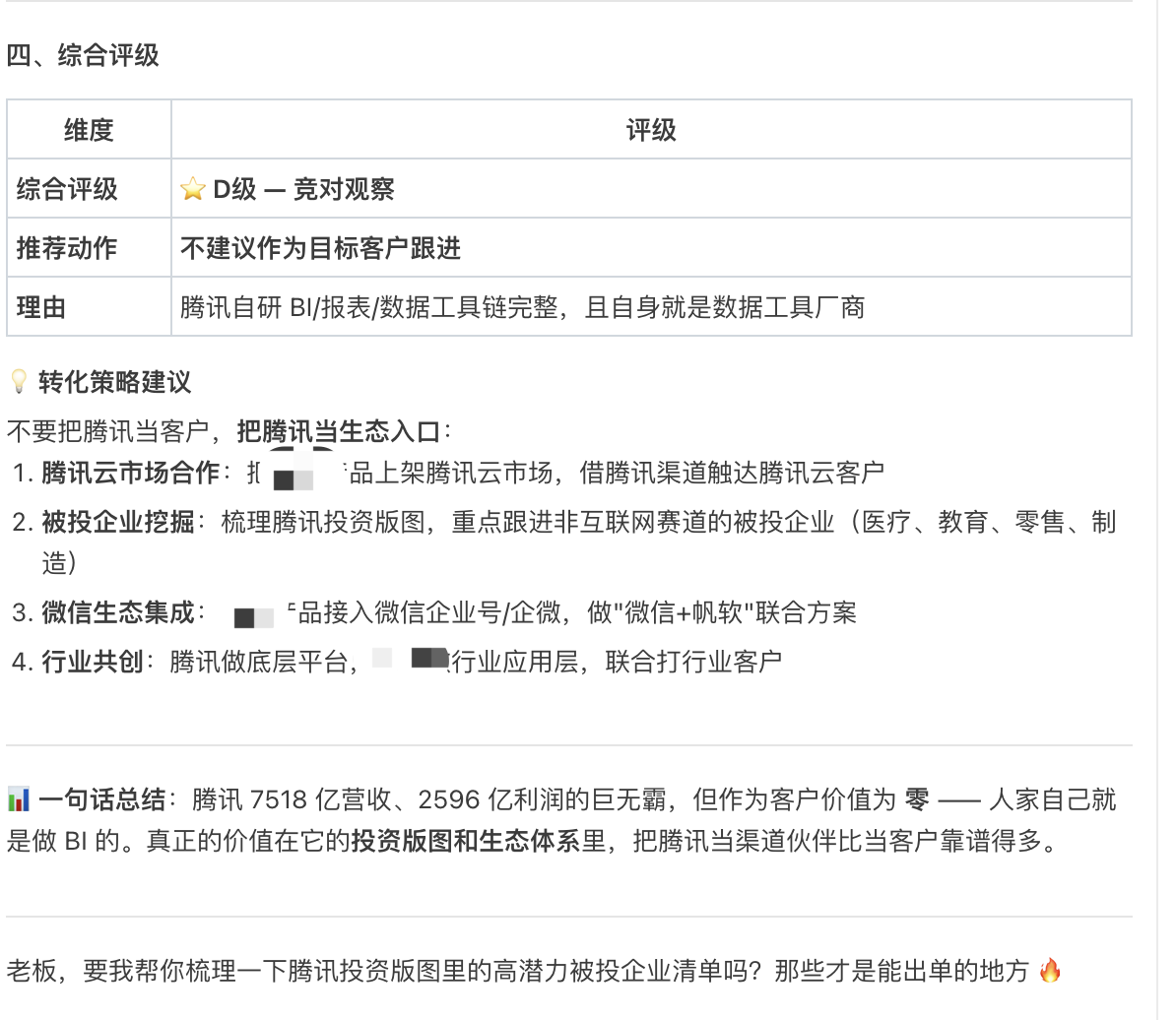
场景B:客户突然问竞品,现场要怼回去
分析一下XXBI的核心竞争对手,重点关注Tableau和Power BI的市场策略场景C:老板让找潜在客户线索
帮我筛选一下华南地区年营收10亿以上的互联网企业🎯 真实案例:某互联网大厂数据中台项目
有一次投一个互联网大厂的项目,时间特别紧。我用 john-insight 半个小时搞定的事情包括:
- 客户画像:股权结构(知道谁是最终决策人)、组织架构(事业群制,每个BG独立核算)、主要业务线布局
- 行业趋势:互联网行业从增量市场转向存量运营,数据驱动决策已经从nice-to-have变成must-have
- 竞争格局:其他 BI 厂商在这个行业的渗透情况 + 他们自研数据平台的现状(知己知彼)
- 切入点:结合其多业务线数据打通和实时大屏展示的需求,精准定位我们的优势
以前这种调研至少花半天,还要翻各种网站、下各种报告。现在30分钟搞定,而且信息更有条理。
🏆 Skill 3:wechat-group-analyzer —— 微信群自动分析师
💡 这是什么?
我们售前团队有个微信群叫「上海滩售前」——名字挺霸气,其实就是大家日常在里面同步客户进展、吐槽奇葩需求、互相救火。
这个 Skill 能自动分析群聊记录,每周生成团队周报。
🔥 为什么需要它?
来,我问一个问题:
你写过周报吗? 更准确地说,你在周五下午5点,经过一周的高强度工作后,坐在工位上回忆"我这周到底干了啥"——这种感觉熟悉吗?
- ❌ 周五下午脑子已经转不动了,但周报deadline就在6点
- ❌ 明明这周干了好多事,但坐下来一想……好像什么都想不起来
- ❌ 有些重要事项是在群里口头说过、但没写下来的——然后你就真忘了
- ❌ 汇总团队周报的时候,每个人格式不一样,拼在一起像俄罗斯方块
现在?群里每天的闲聊就是最好的素材来源。
✨ 怎么用
1. 导出微信群聊记录(微信自带功能,一键导出)
2. 运行 wechat-group-analyzer 分析脚本
3. 自动提取本周关键事件、客户进展、风险预警
4. 生成结构化周报 → 存到指定目录
图6:wechat-group-analyzer 生成的周报
生成的周报长这样:
板块 | 内容 |
|---|---|
📈 本周进展 | 谁跟了哪家客户,推进到哪一步了 |
🚨 风险预警 | 哪个项目可能延期、哪个客户有丢单迹象 |
🤝 协调事项 | 谁需要支援、谁有资源可以共享 |
💡 经验沉淀 | 本周踩了什么坑、有什么值得复用的方法论 |
最爽的不是省时间——而是再也不怕忘记某件口头交代过的重要事了。群里有记录 = 周报有素材 = 年底写总结也有据可查。
🏆 Skill 4:memory-manager —— 让AI记住你是谁
💡 这是我的"秘密武器",也是我觉得最有价值的一个Skill。**
先说一个所有 AI 用户都遇到过的问题:
每次新对话,AI 都失忆了。
你上次跟它讨论过的客户偏好、你的写作风格习惯、你定下的项目规范——全部清零。
于是你陷入了这样的循环:
新对话开始
↓
"我是做XX行业的售前,我的客户主要是……"
"我偏好XX风格的方案文档……"
"这个项目的技术约束是……"
↓
(每!次!都!要!重!说!一!遍!)memory-manager 彻底终结了这个循环。
🔧 它的工作原理
三层记忆架构:
┌─────────────────────────────┐
│ 第一层:会话记忆(当前对话) │ ← 正在聊的内容,本次可用
├─────────────────────────────┤
│ 第二层:短期记忆(Daily Log)│ ← 今天干了什么,跨对话可读
├─────────────────────────────┤
│ 第三层:长期记忆(Memory) │ ← 精炼的知识库,永久保存
│ · 你的身份和偏好 │
│ · 客户档案 │
│ · 项目规范 │
│ · 踩坑经验 │
└─────────────────────────────┘
↕ 双向同步
Obsidian 知识库(本地备份)
图7:记忆系统架构与实际存储文件
🎯 一个真实例子
假设我在某次对话中随口说了句:「以后写方案默认用浅色系PPT背景,客户喜欢清爽的风格。」
没有 memory-manager: 下次新对话 → AI 又不知道了 → 要么你又得说一遍,要么它给你生成了深色主题的你又得改回来
有 memory-manager: 这句话被自动记入长期记忆 → 之后每一次对话它都知道 → 永久生效,除非你让它改
📊 价值量化
场景 | 没有 | 有 |
|---|---|---|
"我这个客户叫什么来着?" | 😵 翻半天聊天记录 | ✅ 记忆库秒查 |
"上次方案用的什么风格?" | 🤷 得重新找旧文件 | ✅ 直接读取 |
"客户之前提过什么反对意见?" | ❓ 早忘了 | ✅ 记忆库里写着呢 |
Token消耗 | 每次重述上下文 = 浪费钱 | <500 token 即刻加载 |
这不是锦上添花——这是让 AI 从"一次性的聊天工具"变成"越用越懂你的数字同事"的基础设施。
用了之后你会有一种奇妙的感觉:这个 AI 终于记住我了。
三、Skill 开发心得:其实没你想的那么难
很多人听到 "23 个自定义 Skill" 的第一反应是:
"这得写多少代码啊?我不会编程怎么办?"
好消息:不需要你会写代码。
📁 一个 Skill 的真实长相
my-skill/
├── SKILL.md ← 核心定义文件(只有这个是必填的!)
├── scripts/ ← 脚本文件(可选,复杂逻辑时才需要)
│ └── analyze.py
└── references/ ← 参考资料(可选,放模板什么的)
└── template.md
图8:某个Skill的文件夹内部结构
核心就只有一个文件:SKILL.md。 它就是一个 Markdown 文件,定义三件事:
- 触发词:什么时候激活这个 Skill?(比如我说"帮我分析下 xxx")
- 指令集:激活后干什么?(用自然语言写就行!)
- 依赖说明:需要调用哪些脚本或 API
举个真实的例子,这是我写的 our-kms 的 SKILL.md:
---
description: 公司KMS知识库访问工具。
触发关键词:查一下KMS、KMS上有没有、公司内部资料
---
# KMS 知识库查询
当用户询问公司相关文档或资料时:
1. 使用 browser-automation 打开公司知识库地址
2. 在搜索框输入用户的关键词
3. 搜索结果页面提取相关文档链接和标题
4. 总结搜索结果,按相关性排序返回给用户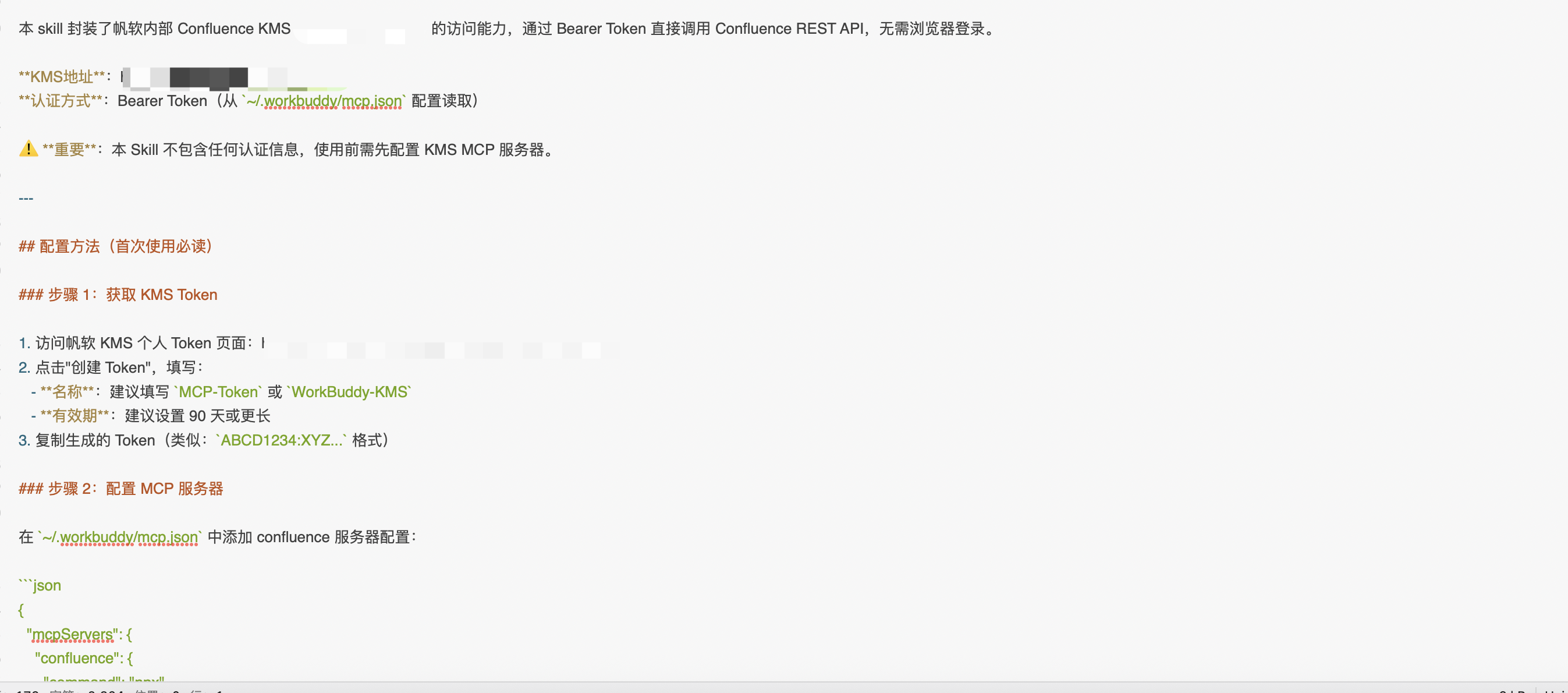
图9:SKILL.md 文件内容截图
看到了吗?全程没有一行 Python 代码。 就是用人话告诉 AI:"当用户说要查KMS的时候,帮他去知识库搜一下。"
这就是我喜欢 WorkBuddy Skill 系统的原因——门槛极低,上限极高:
- 🟢 入门:写几行自然语言指令 → 5分钟搞定,立即可用
- 🟡 进阶:加个 Python 脚本处理复杂逻辑
- 🔴 高手:对接外部 API(商业洞察、金融数据接口随便接)
🛠️ 我的实际开发流程
发现重复性问题("这事我怎么每周都要跟AI说一遍?")
↓
创建 SKILL.md(5-10分钟,用自然语言写就行)
↓
在实际使用中发现不足 → 迭代优化
↓
稳定了 → 上传到技能市场(可选,造福同行)第一个 Skill 是最难的一步。一旦你写了第一个,后面就停不下来了——因为你会发现工作中到处都是可以被自动化的东西。
四、效率数据:到底提升了多少
好了,吹了这么多,来点真实的数据。(以下是我近一个月的实际记录)
📊 单项任务前后对比
任务类型 | 以前 | 现在 | 提升幅度 |
|---|---|---|---|
客户需求分析 | 3小时(还要高度专注) | 5分钟(倒杯水的时间) | ⬆️ 97% |
RFP标书写初稿 | 2天(通宵那种) | 4小时(下午就能搞定) | ⬆️ 75% |
竞品对比材料 | 半天 | 40分钟 | ⬆️ 72% |
团队周报 | 1.5小时(最痛苦的1.5h) | 全自动生成 | ⬆️ 95% |
客户调研(初筛) | 2小时 | 20分钟 | ⬆️ 83% |
方案PPT大纲 | 3小时 | 30分钟 | ⬆️ 83% |
⏰ 每周省出来的时间
活动 | 每周省多少 |
|---|---|
客户分析(每周3-5家) | ~10小时 |
各种文档撰写 | ~6小时 |
信息搜集和调研 | ~4小时 |
团队协作/周报 | ~2小时 |
杂事(邮件/发票/会议纪要) | ~2小时 |
合计 | ~24小时 ≈ 3个工作日 |
每周多出来3天。
你可以用来做什么?
- 深度思考客户战略而不是忙着填模板
- 精心打磨方案的每一页PPT而不是赶deadline
- 学习新东西提升自己
- 或者——准时下班,陪家人吃顿晚饭
五、踩坑指南:新手别走弯路
养虾半年,踩过的坑比吃过的虾还多。列几个最常见的:
⚠️ 坑 1:贪大求全
错误做法:一上来就想做一个"全能型超级 Skill",恨不得把所有功能都塞进去。
正确做法:单点突破,小步快跑。
我第一个 Skill 只做了一件事——"扫描文件夹 + 生成需求摘要"。后来才慢慢加了联网调研、方案推荐、风险预警等功能。
先用起来,再慢慢迭代。完美是改进出来的,不是设计出来的。
⚠️ 坑 2:忽略触发词
错误做法:SKILL.md 写得很笼统,结果你自己说话的时候根本匹配不上,Skill 永远不会被自动唤醒。
正确做法:触发词要覆盖你真实的说话方式。
比如 prospect-analyst 的触发词经历了这么几轮进化:
第一版:客户分析
→ 问题:太正式了,我日常不会这么说
第二版:客户分析、需求梳理、帮助分析xx路径
→ 问题:覆盖面还不够
第三版(现在的):帮我分析下 xx 路径 /
做客户需求研究 /
梳理这个客户的需求 /
分析这个客户 /
输出需求文档
→ 完美:不管我怎么表达,都能命中技巧:回想一下你日常怎么说这件事的,原封不动写进去就好。
⚠️ 坑 3:记忆爆炸
错误做法:什么往记忆系统里塞,结果 token 消耗爆炸,真正重要的信息反而淹没在海量垃圾里。
正确做法:分级存储,只记"下次还会用到"的东西。
存哪里 | 存什么 | 存多久 |
|---|---|---|
会话记忆 | 当前任务的上下文 | 本次对话 |
日志记忆 | 当天干了什么 | 30天后归档 |
长期记忆 | 客户档案、规范、偏好、经验 | 永久保存 |
不是所有信息都值得被记住。好的记忆系统不是什么都记,而是知道什么该忘。
六、写在最后
回看这半年的"养虾之路",最大的感悟其实就一句话:
OpenClaw / WorkBuddy 不是聊天机器人——它是一套可以无限扩展的个人操作系统。
大多数人停在第一层:把它当更聪明的搜索引擎。
但你一旦开始自定义 Skill,就进入了第二层:让 AI 按照你的思维方式、你的工作流、你的业务场景来干活。
对于售前人来说,这意味着什么?
- 🚀 不再从零开始写每一份方案——有模板、有上下文、有历史经验
- 🧠 不再担心忘记客户的重要信息——记忆系统比你记得牢
- ⏰ 不再被重复性工作吞噬时间——那些机械的事交给机器
- 🎯 把精力集中在真正需要人的地方——理解客户、建立信任、创造价值
如果你也想开始搭建自己的 AI 工作流,这是我的建议:
- 今天:列出你最常做的 3 件重复性工作(哪怕很小的事也算)
- 本周:为其中一件创建你的第一个 Skill(相信我,5分钟就够了)
- 本月:把几个 Skill 串联成工作流——然后享受被自动化宠坏的感觉
🦞 祝大家的龙虾永不报错,售前之路越走越宽!
如果这篇对你有帮助,欢迎 点赞👍 在看⭐ 转发🔄 给同样在售前路上奋斗的小伙伴们!
有问题评论区交流,我看到都会回~
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号