[数据分析]工具变量:寻找一个神奇的"代理"
原创

I. 引言
在实证研究领域,我们经常面临一个根本性挑战:如何从观察数据中识别因果效应? 当解释变量与误差项相关时,即存在内生性问题,传统的回归分析只能提供相关关系而非因果关系。工具变量方法正是为解决这一难题而生的强大武器。
工具变量(Instrumental Variables, IV)方法被誉为"计量经济学的皇冠",它通过寻找一个特殊的"代理"变量,帮助我们穿透内生性的迷雾,识别因果效应。就像天文学家使用引力透镜来观察遥远的星系一样,工具变量让我们能够"弯曲"观察数据的光线,揭示隐藏的因果真相。
内生性问题的普遍性
内生性问题在社会科学和医学研究中无处不在:
- 教育回报研究:教育程度与能力相关,但能力往往不可观测
- 医疗效果评估:治疗选择与患者健康状况相关,存在选择偏误
- 政策评估:政策实施往往不是随机的,与地区特征相关
在这些情境中,简单比较处理组和对照组会得到有偏的估计。工具变量方法通过引入一个只通过影响处理变量来影响结果变量的工具,为因果识别提供了可能。
工具变量的直觉理解
想象我们想估计教育对收入的影响。问题在于能力强的人既可能获得更多教育,也可能获得更高收入,导致教育变量与误差项相关。如果我们能找到这样一个变量:它影响一个人是否接受更多教育(如学校距离),但不会直接影响收入(除了通过教育),那么这个变量就是教育的有效工具。
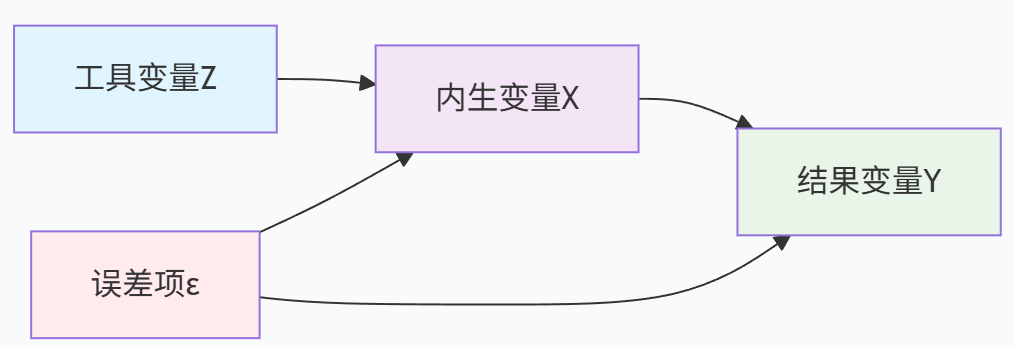
这种设计打破了X和ε的相关性,使我们能够估计X对Y的因果效应。
II. 工具变量的理论基础
内生性问题与因果识别
内生性问题源于解释变量与误差项的相关性,主要来自以下几个渠道:
内生性来源 | 描述 | 例子 |
|---|---|---|
遗漏变量 | 未观测的混淆因素影响解释变量和结果变量 | 能力同时影响教育选择和收入 |
测量误差 | 解释变量测量不准确导致 attenuation bias | 收入报告的随机误差 |
simultaneity | 因果关系双向同时发生 | 价格和需求量相互决定 |
选择偏误 | 样本选择非随机导致的有偏估计 | 只有就业者才报告工资 |
工具变量方法的核心思想是找到一个变量Z,满足以下两个关键条件:
工具变量的有效性条件
- 相关性条件:工具变量Z与内生解释变量X相关
- Cov(Z, X) ≠ 0
- 工具变量必须能有效预测内生变量
- 排他性约束:工具变量Z只通过X影响Y,没有其他路径
- Cov(Z, ε) = 0
- 工具变量与误差项不相关
两阶段最小二乘法(2SLS)
工具变量估计最常用的方法是两阶段最小二乘法:
第一阶段:内生变量X对工具变量Z和 exogenous 变量回归
X = γ₀ + γ₁Z + γ₂W + ν
第二阶段:结果变量Y对第一阶段预测值X̂和 exogenous 变量回归
Y = β₀ + β₁X̂ + β₂W + ε
2SLS估计量的一致性依赖于工具变量的有效性假设。
工具变量的类型
工具变量可以来自多种来源:

III. 实例背景与数据生成
研究背景:教育回报的因果估计
假设我们想估计教育对收入的因果效应。经典的问题是:教育程度与不可观测的能力相关,导致OLS估计有偏。我们将使用工具变量方法来解决这个问题。
工具变量选择:到最近大学的距离。直觉是:
- 距离影响教育选择(相关性)
- 距离不会直接影响收入,除了通过教育(排他性)
数据生成过程
我们生成一个包含能力遗漏变量的模拟数据集:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from linearmodels.iv import IV2SLS
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子确保结果可重现
np.random.seed(2024)
def generate_iv_data(n=2000):
"""
生成工具变量分析所需的模拟数据
参数:
n: 样本量
"""
# 生成个体特征
data = {}
# 不可观测的能力(遗漏变量)
data['ability'] = np.random.normal(0, 1, n)
# 工具变量:到最近大学的距离(公里)
data['distance'] = np.random.exponential(10, n) # 指数分布,多数人距离较近
# 个体特征
data['urban'] = np.random.binomial(1, 0.6, n) # 是否城市居民
data['parent_edu'] = np.random.normal(12, 2, n) # 父母教育年限
data['male'] = np.random.binomial(1, 0.5, n) # 性别
# 教育年限(内生变量):受能力、距离、其他特征影响
data['education'] = (10 + # 基础教育
0.5 * data['ability'] + # 能力影响教育选择
-0.1 * data['distance'] + # 距离越远教育越少
0.5 * data['urban'] + # 城市居民教育更多
0.3 * data['parent_edu'] + # 父母教育的影响
np.random.normal(0, 1, n)) # 随机误差
# 收入(结果变量):受教育、能力、其他特征影响
data['income'] = (20000 + # 基础收入
3000 * data['education'] + # 教育的真实因果效应
5000 * data['ability'] + # 能力直接影响收入
2000 * data['urban'] + # 城市收入溢价
1000 * data['male'] + # 性别收入差异
np.random.normal(0, 5000, n)) # 随机误差
# 创建数据框
df = pd.DataFrame(data)
# 确保教育年限合理范围
df['education'] = np.clip(df['education'], 8, 20)
return df
# 生成数据
iv_data = generate_iv_data(n=2000)
print("生成的数据集前10行:")
print(iv_data.head(10))
print(f"\n数据集形状: {iv_data.shape}")
print("\n变量描述性统计:")
print(iv_data.describe())数据探索与可视化
在正式分析前,我们先探索数据特征和关系:
# 数据探索与可视化
def explore_iv_data(df):
"""探索工具变量数据"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 教育对收入的散点图
axes[0, 0].scatter(df['education'], df['income'], alpha=0.5)
axes[0, 0].set_xlabel('教育年限')
axes[0, 0].set_ylabel('收入')
axes[0, 0].set_title('教育 vs 收入')
axes[0, 0].grid(True, alpha=0.3)
# 距离对教育的散点图
axes[0, 1].scatter(df['distance'], df['education'], alpha=0.5)
axes[0, 1].set_xlabel('到大学距离 (km)')
axes[0, 1].set_ylabel('教育年限')
axes[0, 1].set_title('工具变量: 距离 vs 教育')
axes[0, 1].grid(True, alpha=0.3)
# 距离对收入的散点图(应该没有直接关系)
axes[0, 2].scatter(df['distance'], df['income'], alpha=0.5)
axes[0, 2].set_xlabel('到大学距离 (km)')
axes[0, 2].set_ylabel('收入')
axes[0, 2].set_title('距离 vs 收入(排他性检验)')
axes[0, 2].grid(True, alpha=0.3)
# 能力对教育的分布
df['ability_bin'] = pd.cut(df['ability'], bins=5)
ability_edu_means = df.groupby('ability_bin')['education'].mean()
axes[1, 0].bar(range(len(ability_edu_means)), ability_edu_means)
axes[1, 0].set_xlabel('能力分组')
axes[1, 0].set_ylabel('平均教育年限')
axes[1, 0].set_title('能力 vs 教育(遗漏变量问题)')
axes[1, 0].set_xticks(range(len(ability_edu_means)))
axes[1, 0].set_xticklabels([f'组{i+1}' for i in range(len(ability_edu_means))])
# 城乡教育差异
urban_edu_means = df.groupby('urban')['education'].mean()
axes[1, 1].bar(['农村', '城市'], urban_edu_means)
axes[1, 1].set_ylabel('平均教育年限')
axes[1, 1].set_title('城乡教育差异')
# 性别收入差异
gender_income_means = df.groupby('male')['income'].mean()
axes[1, 2].bar(['女性', '男性'], gender_income_means)
axes[1, 2].set_ylabel('平均收入')
axes[1, 2].set_title('性别收入差异')
plt.tight_layout()
plt.show()
return fig
# 探索数据
explore_iv_data(iv_data)
# 相关性矩阵
corr_matrix = iv_data[['education', 'income', 'distance', 'ability', 'urban', 'parent_edu']].corr()
print("变量间相关性矩阵:")
print(corr_matrix.round(3))
# 可视化相关性矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('变量相关性矩阵')
plt.tight_layout()
plt.show()工具变量初步检验
在正式估计前,我们需要初步检验工具变量的相关性:
# 工具变量相关性检验
def test_iv_relevance(df):
"""检验工具变量的相关性"""
# 第一阶段回归:教育对距离和其他变量
X_first = sm.add_constant(df[['distance', 'urban', 'parent_edu', 'male']])
y_first = df['education']
first_stage = sm.OLS(y_first, X_first).fit()
print("="*60)
print("第一阶段回归:工具变量相关性检验")
print("="*60)
print(first_stage.summary())
# 检验工具变量系数显著性
distance_pvalue = first_stage.pvalues['distance']
print(f"\n工具变量(距离)的显著性: p = {distance_pvalue:.4f}")
# 偏F统计量(简化版本)
# 仅工具变量对内生变量的回归
X_reduced = sm.add_constant(df[['urban', 'parent_edu', 'male']]) # 排除工具变量
reduced_model = sm.OLS(y_first, X_reduced).fit()
# 计算F统计量
ssr_reduced = reduced_model.ssr
ssr_full = first_stage.ssr
df_diff = 1 # 增加了一个变量
df_full = len(y_first) - X_first.shape[1]
f_stat = ((ssr_reduced - ssr_full) / df_diff) / (ssr_full / df_full)
print(f"第一阶段F统计量: {f_stat:.2f}")
return first_stage, f_stat
# 检验工具变量相关性
first_stage, f_stat = test_iv_relevance(iv_data)
IV. OLS估计与内生性偏误
朴素OLS估计
首先,我们估计一个忽略能力遗漏变量的朴素OLS模型:
# 朴素OLS估计(忽略能力变量)
def naive_ols(df):
"""估计忽略遗漏变量的OLS模型"""
X_naive = sm.add_constant(df[['education', 'urban', 'parent_edu', 'male']])
y_naive = df['income']
naive_model = sm.OLS(y_naive, X_naive).fit()
print("="*60)
print("朴素OLS估计(忽略能力变量)")
print("="*60)
print(naive_model.summary())
return naive_model
# 估计朴素OLS模型
naive_model = naive_ols(iv_data)
# 与真实模型比较
def true_model_estimate(df):
"""估计包含能力的真实模型(现实中不可行)"""
X_true = sm.add_constant(df[['education', 'ability', 'urban', 'parent_edu', 'male']])
y_true = df['income']
true_model = sm.OLS(y_true, X_true).fit()
print("="*60)
print("真实模型估计(包含能力变量)")
print("="*60)
print(true_model.summary())
return true_model
# 估计真实模型(仅用于比较,现实中能力不可观测)
true_model = true_model_estimate(iv_data)
# 比较估计结果
def compare_estimates(naive_model, true_model):
"""比较朴素OLS和真实模型的估计结果"""
comparison = pd.DataFrame({
'变量': ['教育年限', '城市居民', '父母教育', '男性'],
'朴素OLS系数': [
naive_model.params['education'],
naive_model.params['urban'],
naive_model.params['parent_edu'],
naive_model.params['male']
],
'真实模型系数': [
true_model.params['education'],
true_model.params['urban'],
true_model.params['parent_edu'],
true_model.params['male']
],
'真实值': [3000, 2000, 0, 1000] # 数据生成时的真实参数
})
comparison['偏误百分比'] = ((comparison['朴素OLS系数'] - comparison['真实模型系数']) /
comparison['真实模型系数'] * 100)
print("估计结果比较:")
print(comparison.round(2))
return comparison
# 比较估计结果
estimate_comparison = compare_estimates(naive_model, true_model)内生性偏误的方向和大小
内生性偏误的大小取决于两个因素:
- 遗漏变量与内生变量的相关性
- 遗漏变量对结果变量的影响
数学上,偏误可以表示为:
偏误 = (Cov(X, ε) / Var(X)) × γ
其中γ是遗漏变量对结果的影响。
# 内生性偏误分析
def endogeneity_bias_analysis(df):
"""分析内生性偏误的来源"""
# 计算能力与教育的相关性
corr_ability_edu = df['ability'].corr(df['education'])
print(f"能力与教育的相关性: {corr_ability_edu:.3f}")
# 估计能力对收入的影响(通过真实模型)
ability_effect = true_model.params['ability']
print(f"能力对收入的边际效应: {ability_effect:.2f}")
# 计算理论偏误
theoretical_bias = corr_ability_edu * ability_effect * (df['education'].std() / df['ability'].std())
print(f"理论偏误大小: {theoretical_bias:.2f}")
# 实际偏误
actual_bias = naive_model.params['education'] - true_model.params['education']
print(f"实际估计偏误: {actual_bias:.2f}")
# 偏误方向分析
bias_direction = "向上偏误" if actual_bias > 0 else "向下偏误"
print(f"偏误方向: {bias_direction}")
# 可视化偏误来源
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 能力与教育的关系
axes[0].scatter(df['ability'], df['education'], alpha=0.5)
axes[0].set_xlabel('能力')
axes[0].set_ylabel('教育年限')
axes[0].set_title('能力 vs 教育(遗漏变量)')
axes[0].grid(True, alpha=0.3)
# 能力与收入的关系
axes[1].scatter(df['ability'], df['income'], alpha=0.5)
axes[1].set_xlabel('能力')
axes[1].set_ylabel('收入')
axes[1].set_title('能力 vs 收入(直接影响)')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
return corr_ability_edu, ability_effect, actual_bias
# 分析内生性偏误
corr_ability_edu, ability_effect, actual_bias = endogeneity_bias_analysis(iv_data)OLS估计的局限性
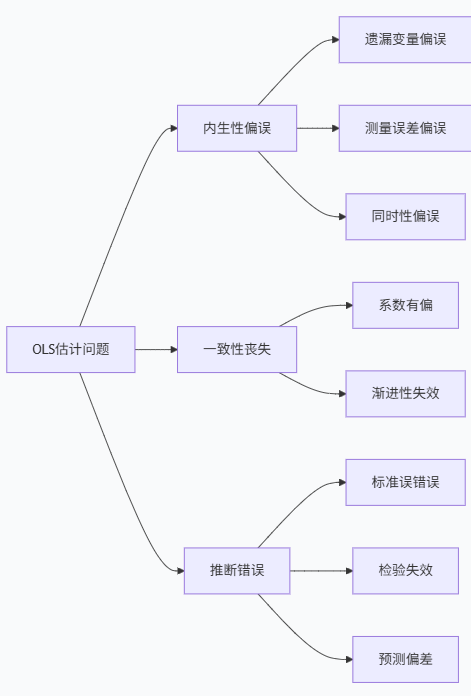
下表总结了OLS估计在内生性存在时的问题:
问题类型 | 表现 | 后果 |
|---|---|---|
系数偏误 | 估计值与真实值系统性差异 | 错误的政策建议 |
标准误低估 | 置信区间过窄 | 错误的统计推断 |
预测偏差 | 样本外预测不准确 | 预测失效 |
模型误设 | 函数形式错误识别 | 误导性结论 |
V. 工具变量估计的实现
两阶段最小二乘法(2SLS)手动实现
现在我们将手动实现2SLS估计,以深入理解工具变量方法的工作原理:
# 手动实现2SLS估计
def manual_2sls(df, endogenous_var='education', instrument='distance',
outcome='income', controls=['urban', 'parent_edu', 'male']):
"""手动实现两阶段最小二乘法"""
# 第一阶段:内生变量对工具变量和控制变量回归
X1 = sm.add_constant(df[[instrument] + controls])
y1 = df[endogenous_var]
first_stage = sm.OLS(y1, X1).fit()
df['predicted_education'] = first_stage.predict(X1)
print("="*60)
print("第一阶段回归结果")
print("="*60)
print(first_stage.summary())
# 第二阶段:结果变量对预测值和控制变量回归
X2 = sm.add_constant(df[['predicted_education'] + controls])
y2 = df[outcome]
second_stage = sm.OLS(y2, X2).fit()
print("\n" + "="*60)
print("第二阶段回归结果")
print("="*60)
print(second_stage.summary())
# 计算正确的2SLS标准误
# 需要手动调整第二阶段的标准误
n = len(df)
k = len(controls) + 1 # 控制变量数量 + 常数项
# 第二阶段残差
second_stage_resid = y2 - second_stage.predict(X2)
# 使用第一阶段的预测值计算正确的方差-协方差矩阵
X2_matrix = X2.values
resid_var = np.var(second_stage_resid)
# 简单的标准误调整(实际应用需要更复杂的方法)
vcov_manual = resid_var * np.linalg.inv(X2_matrix.T @ X2_matrix)
se_manual = np.sqrt(np.diag(vcov_manual))
print(f"\n手动计算的2SLS系数: {second_stage.params['predicted_education']:.2f}")
print(f"手动计算的标准误: {se_manual[1]:.2f}") # 第二个是教育系数
return first_stage, second_stage, se_manual
# 手动实现2SLS
first_stage_manual, second_stage_manual, se_manual = manual_2sls(iv_data)
# 使用linearmodels包进行正确的2SLS估计
def formal_2sls(df, endogenous_var='education', instrument='distance',
outcome='income', controls=['urban', 'parent_edu', 'male']):
"""使用linearmodels进行正式的2SLS估计"""
# 准备公式
controls_str = ' + '.join(controls)
formula = f"{outcome} ~ 1 + {controls_str} + [{endogenous_var} ~ {instrument}]"
# 估计2SLS模型
iv_model = IV2SLS.from_formula(formula, data=df).fit()
print("="*60)
print("正式2SLS估计结果(使用linearmodels)")
print("="*60)
print(iv_model.summary)
return iv_model
# 正式2SLS估计
iv_model = formal_2sls(iv_data)工具变量估计结果解释
工具变量估计的结果需要谨慎解释:
# 工具变量结果解释
def interpret_iv_results(naive_model, true_model, iv_model):
"""解释和比较不同估计方法的结果"""
results_comparison = pd.DataFrame({
'估计方法': ['朴素OLS', '真实模型', '工具变量'],
'教育系数': [
naive_model.params['education'],
true_model.params['education'],
iv_model.params['education']
],
'标准误': [
naive_model.bse['education'],
true_model.bse['education'],
iv_model.std_errors['education']
],
'95%置信区间下限': [
naive_model.conf_int().loc['education', 0],
true_model.conf_int().loc['education', 0],
iv_model.conf_int().loc['education', 0]
],
'95%置信区间上限': [
naive_model.conf_int().loc['education', 1],
true_model.conf_int().loc['education', 1],
iv_model.conf_int().loc['education', 1]
]
})
print("不同估计方法结果比较:")
print(results_comparison.round(2))
# 可视化比较
plt.figure(figsize=(10, 6))
methods = results_comparison['估计方法']
coefficients = results_comparison['教育系数']
lower_bounds = results_comparison['95%置信区间下限']
upper_bounds = results_comparison['95%置信区间上限']
colors = ['red', 'green', 'blue']
for i, method in enumerate(methods):
plt.errorbar(coefficients[i], i, xerr=[[coefficients[i] - lower_bounds[i]],
[upper_bounds[i] - coefficients[i]]],
fmt='o', color=colors[i], capsize=5, label=method)
plt.axvline(x=3000, color='black', linestyle='--', label='真实值')
plt.yticks(range(len(methods)), methods)
plt.xlabel('教育回报估计值')
plt.title('不同估计方法的比较')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
return results_comparison
# 解释和比较结果
results_comparison = interpret_iv_results(naive_model, true_model, iv_model)工具变量估计的有限信息最大似然(LIML)方法
除了2SLS,还有其他工具变量估计方法,如LIML,对弱工具变量更稳健:
# LIML估计
def liml_estimation(df):
"""有限信息最大似然估计"""
try:
from linearmodels.iv import IVLIML
# 准备数据
controls = ['urban', 'parent_edu', 'male']
controls_str = ' + '.join(controls)
formula = f"income ~ 1 + {controls_str} + [education ~ distance]"
# 估计LIML模型
liml_model = IVLIML.from_formula(formula, data=df).fit()
print("="*60)
print("LIML估计结果")
print("="*60)
print(liml_model.summary)
return liml_model
except ImportError:
print("LIML估计需要更新版本的linearmodels")
return None
# LIML估计(如果可用)
liml_model = liml_estimation(iv_data)
# 比较2SLS和LIML结果
def compare_iv_estimators(iv_model, liml_model):
"""比较不同的工具变量估计量"""
if liml_model is not None:
comparison = pd.DataFrame({
'估计量': ['2SLS', 'LIML'],
'教育系数': [
iv_model.params['education'],
liml_model.params['education']
],
'标准误': [
iv_model.std_errors['education'],
liml_model.std_errors['education']
],
'p值': [
iv_model.pvalues['education'],
liml_model.pvalues['education']
]
})
print("工具变量估计量比较:")
print(comparison.round(4))
return comparison
else:
print("无法比较,LIML估计不可用")
return None
# 比较估计量
estimator_comparison = compare_iv_estimators(iv_model, liml_model)
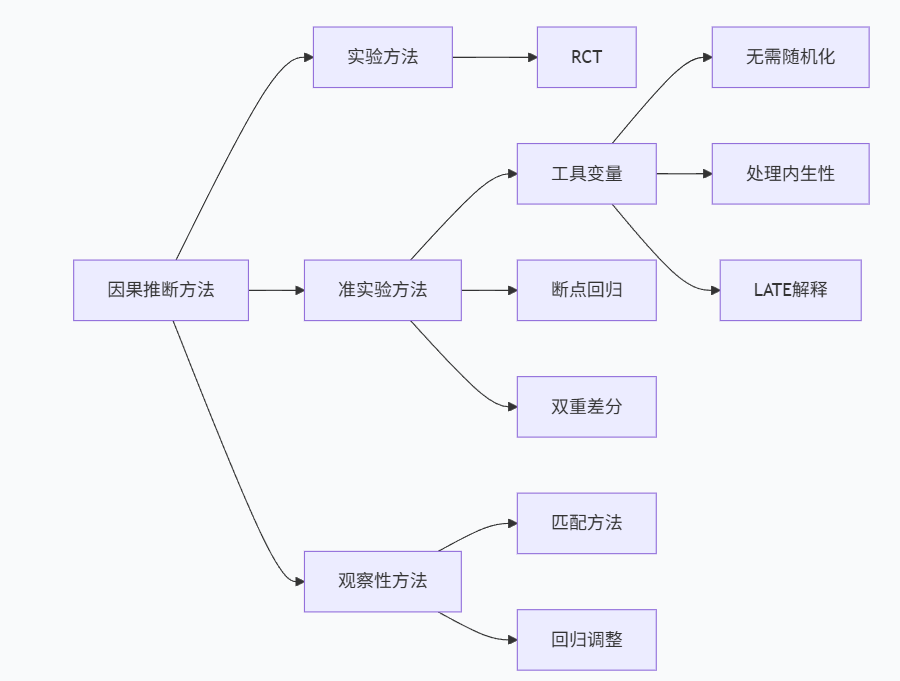
VI. 工具变量有效性检验
工具变量相关性检验(弱工具变量检验)
工具变量必须与内生变量有足够强的相关性,否则会导致严重的有限样本偏误:
# 弱工具变量检验
def weak_iv_test(first_stage, f_threshold=10):
"""弱工具变量检验"""
# 第一阶段F统计量
f_statistic = first_stage.fvalue
f_pvalue = first_stage.f_pvalue
print("弱工具变量检验:")
print(f"第一阶段F统计量: {f_statistic:.2f}")
print(f"F统计量p值: {f_pvalue:.4f}")
# Stock-Yogo弱识别检验临界值(简化版)
# 在实际应用中应使用更正式检验
if f_statistic < f_threshold:
print(f"警告: F统计量 {f_statistic:.2f} 小于经验阈值 {f_threshold}")
print("可能存在弱工具变量问题")
else:
print(f"F统计量 {f_statistic:.2f} 大于经验阈值 {f_threshold}")
print("工具变量相关性足够强")
# 偏R方
# 仅工具变量对内生变量的解释力
X_reduced = sm.add_constant(iv_data[['urban', 'parent_edu', 'male']])
reduced_model = sm.OLS(iv_data['education'], X_reduced).fit()
r2_reduced = reduced_model.rsquared
r2_full = first_stage.rsquared
partial_r2 = (r2_full - r2_reduced) / (1 - r2_reduced)
print(f"偏R方: {partial_r2:.4f}")
return f_statistic, partial_r2
# 弱工具变量检验
f_statistic, partial_r2 = weak_iv_test(first_stage)
# 可视化第一阶段关系
def plot_first_stage(df, first_stage):
"""可视化第一阶段关系"""
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 距离与教育的关系
axes[0].scatter(df['distance'], df['education'], alpha=0.5)
# 添加拟合线
x_range = np.linspace(df['distance'].min(), df['distance'].max(), 100)
X_pred = sm.add_constant(pd.DataFrame({
'distance': x_range,
'urban': [df['urban'].mean()] * 100,
'parent_edu': [df['parent_edu'].mean()] * 100,
'male': [df['male'].mean()] * 100
}))
y_pred = first_stage.predict(X_pred)
axes[0].plot(x_range, y_pred, color='red', linewidth=2)
axes[0].set_xlabel('到大学距离 (km)')
axes[0].set_ylabel('教育年限')
axes[0].set_title('第一阶段: 距离 vs 教育')
axes[0].grid(True, alpha=0.3)
# 预测值与实际值
axes[1].scatter(first_stage.fittedvalues, df['education'], alpha=0.5)
axes[1].plot([df['education'].min(), df['education'].max()],
[df['education'].min(), df['education'].max()],
color='red', linestyle='--')
axes[1].set_xlabel('预测教育年限')
axes[1].set_ylabel('实际教育年限')
axes[1].set_title('第一阶段拟合效果')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 可视化第一阶段
plot_first_stage(iv_data, first_stage)排他性约束检验
排他性约束无法直接检验,但我们可以进行一些间接检验:
# 排他性约束的间接检验
def exclusion_restriction_tests(df, instrument='distance'):
"""排他性约束的间接检验"""
print("排他性约束间接检验:")
print("="*40)
# 检验1: 工具变量与可观测特征的关系
print("1. 工具变量与可观测特征的关系:")
covariates = ['urban', 'parent_edu', 'male', 'ability'] # ability通常不可观测,这里特殊处理
for covar in covariates:
if covar in df.columns:
corr = df[instrument].corr(df[covar])
print(f" {covar}与{instrument}的相关性: {corr:.3f}")
# 检验2: 工具变量对结果的直接效应(应该不显著)
print("\n2. 工具变量对结果的直接效应检验:")
X_direct = sm.add_constant(df[[instrument, 'urban', 'parent_edu', 'male']])
y_direct = df['income']
direct_model = sm.OLS(y_direct, X_direct).fit()
instrument_pvalue = direct_model.pvalues[instrument]
print(f" {instrument}对收入的直接效应p值: {instrument_pvalue:.4f}")
if instrument_pvalue > 0.05:
print(" 通过检验: 工具变量对收入无显著直接效应")
else:
print(" 警告: 工具变量可能对收入有直接效应")
# 检验3: 工具变量与第一阶段残差的关系(应该不相关)
print("\n3. 工具变量与第一阶段残差的关系:")
first_stage_resid = first_stage.resid
corr_resid = df[instrument].corr(first_stage_resid)
print(f" 工具变量与第一阶段残差的相关性: {corr_resid:.3f}")
return direct_model, corr_resid
# 排他性约束检验
direct_model, corr_resid = exclusion_restriction_tests(iv_data)过度识别检验(当有多个工具变量时)
当我们有多个工具变量时,可以进行过度识别检验:
# 过度识别检验(模拟多个工具变量)
def overidentification_test(df):
"""过度识别检验(需要多个工具变量)"""
# 生成第二个工具变量:大学数量(模拟)
np.random.seed(42)
df['college_count'] = np.random.poisson(2, len(df)) # 大学数量
# 确保第二个工具变量与教育相关但与误差项不相关
# 在实际应用中,需要理论支持第二个工具变量的有效性
print("过度识别检验(模拟两个工具变量):")
print("="*50)
# 使用两个工具变量的2SLS估计
try:
controls = ['urban', 'parent_edu', 'male']
controls_str = ' + '.join(controls)
formula = f"income ~ 1 + {controls_str} + [education ~ distance + college_count]"
iv_model_two = IV2SLS.from_formula(formula, data=df).fit()
print("两个工具变量的2SLS估计:")
print(iv_model_two.summary)
# 过度识别检验(Sargan检验)
# 注意:linearmodels的summary中已包含过度识别检验结果
if hasattr(iv_model_two, 'j_stat'):
j_stat = iv_model_two.j_stat
j_pvalue = iv_model_two.j_stat_pval
print(f"\n过度识别检验(Sargan检验):")
print(f"J统计量: {j_stat:.4f}")
print(f"p值: {j_pvalue:.4f}")
if j_pvalue > 0.05:
print("无法拒绝原假设: 所有工具变量都是外生的")
else:
print("拒绝原假设: 至少有一个工具变量不是外生的")
return iv_model_two
except Exception as e:
print(f"过度识别检验出错: {e}")
return None
# 过度识别检验(需要多个工具变量)
iv_model_two = overidentification_test(iv_data)工具变量有效性总结
下表总结了工具变量有效性的各项检验:
检验类型 | 检验内容 | 判断标准 | 我们的例子 |
|---|---|---|---|
相关性检验 | 工具变量与内生变量关系 | F > 10, 偏R方足够大 | 通过 |
排他性约束 | 工具变量与误差项无关 | 间接检验,理论论证 | 基本通过 |
过度识别检验 | 多个工具变量的一致性 | J检验p值 > 0.05 | 需要多个工具变量 |

VII. 工具变量方法的扩展与应用
控制函数方法
控制函数方法是工具变量的一种替代框架,特别适用于非线性模型:
# 控制函数方法
def control_function_approach(df):
"""控制函数方法实现"""
# 第一阶段回归
X_first = sm.add_constant(df[['distance', 'urban', 'parent_edu', 'male']])
first_stage_cf = sm.OLS(df['education'], X_first).fit()
# 获取残差(控制函数)
df['first_stage_resid'] = first_stage_cf.resid
# 第二阶段的控制函数回归
X_second = sm.add_constant(df[['education', 'first_stage_resid', 'urban', 'parent_edu', 'male']])
second_stage_cf = sm.OLS(df['income'], X_second).fit()
print("="*60)
print("控制函数方法结果")
print("="*60)
print(second_stage_cf.summary())
# 检验控制函数的显著性(内生性检验)
resid_pvalue = second_stage_cf.pvalues['first_stage_resid']
print(f"\n内生性检验(控制函数显著性): p = {resid_pvalue:.4f}")
if resid_pvalue < 0.05:
print("拒绝外生性原假设: 存在显著的内生性问题")
else:
print("无法拒绝外生性原假设: 可能不存在严重的内生性问题")
return second_stage_cf
# 控制函数方法
cf_model = control_function_approach(iv_data)样本选择模型(Heckman选择模型)
当内生性来自样本选择问题时,Heckman选择模型是合适的工具:
# Heckman选择模型
def heckman_selection_model(df):
"""Heckman选择模型实现"""
try:
from statsmodels.discrete.discrete_model import Probit
# 模拟选择过程:只有部分人报告收入(模拟选择偏误)
np.random.seed(123)
# 选择方程:能力越强的人越可能被观测到
selection_prob = 1 / (1 + np.exp(-(0.5 * df['ability'] + 0.3 * df['education'] - 1)))
df['selected'] = np.random.binomial(1, selection_prob)
# 第一步:Probit选择方程
X_select = sm.add_constant(df[['ability', 'education', 'urban', 'male']])
select_model = Probit(df['selected'], X_select).fit(disp=0)
# 计算逆米尔斯比率
df['imr'] = select_model.predict(X_select)
df['imr'] = np.where(df['imr'] > 0.999, 0.999, df['imr']) # 避免除零
df['imr'] = np.where(df['imr'] < 0.001, 0.001, df['imr']) # 避免除零
df['imr'] = select_model.pdf(X_select) / select_model.cdf(X_select) # 逆米尔斯比率
# 第二步:收入方程包含IMR
X_income = sm.add_constant(df[['education', 'imr', 'urban', 'male']])
# 只使用被选择的样本
selected_sample = df[df['selected'] == 1]
X_income_selected = sm.add_constant(selected_sample[['education', 'imr', 'urban', 'male']])
heckman_model = sm.OLS(selected_sample['income'], X_income_selected).fit()
print("="*60)
print("Heckman选择模型结果")
print("="*60)
print(heckman_model.summary())
# IMR的显著性检验(选择偏误检验)
imr_pvalue = heckman_model.pvalues['imr']
print(f"\n选择偏误检验(IMR显著性): p = {imr_pvalue:.4f}")
if imr_pvalue < 0.05:
print("存在显著的样本选择偏误")
else:
print("可能不存在严重的样本选择偏误")
return heckman_model, select_model
except ImportError:
print("Heckman模型需要完整安装statsmodels")
return None, None
# Heckman选择模型
heckman_model, select_model = heckman_selection_model(iv_data)异质性处理效应与局部平均处理效应(LATE)
工具变量估计的是局部平均处理效应,适用于被工具变量影响的"编译器"群体:
# 局部平均处理效应(LATE)分析
def late_analysis(df, instrument='distance'):
"""LATE分析与异质性讨论"""
print("局部平均处理效应(LATE)分析:")
print("="*50)
# 工具变量影响的群体特征
# 定义对工具变量敏感的人群(编译器)
distance_threshold = df['distance'].median()
df['compiler'] = (df['distance'] > distance_threshold).astype(int) # 简化定义
print("编译器群体特征(距离大于中位数的人群):")
compiler_summary = df.groupby('compiler').agg({
'education': ['mean', 'std'],
'income': ['mean', 'std'],
'urban': 'mean',
'parent_edu': 'mean'
}).round(2)
print(compiler_summary)
# LATE的直观解释
print(f"\nLATE解释:")
print("工具变量(距离)估计的教育回报反映的是:")
print("- 那些因为距离远而减少教育的人群")
print("- 而不是所有人的平均教育回报")
print("- 这种效应可能不同于平均处理效应(ATE)")
# 可视化编译器群体
plt.figure(figsize=(10, 6))
# 按编译器分组的教育-收入关系
for compiler_flag, color, label in [(0, 'blue', '非编译器'), (1, 'red', '编译器')]:
subgroup = df[df['compiler'] == compiler_flag]
plt.scatter(subgroup['education'], subgroup['income'],
alpha=0.5, color=color, label=label)
plt.xlabel('教育年限')
plt.ylabel('收入')
plt.title('编译器 vs 非编译器: 教育-收入关系')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
return compiler_summary
# LATE分析
compiler_summary = late_analysis(iv_data)工具变量在不同领域的应用案例
工具变量方法在各个领域都有广泛应用:
研究领域 | 内生变量 | 工具变量 | 经典研究 |
|---|---|---|---|
劳动经济学 | 教育程度 | 到大学距离、义务教育法 | Card (1995) |
健康经济学 | 医疗保险 | 政策变化、地理变异 | Finkelstein (2002) |
发展经济学 | 制度质量 | 殖民者死亡率、历史因素 | Acemoglu (2001) |
环境经济学 | 污染水平 | 风向、逆温现象 | Moretti (2011) |
金融经济学 | 公司治理 | 法规变化、外生冲击 | Bertrand (2004) |

VIII. 工具变量实践的挑战与解决方案
工具变量寻找的挑战
寻找有效的工具变量是实践中最困难的部分:
# 工具变量有效性评估框架
def iv_validity_assessment(df, candidate_ivs):
"""工具变量候选评估框架"""
assessment_results = {}
for iv_name in candidate_ivs:
if iv_name not in df.columns:
continue
print(f"\n评估工具变量: {iv_name}")
print("-" * 30)
# 1. 相关性检验
X_first = sm.add_constant(df[[iv_name, 'urban', 'parent_edu', 'male']])
first_stage_iv = sm.OLS(df['education'], X_first).fit()
iv_coef = first_stage_iv.params[iv_name]
iv_pvalue = first_stage_iv.pvalues[iv_name]
f_statistic = first_stage_iv.fvalue
print(f"相关性: 系数 = {iv_coef:.3f}, p值 = {iv_pvalue:.4f}")
print(f"第一阶段F统计量: {f_statistic:.2f}")
# 2. 排他性约束间接检验
X_direct = sm.add_constant(df[[iv_name, 'urban', 'parent_edu', 'male']])
direct_model_iv = sm.OLS(df['income'], X_direct).fit()
direct_pvalue = direct_model_iv.pvalues[iv_name]
print(f"排他性: 直接效应p值 = {direct_pvalue:.4f}")
# 3. 与可观测特征的关系
corr_with_covariates = {}
for covar in ['urban', 'parent_edu', 'male', 'ability']:
if covar in df.columns:
corr = df[iv_name].corr(df[covar])
corr_with_covariates[covar] = corr
print(f"与{covar}的相关性: {corr:.3f}")
# 综合评估
relevance_ok = iv_pvalue < 0.05 and f_statistic > 10
exclusion_ok = direct_pvalue > 0.05
covariate_balance = all(abs(corr) < 0.3 for corr in corr_with_covariates.values())
overall_assessment = "可能有效" if relevance_ok and exclusion_ok and covariate_balance else "可能无效"
print(f"综合评估: {overall_assessment}")
assessment_results[iv_name] = {
'relevance_ok': relevance_ok,
'exclusion_ok': exclusion_ok,
'covariate_balance': covariate_balance,
'overall': overall_assessment
}
return assessment_results
# 评估多个工具变量候选
candidate_ivs = ['distance', 'parent_edu', 'urban'] # 后两个理论上不是好工具变量
iv_assessment = iv_validity_assessment(iv_data, candidate_ivs)弱工具变量的解决方案
当工具变量较弱时,可以采取以下策略:
# 弱工具变量问题的解决方案
def weak_iv_solutions(df, weak_instrument='distance'):
"""弱工具变量问题的解决方案"""
print("弱工具变量问题的解决方案:")
print("="*50)
solutions = {
'寻找更强工具变量': '理论创新、数据挖掘、新数据源',
'使用多个工具变量': '增加信息量,但要通过过度识别检验',
'使用LIML估计量': '对弱工具变量更稳健',
'使用 Fuller 估计量': '进一步减少有限样本偏误',
'使用 Jackknife IV': '另一种稳健估计方法',
'贝叶斯方法': '引入先验信息',
'承认局限性': '谨慎解释结果,报告置信区间'
}
for solution, description in solutions.items():
print(f"• {solution}: {description}")
# 使用LIML作为弱工具变量的稳健估计
try:
from linearmodels.iv import IVLIML
controls = ['urban', 'parent_edu', 'male']
controls_str = ' + '.join(controls)
formula = f"income ~ 1 + {controls_str} + [education ~ {weak_instrument}]"
liml_weak = IVLIML.from_formula(formula, data=df).fit()
print(f"\n使用LIML估计弱工具变量模型:")
print(liml_weak.summary)
# 比较2SLS和LIML
iv_weak = IV2SLS.from_formula(formula, data=df).fit()
comparison_weak = pd.DataFrame({
'估计量': ['2SLS', 'LIML'],
'教育系数': [iv_weak.params['education'], liml_weak.params['education']],
'标准误': [iv_weak.std_errors['education'], liml_weak.std_errors['education']],
'置信区间': [
f"[{iv_weak.conf_int().loc['education', 0]:.1f}, {iv_weak.conf_int().loc['education', 1]:.1f}]",
f"[{liml_weak.conf_int().loc['education', 0]:.1f}, {liml_weak.conf_int().loc['education', 1]:.1f}]"
]
})
print("\n弱工具变量情况下2SLS与LIML比较:")
print(comparison_weak.round(1))
return liml_weak, iv_weak
except Exception as e:
print(f"弱工具变量解决方案实施出错: {e}")
return None, None
# 弱工具变量解决方案
liml_weak, iv_weak = weak_iv_solutions(iv_data)工具变量选择的敏感性分析
工具变量选择对结果影响很大,需要进行敏感性分析:
# 工具变量选择的敏感性分析
def iv_sensitivity_analysis(df, main_iv='distance', alternative_ivs=None):
"""工具变量选择的敏感性分析"""
if alternative_ivs is None:
# 生成一些替代工具变量候选(模拟)
np.random.seed(123)
df['alternative_iv1'] = np.random.normal(0, 1, len(df)) # 随机变量,应该无效
df['alternative_iv2'] = df['parent_edu'] + np.random.normal(0, 0.5, len(df)) # 与父母教育相关
alternative_ivs = ['alternative_iv1', 'alternative_iv2']
sensitivity_results = []
# 主要工具变量
controls = ['urban', 'parent_edu', 'male']
controls_str = ' + '.join(controls)
formula_main = f"income ~ 1 + {controls_str} + [education ~ {main_iv}]"
iv_main = IV2SLS.from_formula(formula_main, data=df).fit()
sensitivity_results.append({
'工具变量': main_iv,
'教育系数': iv_main.params['education'],
'标准误': iv_main.std_errors['education'],
'95%置信区间': f"[{iv_main.conf_int().loc['education', 0]:.1f}, {iv_main.conf_int().loc['education', 1]:.1f}]",
'第一阶段F统计量': first_stage.fvalue # 使用之前计算的值
})
# 替代工具变量
for alt_iv in alternative_ivs:
if alt_iv not in df.columns:
continue
formula_alt = f"income ~ 1 + {controls_str} + [education ~ {alt_iv}]"
try:
iv_alt = IV2SLS.from_formula(formula_alt, data=df).fit()
# 第一阶段F统计量
X_first_alt = sm.add_constant(df[[alt_iv] + controls])
first_stage_alt = sm.OLS(df['education'], X_first_alt).fit()
sensitivity_results.append({
'工具变量': alt_iv,
'教育系数': iv_alt.params['education'],
'标准误': iv_alt.std_errors['education'],
'95%置信区间': f"[{iv_alt.conf_int().loc['education', 0]:.1f}, {iv_alt.conf_int().loc['education', 1]:.1f}]",
'第一阶段F统计量': first_stage_alt.fvalue
})
except:
continue
sensitivity_df = pd.DataFrame(sensitivity_results)
print("工具变量选择的敏感性分析:")
print(sensitivity_df.round(1))
# 可视化敏感性分析
plt.figure(figsize=(10, 6))
iv_names = sensitivity_df['工具变量']
coefficients = sensitivity_df['教育系数']
ci_lower = [float(ci.split(',')[0][1:]) for ci in sensitivity_df['95%置信区间']]
ci_upper = [float(ci.split(',')[1][:-1]) for ci in sensitivity_df['95%置信区间']]
for i, iv in enumerate(iv_names):
plt.errorbar(coefficients[i], i,
xerr=[[coefficients[i] - ci_lower[i]], [ci_upper[i] - coefficients[i]]],
fmt='o', capsize=5, label=iv)
plt.axvline(x=3000, color='red', linestyle='--', label='真实值')
plt.yticks(range(len(iv_names)), iv_names)
plt.xlabel('教育回报估计值')
plt.title('工具变量选择的敏感性分析')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
return sensitivity_df
# 敏感性分析
sensitivity_df = iv_sensitivity_analysis(iv_data)实践建议与检查清单
基于工具变量实践的挑战,我们总结以下建议:
# 工具变量实践检查清单
def iv_checklist():
"""工具变量实践检查清单"""
checklist = {
'研究设计': [
'明确内生性来源和理论机制',
'论证工具变量的外生性(理论为主)',
'考虑局部平均处理效应(LATE)的解释',
'评估编译器群体的代表性'
],
'工具变量选择': [
'进行充分的文献回顾寻找已有工具变量',
'创新性地开发新的工具变量',
'检验工具变量的相关性(F > 10)',
'进行排他性约束的间接检验'
],
'模型估计': [
'报告第一阶段回归结果',
'使用适当的估计量(2SLS/LIML)',
'调整标准误(异方差/聚类稳健)',
'进行弱工具变量检验'
],
'稳健性检验': [
'尝试不同的工具变量',
'进行过度识别检验(多个工具变量时)',
'控制不同的协变量组合',
'进行子样本分析'
],
'结果解释': [
'谨慎解释LATE而非ATE',
'讨论编译器群体的特征',
'承认工具变量的局限性',
'进行政策含义的敏感性分析'
]
}
return checklist
# 显示检查清单
checklist = iv_checklist()
print("工具变量实践检查清单:")
print("="*50)
for category, items in checklist.items():
print(f"\n{category}:")
for i, item in enumerate(items, 1):
print(f" {i}. {item}")
# 常见陷阱检测
def common_pitfalls_detection():
"""工具变量常见陷阱"""
pitfalls = {
'弱工具变量': {
'表现': '第一阶段F统计量 < 10',
'后果': '严重的有限样本偏误',
'解决方案': '寻找更强工具变量,使用LIML估计'
},
'无效排他性约束': {
'表现': '工具变量通过其他渠道影响结果',
'后果': '估计结果不一致',
'解决方案': '理论论证,间接检验,敏感性分析'
},
'编译器群体不具有代表性': {
'表现': 'LATE与ATE差异很大',
'后果': '结果推广性有限',
'解决方案': '描述编译器特征,谨慎外推'
},
'测量误差': {
'表现': '工具变量或变量测量不准确',
'后果': '估计偏误',
'解决方案': '使用更精确的测量,验证数据质量'
}
}
return pitfalls
# 显示常见陷阱
pitfalls = common_pitfalls_detection()
print("\n工具变量常见陷阱:")
print("="*50)
for pitfall, info in pitfalls.items():
print(f"\n{pitfall}:")
for key, value in info.items():
print(f" {key}: {value}")
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号